前言
理解链表概念及实现原理。
1.链表定义
【1】概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
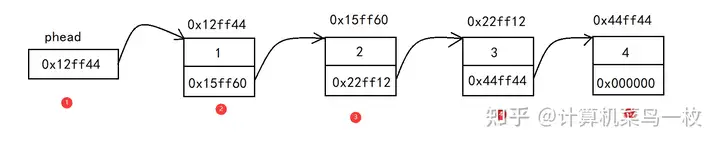
【2】组成:由一系列节点(Node)通过指针连接而成,从一个头节点(Head)开始,头节点作为链表的入口点,它包含了对第一个节点的引用。最后一个节点的指针指向一个空值(NULL),表示链表的结束。

【3】存储:链表在内存中的存储方式则是随机存储(见缝插针),每一个节点分布在内存的不同位置,依靠指针关联起来。(只要有足够的内存空间,就能为链表分配内存)
【4】优缺点:相对于顺序储存(例如数组):
- 优点:链表的插入操作更快( O(1) ),无需预先分配内存空间
- 缺点:失去了随机读取的优点(需要从头节点开始依次遍历,直到找到目标节点。),内存消耗较大(每个节点都需要存储指向下一个节点的指针)。
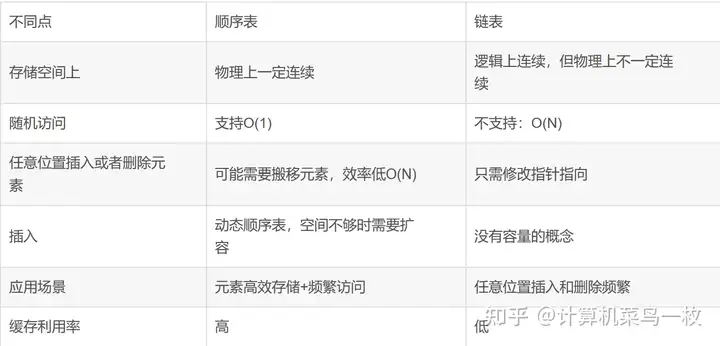
【5】对比:
- 链表是通过节点把离散的数据链接成一个表,通过对节点的插入和删除操作从而实现对数据的存取。而数组是通过开辟一段连续的内存来存储数据,这是数组和链表最大的区别。
- 数组的每个成员对应链表的节点,成员和节点的数据类型可以是标准的 C 类型或者是 用户自定义的结构体。
- 数组有起始地址和结束地址,而链表是一个圈,没有头和尾之分, 但是为了方便节点的插入和删除操作会人为的规定一个根节点。
【5】分类:链表一般有单向链表,双向链表,循环链表,带头链表这四种形式。
常用的两种结构:
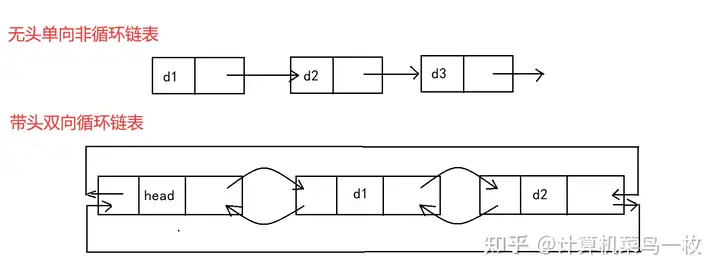
1. 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
2. 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单。
2.链表的实现
2.1链表的创建
// 定义链表节点结构 struct Node { int data; // 数据 struct Node* next; // 指向下一个节点的指针 }; // 创建链表函数 struct Node* createLinkedList(int arr[], int n) { struct Node* head = NULL; // 头节点指针 struct Node* tail = NULL; // 尾节点指针 // 遍历数组,为每个元素创建一个节点,并加入链表 for (int i = 0; i < n; i++) { // 创建新节点并为其分配内存 struct Node* newNode = (struct Node*)malloc(sizeof(struct Node)); if (newNode == NULL) { printf("内存分配失败."); return NULL; } // 设置新节点的数据 newNode->data = arr[i]; newNode->next = NULL; // 如果链表为空,将新节点设置为头节点和尾节点 if (head == NULL) { head = tail = newNode; } // 如果链表非空,将新节点加入到尾部,并更新尾节点指针 else { tail->next = newNode; tail = newNode; } } return head; }
2.2链表的插入
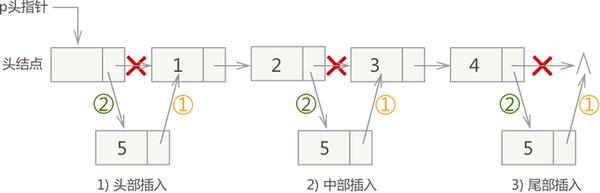
同顺序表一样,向链表中增添元素,根据添加位置不同,可分为以下 3 种情况:
- 插入到链表的头部,作为首元节点;
- 插入到链表中间的某个位置;
- 插入到链表的最末端,作为链表中最后一个结点;
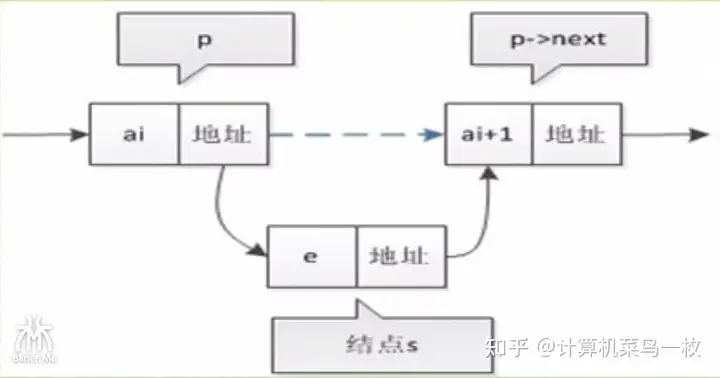
// 在链表中插入节点 void insert(struct Node** headRef, int position, int value) { // 创建新节点并为其分配内存 struct Node* newNode = (struct Node*)malloc(sizeof(struct Node)); if (newNode == NULL) { printf("内存分配失败。\n"); return; } newNode->data = value; // 如果要插入的位置是链表的头部或链表为空 if (*headRef == NULL || position == 0) { newNode->next = *headRef; *headRef = newNode; return; } struct Node* current = *headRef; int count = 1; // 找到要插入位置的前一个节点 while (current->next != NULL && count < position) { current = current->next; count++; } // 在指定位置插入节点 newNode->next = current->next; current->next = newNode; }
代码解惑:{struct Node** headRef}
在链表节点删除中使用双指针的原因是为了更改指针的指向。
在单指针情况下,如果我们想要删除当前节点,我们无法直接修改前一个节点的 next 指针,因为我们只有当前节点的指针。所以我们需要一个额外的指针来保存前一个节点的地址,这个额外的指针就是双指针中的 prev。
通过双指针的方式,我们可以在遍历链表的过程中同时记录前一个节点和当前节点的位置。当找到要删除的节点时,我们可以使用 prev 指针修改前一个节点的 next 指针,将其指向当前节点的下一个节点,从而实现删除操作。同时,我们还可以使用 current 指针来释放要删除的节点的内存。
2.3链表的查询
// 在链表中查询节点 struct Node* search(struct Node* head, int value) { struct Node* current = head; while (current != NULL) { if (current->data == value) { return current; // 返回匹配的节点地址 } current = current->next; } return NULL; // 若没有找到匹配节点,则返回NULL }
2.4链表的删除
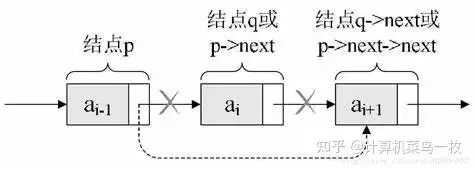
// 在链表中删除节点 void delete(struct Node** headRef, int value) { struct Node* current = *headRef; struct Node* prev = NULL; // 处理头节点为目标节点的情况 if (current != NULL && current->data == value) { *headRef = current->next; free(current); return; } // 遍历链表找到要删除的节点 while (current != NULL && current->data != value) { prev = current; current = current->next; } // 如果找到了目标节点,则删除它 if (current != NULL) { prev->next = current->next; free(current); } }
2.5链表的释放
// 释放链表内存 void freeList(struct Node* head) { struct Node* current = head; struct Node* next; while (current != NULL) { next = current->next; free(current); current = next; } }
2.6链表的遍历
void printLinkedList(struct Node* head) { struct Node* current = head; while (current != NULL) { printf("%d ", current->data); current = current->next; } printf("\n"); }
3.双向链表
【1】起源:
单链表的结点中只有一个指向其后继的指针,使得单链表要访问某个结点的前驱结点时,只能从头开始遍历,访问后驱结点的复杂度为O(1),访问前驱结点的复杂度为O(n)。(例如,若实际问题中需要频繁地查找某个结点的前驱结点,使用单链表存储数据显然没有优势,因为单链表的强项是从前往后查找目标元素,不擅长从后往前查找元素。)为了克服上述缺点,引入了双链表。
【2】定义:
双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。

从图 1 中可以看到,双向链表中各节点包含以下 3 部分信息(如图 2 所示):
- 指针域:用于指向当前节点的直接前驱节点;
- 数据域:用于存储数据元素。
- 指针域:用于指向当前节点的直接后继节点;

typedef struct line{ struct line * prior; //指向直接前趋 int data; struct line * next; //指向直接后继 }Line;
【3】特点:
1.每次在插入或删除某个节点时, 需要处理四个节点的引用, 而不是两个, 实现起来要困难一些;
2.相对于单向链表, 必然占用内存空间更大一些;
3.既可以从头遍历到尾, 又可以从尾遍历到头;
4.双向链表的实现
4.1双向链表的创建
需要注意的是,与单链表不同,双链表创建过程中,每创建一个新节点都要与其前驱节点建立两次联系,分别是:
- 将新节点的 prior 指针指向直接前驱节点;
- 将直接前驱节点的 next 指针指向新节点;
Line* initLine(Line* head) { Line* list = NULL; head = (Line*)malloc(sizeof(Line));//创建链表第一个结点(首元结点) head->prior = NULL; head->next = NULL; head->data = 1; list = head; for (int i = 2; i <= 5; i++) { //创建并初始化一个新结点 Line* body = (Line*)malloc(sizeof(Line)); body->prior = NULL; body->next = NULL; body->data = i; //直接前趋结点的next指针指向新结点 list->next = body; //新结点指向直接前趋结点 body->prior = list; list = list->next; } return head; }
4.2双向链表的添加
根据数据添加到双向链表中的位置不同,可细分为以下 3 种情况:
1,添加至表头

2,添加至中间位置
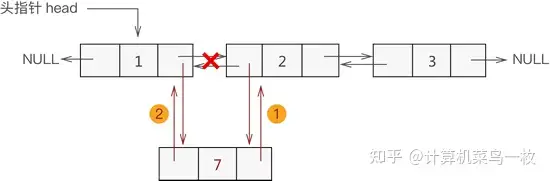
3,添加至表尾
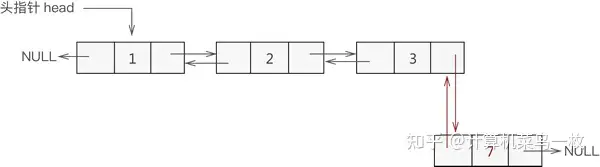
Line* insertLine(Line* head, int data, int add) { //新建数据域为data的结点 Line* temp = (Line*)malloc(sizeof(Line)); temp->data = data; temp->prior = NULL; temp->next = NULL; //插入到链表头,要特殊考虑 if (add == 1) { temp->next = head; head->prior = temp; head = temp; } else { int i; Line* body = head; //找到要插入位置的前一个结点 for (i = 1; i < add - 1; i++) { body = body->next; //只要 body 不存在,表明插入位置输入错误 if (!body) { printf("插入位置有误!\n"); return head; } } //判断条件为真,说明插入位置为链表尾,实现第 2 种情况 if (body && (body->next == NULL)) { body->next = temp; temp->prior = body; } else { //第 2 种情况的具体实现 body->next->prior = temp; temp->next = body->next; body->next = temp; temp->prior = body; } } return head; }
4.3双向链表的删除
和添加结点的思想类似,在双向链表中删除目标结点也分为 3 种情况。
1,删除表头结点
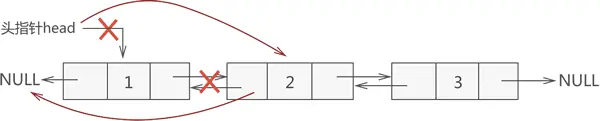
2,删除表中结点

3,删除表尾结点

//删除结点的函数,data为要删除结点的数据域的值 Line* delLine(Line* head, int data) { Line* temp = head; while (temp) { if (temp->data == data) { //删除表头结点 if (temp->prior == NULL) { head = head->next; if (head) { head->prior = NULL; temp->next = NULL; } free(temp); return head; } //删除表中结点 if (temp->prior && temp->next) { temp->next->prior = temp->prior; temp->prior->next = temp->next; free(temp); return head; } //删除表尾结点 if (temp->next == NULL) { temp->prior->next = NULL; temp->prior = NULL; free(temp); return head; } } temp = temp->next; } printf("表中没有目标元素,删除失败\n"); return head; }
4.4双向链表的查询
//head为原双链表,elem表示被查找元素 int selectElem(line * head,int elem){ //新建一个指针t,初始化为头指针 head line * t=head; int i=1; while (t) { if (t->data==elem) { return i; } i++; t=t->next; } //程序执行至此处,表示查找失败 return -1; }
4.5双向链表的更改
//更新函数,其中,add 表示要修改的元素,newElem 为新数据的值 void amendElem(Line* p, int oldElem, int newElem) { Line* temp = p; int find = 0; //找到要修改的目标结点 while (temp) { if (temp->data == oldElem) { find = 1; break; } temp = temp->next; } //成功找到,则进行更改操作 if (find == 1) { temp->data = newElem; return; } //查找失败,输出提示信息 printf("链表中未找到目标元素,更改失败\n"); }
5.双向循环链表的简单实现
#include <stdio.h> #include <stdlib.h> // 定义双向循环链表结构体 struct Node { int data; struct Node* prev; struct Node* next; }; // 在链表末尾插入节点 void insert(struct Node** headRef, int data) { // 创建新节点 struct Node* newNode = (struct Node*)malloc(sizeof(struct Node)); newNode->data = data; if (*headRef == NULL) { // 如果链表为空,让新节点成为唯一一个节点 newNode->prev = newNode; newNode->next = newNode; *headRef = newNode; } else { // 如果链表不为空,在链表末尾插入新节点 struct Node* lastNode = (*headRef)->prev; newNode->prev = lastNode; newNode->next = *headRef; lastNode->next = newNode; (*headRef)->prev = newNode; } } // 在链表中删除指定值的节点 void delete(struct Node** headRef, int data) { if (*headRef == NULL) { // 链表为空,无需删除 return; } struct Node* current = *headRef; // 查找要删除的节点 while (current->data != data && current->next != *headRef) { current = current->next; } if (current->data == data) { // 找到要删除的节点 if (current->next == current) { // 要删除的节点是唯一一个节点 *headRef = NULL; } else { // 从链表中删除节点 current->prev->next = current->next; current->next->prev = current->prev; if (*headRef == current) { // 如果要删除的节点是头节点,更新头指针 *headRef = current->next; } } free(current); } } // 打印链表 void printList(struct Node* head) { if (head != NULL) { struct Node* current = head; do { printf("%d ", current->data); current = current->next; } while (current != head); } printf("\n"); } // 测试代码 int main() { struct Node* head = NULL; insert(&head, 1); insert(&head, 2); insert(&head, 3); printf("原始链表:"); printList(head); // 输出:1 2 3 delete(&head, 2); printf("删除节点后的链表:"); printList(head); // 输出:1 3 return 0; }
参看链接:https://zhuanlan.zhihu.com/p/648341058