爬虫
爬虫:scrapy架构介绍、scrapy解析数据、settings相关配置,提高爬取效率、持久化方案、全站爬取cnblogs文章
[toc] ### scrapy架构介绍 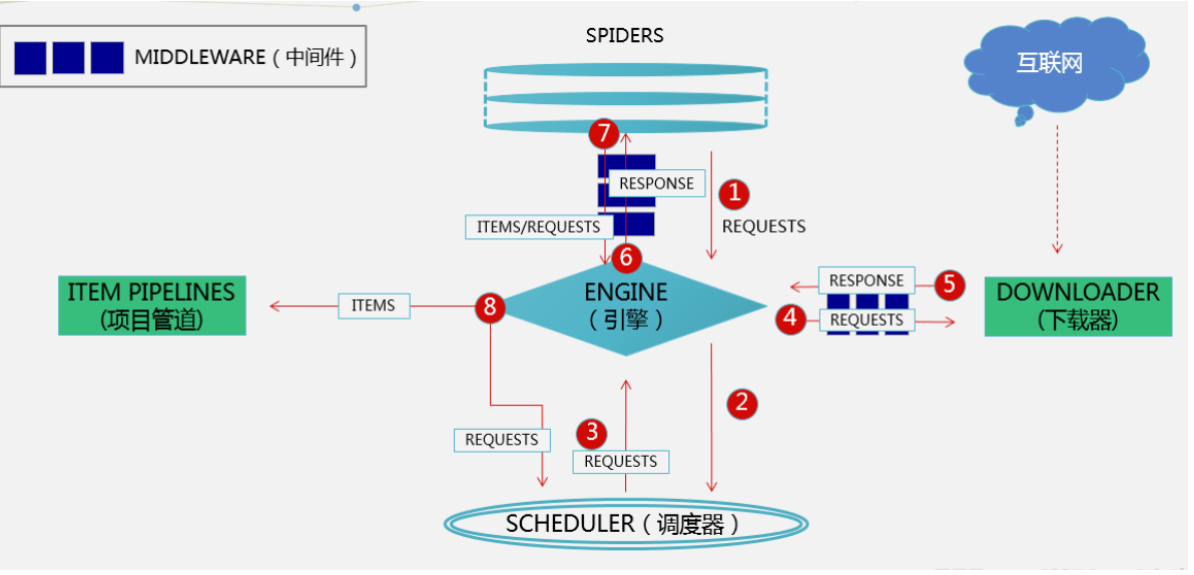 ```python # 引擎(EGINE) 引擎负责控制系统所 ......
如何利用python做爬虫?
Python爬虫在许多情况下是非常有用的,爬虫可以帮助自动化地从互联网上获取大量数据。这些数据可以是产品信息、新闻文章、社交媒体内容、股票数据等通过爬虫可以减少人工收集和整理数据的工作量,提高效率。在软件开发中,可以使用爬虫来进行自动化的功能测试、性能测试或页面链接检查等。 正常做爬虫都是有一定的模 ......
学习爬虫4,selenium基础入门
模拟浏览器测试工具 一般来说 动态就可以用selenium url简化 只抓关键信息 将一些标识自己的内容都可以删除如 webdriver 模拟浏览器 import导入 他可以有页面交互 如find_element_by_id这样去定位id,xpath,name等 模拟输入文字内容 search_b ......
python练习-爬虫(续)
接下来就是查询数据了。 # 识别图片中的文字 #image = Image.open('captcha.png') image = Image.open('G:\Python爬虫\captcha.png') code = pytesseract.image_to_string(image) # 从用 ......
【前端开发】好用的可视化爬虫工具
EasySpider 一个可视化爬虫软件,可以无代码图形化的设计和执行爬虫任务 git地址如下 https://github.com/NaiboWang/EasySpider 下载软件地址 https://github.com/NaiboWang/EasySpider/releases 实例效果图 ......
爬虫如何通过HTML和CSS采集数据的 ?
爬虫可以应用于各种应用场景,包括数据分析、市场研究、舆情监测、竞争报、价格比较、内容聚合等。对于需要大量数据的业务和研究领域,爬虫能够提供宝贵的支持。 爬虫可以按照设定的规则从多个网进行批量数据抓取,比人工手动方式更高效。量数据,并支持后续的数据分析和决策。 爬虫可以通过解析HTML和CSS来采集数 ......
爬虫框架和库有多重要?
爬虫框架和库在网络数据提取和分析中非常重它们为开发人员提供了工具和功能,使他们能够更轻松地从互联网上抓取数据。爬虫框架和库通常提供了高效的网络请求、数据解析和存储机制,简化了爬取过程。 使用爬虫框架库有以下几个重要优势: 快速开发: 爬虫框架和库提供了封装好的功能和方法,减少了开发人员编写底层代码的 ......
Python爬虫高并发爬取数据
高效爬虫可以在较短的时间内获取更多的数据,提高数据的采集速度。这对于需要大量数据支撑的数据分析、机器学习、人工智能等任务非常重要。高效爬虫可以获取更多的原始数据,并允许更精准的数据清洗和处理。这样可以提高数据的质量和关联性,使得后续的分析和挖掘工作更加准确和有价值。 高效的爬虫在数据采集和信息获取的 ......
Python爬虫之数据解析技术
Python爬虫需要数据解析的原因是,爬取到的网页内容通常是包含大量标签和结构的HTML或XML文档。这些文档中包含所需数据的信息,但是需要通过解析才能提取出来,以便后续的处理和分析。 以下是一些使用数据解析的原因: 数据提取:网页内容通常包含大量的无关信息和嵌套结构,数据解析可以帮助我们从中提取出 ......
成为python爬虫工程师需要哪些知识?
爬虫(Web crawler)是一种自动化程序,用于从互联网上抓取、解析和提取网页数据。它模拟浏览器行为,通过发送HTTP请求获取网页内容,并通过解析网页源代码或DOM结构,提取所需的信息。以python爬虫为例,作为一名合格的工程师需要具备那些专业技能? Python爬虫的难度可以因个人经验和项目 ......
【爬虫案例】用Python爬大麦网任意城市的近期演出活动!
[toc] # 一、爬取目标 大家好,我是[@马哥python说](https://www.zhihu.com/people/13273183132) ,一枚10年程序猿。 今天分享一期python爬虫案例,爬取目标是大麦网近期演出活动:[- 大麦搜索](https://search.damai.c ......
python练习-爬虫
场景: 1、网址hppt://xxx.yyy.zzz.cn2、打开网页后显示 : 3、填上姓名 身份证和验证码,点击查询后,返回查询结果。 4、页面有cookie。 方案一: 程序中嵌入浏览器根据网址打开得到页面, 然后程序读取记录自动填写数据, 程序截取验证码图片,然后解析,并且填入验证码 然后程 ......
1.爬虫基础
# 目录 - [目录](#目录) - [环境](#环境) - [静态网页爬虫基础](#静态网页爬虫基础) - [xpath](#xpath) - [pymysql](#pymysql) # 环境 - 工具:pycharm - python解释器 - requests库 - lxml - 数据库连接p ......
Python和c语言爬虫如何选择?
Python是最受欢迎的爬虫语言之一,因为它易于学习和使用,有大量的库和框架可供选择。JavaScript通常用于Web爬虫,因为它可以直接在浏览器中运行,可以轻松地从动态网站中提取数据。java是一种广泛使用的语言,它有很多强大的库和框架,可以用于爬虫。具体用哪个语言做爬虫完全取决于你的项目以及个 ......
Python爬虫需要那些步骤 ?
Python爬虫是一种自动化程序,可以通过网络爬取网页上的数据。Python爬虫可以用于各种用途,例如数据挖掘、搜索引擎优化、市场研究等。Python爬虫通常使用第三方库,例如BeautifulSoup、Scrapy、Requests等,这些库可以帮助开发者轻松地获取网页上的数据。Python爬虫的 ......
爬虫小试牛刀(爬取学校通知公告)
> - - 完成抓取并解析DGUT通知公告12页数据,并提交excel文件格式数据,数据需要包含日期标题,若能够实现将详情页主体内容与发布人信息数据也一并抓取更佳 > - 提交内容:Excel数据文件 ## 爬虫开始 首先看到页面呈现规则的各个方框,这意味着它们之间的一定是一样的 此处该有图 [![ ......
Python爬虫(二):写一个爬取壁纸网站图片的爬虫(图片下载,词频统计,思路)
好家伙,写爬虫 代码: import requests import re import os from collections import Counter import xlwt # 创建Excel文件 workbook = xlwt.Workbook(encoding='utf-8') wor ......
禁止爬虫抓取网站
Robots.txt 测试工具,是一款在线验证 robots.txt 规则的工具。通过 Robots.txt 测试工具,可以检测在 robots.txt 设定的规则下,网站指定的页面是否允许网络爬虫访问。 本工具支持的搜索引擎爬虫有: 百度爬虫 - BaiduSpider Google 爬虫 - G ......
Python爬虫与数据可视化(前程无忧网)
## 1、前言 最初我写过一篇相同的文章发表到了CSDN中,因为写的比较早,2019年吧,8万多访问量,所以后来也有很多网友反馈各种问题,包括网站反爬、数据爬取失败、网络异常等等,所以那篇文章也经过了多次的修改。 不过目前因为CSDN规则更改,爬虫类文章因违反社区规定被下架了,然后我也很久没有去管了 ......
CentOS服务器爬虫怎么样 ?
在CentOS系统上进行爬虫与在其他平台上进行爬虫基本上没有太大的区别。CentOS是一种流行的Linux发行版,可以提供稳定和安全的服务器环境。学习CentOS系统管理知识将有助于您更好地处理服务器配置,优化性能,并确保爬虫任务的正常运行。 CentOS系统可以用来运行爬虫程序,但具体效果取决于爬 ......
学习python爬虫需要掌握哪些库?
Python爬虫是指使用Python编写的程序,用来自动化地获取互联网上的数据。通过爬取网站的HTML内容,并解析和提取所需的数据,可以实现自动化地收集、分析和处理大量的在线数据。 学习Python爬虫需要掌握以下几个核心库: Requests:用于发送、BeautifulSoup:用于解析HTML ......
selenium爬虫运行慢如何解决?
Selenium作为一个强大的自动化工具,可用于编写爬虫程序,尽管Selenium在处理动态网页上非常强大,但对于静态网页爬简单数据提取,使用轻量级库或工具可能更加上所述,Selenium作为一个灵活可定动化工具,在需要模拟用户行为、处理动态网页内容,并进行复杂交互的爬虫任务中是一种价值的选择。 那 ......
通过模仿学会Python爬虫(一):零基础上手
好家伙,爬虫来了 爬虫,这玩意,不会怎么办, 诶,先抄一份作业回来 1.别人的爬虫 Python爬虫史上超详细讲解(零基础入门,老年人都看的懂)_ChenBinBini的博客-CSDN博客 # -*- codeing = utf-8 -*- from bs4 import BeautifulSoup ......
Python3网络爬虫开发实战阅读笔记
## 基本库的使用 ### 网络请求库 #### urllib(HTTP/1.1) Python自带请求库,繁琐 基础使用:略 #### requests(HTTP/1.1) Python常用第三方请求库,便捷 基础使用:略 #### httpx(HTTP/2.0) Python第三方库,支持HTT ......
如何有效管理爬虫流量?
本文分享自天翼云开发者社区《如何有效管理爬虫流量?》,作者:刘****海 据国际知名金融广告服务平台提供商Dianomi的报告《2018 Robot traffic report》的数据,在互联网上人类流量仅仅占了48.2%,也就是说,一个页面的10000个点击里面,大约5100个来自机器人。在航旅 ......
selenium 爬虫难不难?
Selenium 爬虫相对于传统的 requests + BeautifulSoup 爬虫来说,难度确实会稍微高一些。主要原因是 Selenium 是一个自动化测试工具,它的主要功能是模拟用户在浏览器中的操作,而不是直接获取网页源代码。因此,使用 Selenium 爬虫需要掌握一定的前端知识,比如 ......
爬虫数据是如何收集和整理的?
爬虫数据的收集和整理通常包括以下步骤: 确定数据需求:确定要收集的信息类型、来源和范围。 网络爬取:使用编程工具(如Python的Scrapy、BeautifulSoup等)编写爬虫程序,通过HTTP请求获取网页内容,并提取所需数据。这可以通过解析HTML、XML或JSON等网页结构来实现。 数据清 ......
学习爬虫入门2,count反爬虫思路
浏览网页的过程 1.输入网址 2.浏览器向DNS服务商发起请求 3.找到对应服务器 4.服务器解析请求 5.服务器处理最终请求发回去 6.浏览器解析返回数据 7.展示给用户 爬虫策略 广度优先 深度优先 聚焦爬虫 BFS 从根节点开始 沿着树的宽度 深度优先 DFS 尽可能深的搜索树的分支 然后再返 ......