Article:
- 论文标题:Debunking Rumors on Twitter with Tree Transformer(利用树状Transformer模型揭露Twitter中的谣言)
- 论文作者:Jing Ma、Wei Gao
- 论文来源:2020,COLING
- 论文地址:https://www.semanticscholar.org/paper/Debunking-Rumors-on-Twitter-with-Tree-Transformer-Ma-Gao/4d0221d305c0ad4843c9431fbf7e799005d51a96
- 引用:Ma J, Gao W (2020) Debunking rumors on twitter with tree transformer. In: Proceedings of the 28th international conference on computational linguistics, pp 5455–5466
1 Introduction:
出发点:现有的基于会话的谣言检测技术要么严格遵循树的边,要么将特征学习过程中的所有帖子完全联系在一起。
创新点:本文提出一个新颖的基于树状Transformer的检测模型来更好地利用用户对话之间的交互,其中,帖子级自注意力机制对于聚合子树/子树间的立场起着关键作用。
例子:以 PLAN 模型为例子——一种帖子之间全连接的例子
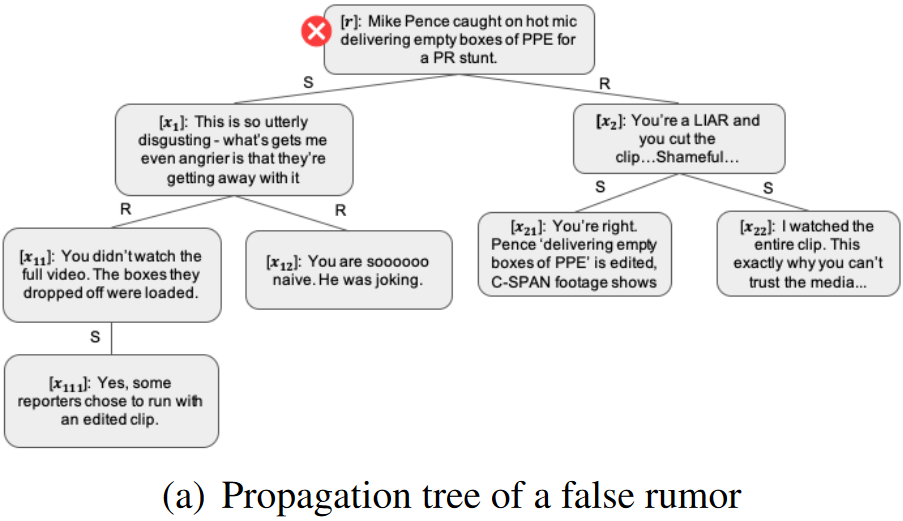
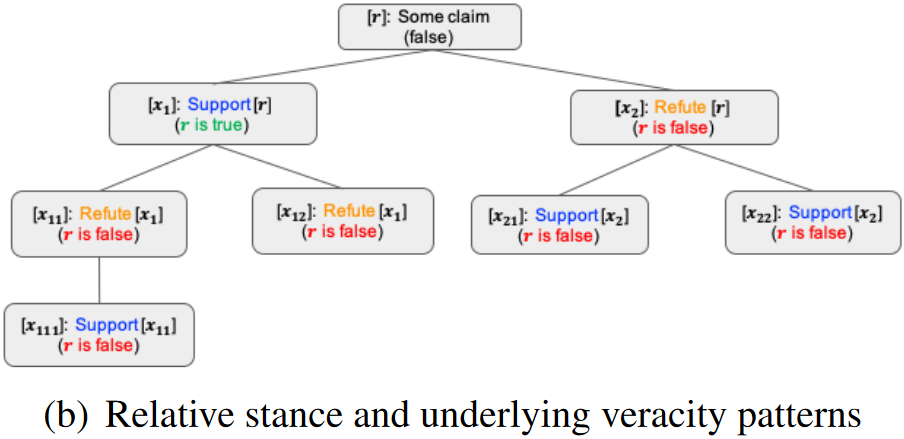

结论:Post 之间全连接的模型只适合浅层模型,并不适合深层模型,这是由于 Post 一般只和其 Parent 相关吗,全连接导致 Post 之间的错误连接加重。
2 Tree Transformer Model:
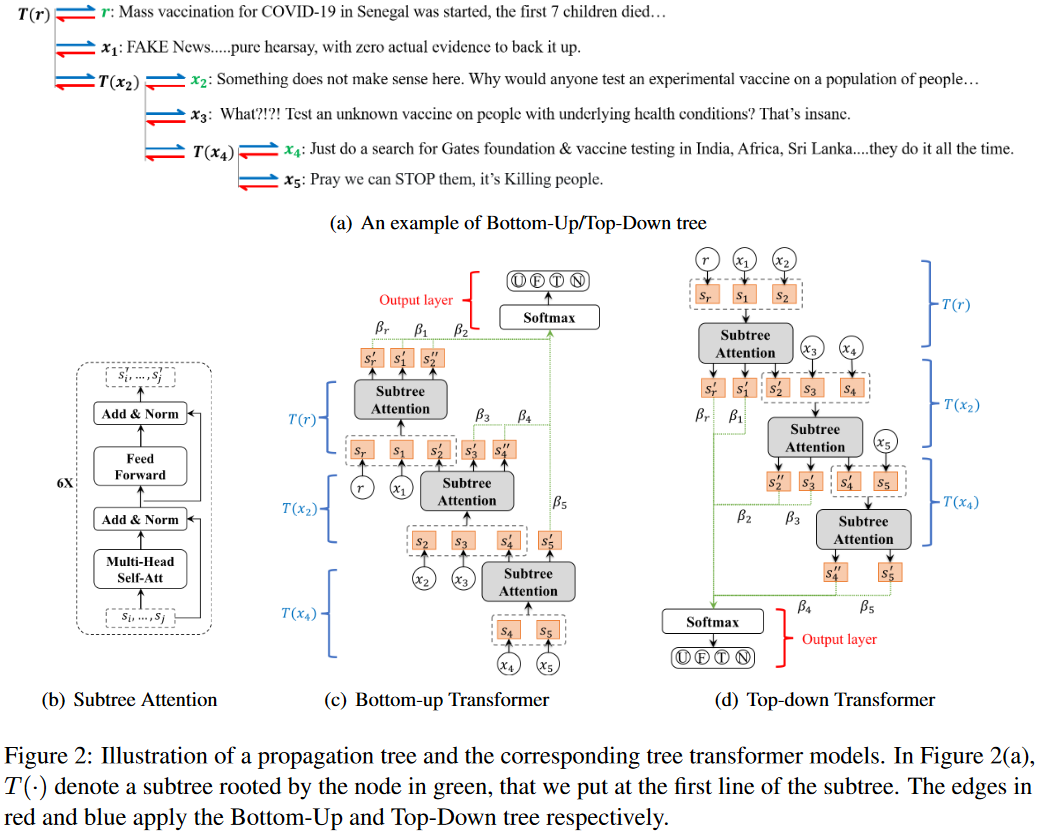
总体框架如下:
2.1 Token-Level Tweet Representation
Transformer encoder 框架:
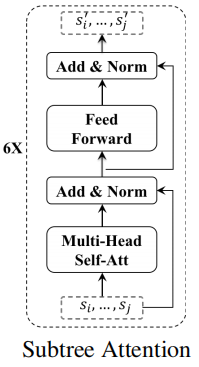
给定一条表示为word sequence 





其中,


其中,



其中





其中,
2.2 Post-Level Tweet Representation
作者的目标是交叉检查同一子树中的所有帖子,以增强表示学习,
因为:
(1)帖子通常很短,因此每个节点表达的立场与响应上下文密切相关;
(2)同一子树中的帖子直接指向子树根中表达的个人意见;
(3)通过比较同一子树中的所有回复帖子,可以获得一致的意见,从而降低错误信息的权重。
Bottom-Up Transformer
Figure 2(c)说明了本文的tree transformer结构,它cross-check从底部子树到上部子树的post。具体来说,给定一个有根于





其中,






Top-Down Transformer
Top-down transformer的方向与bottom-up transformer相反,沿着信息传播的方向,其架构如Figure 2 (d)所示。同样的,其学习到的表示也通过捕获立场和自我纠正上下文信息得到增强。
2.3 The overall Model
为了共同捕获整个树中表达的观点,我们利用一个注意力层来选择具有准确信息的重要帖子,这是基于细化的节点表示而获得的。这将产生:

其中,





其中,

此外,还有一种直接的方法可以将Bottom-Up transformer与Top-Down transformer的树表示连接起来,以获得更丰富的树表示,然后将其输入上述的
本文所有的模型都经过训练,以最小化预测的概率分布和地面真实值的概率分布之间的平方误差:

其中





3 Experiments:
Dataset
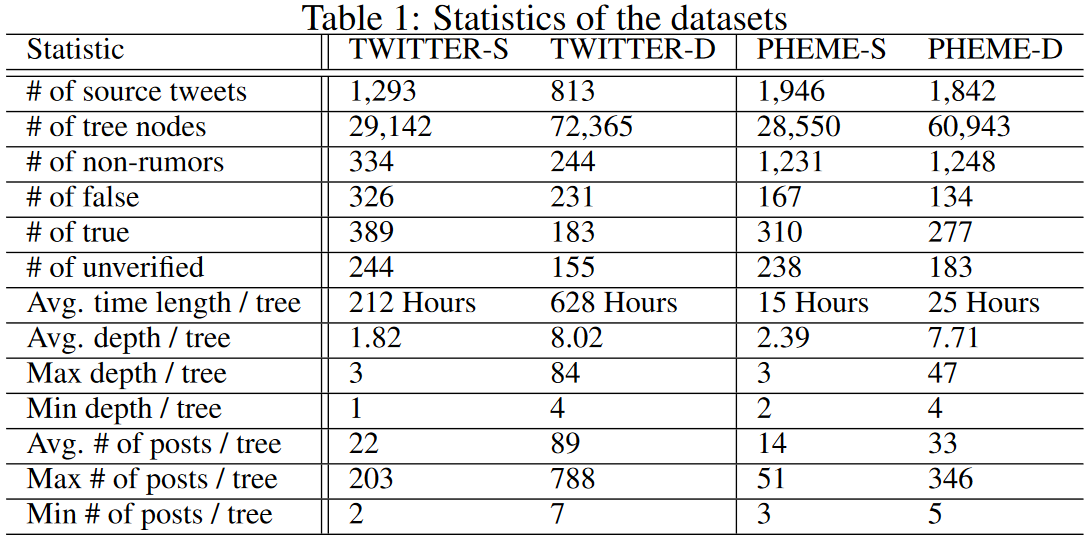
使用TWITTER和PHEME数据集进行实验,按照传播树深度将两个数据集划分为TWITTER-S (PHEME-S)和TWITTER-D (PHEME-D)一共4个数据集,下表展示数据集的统计情况:
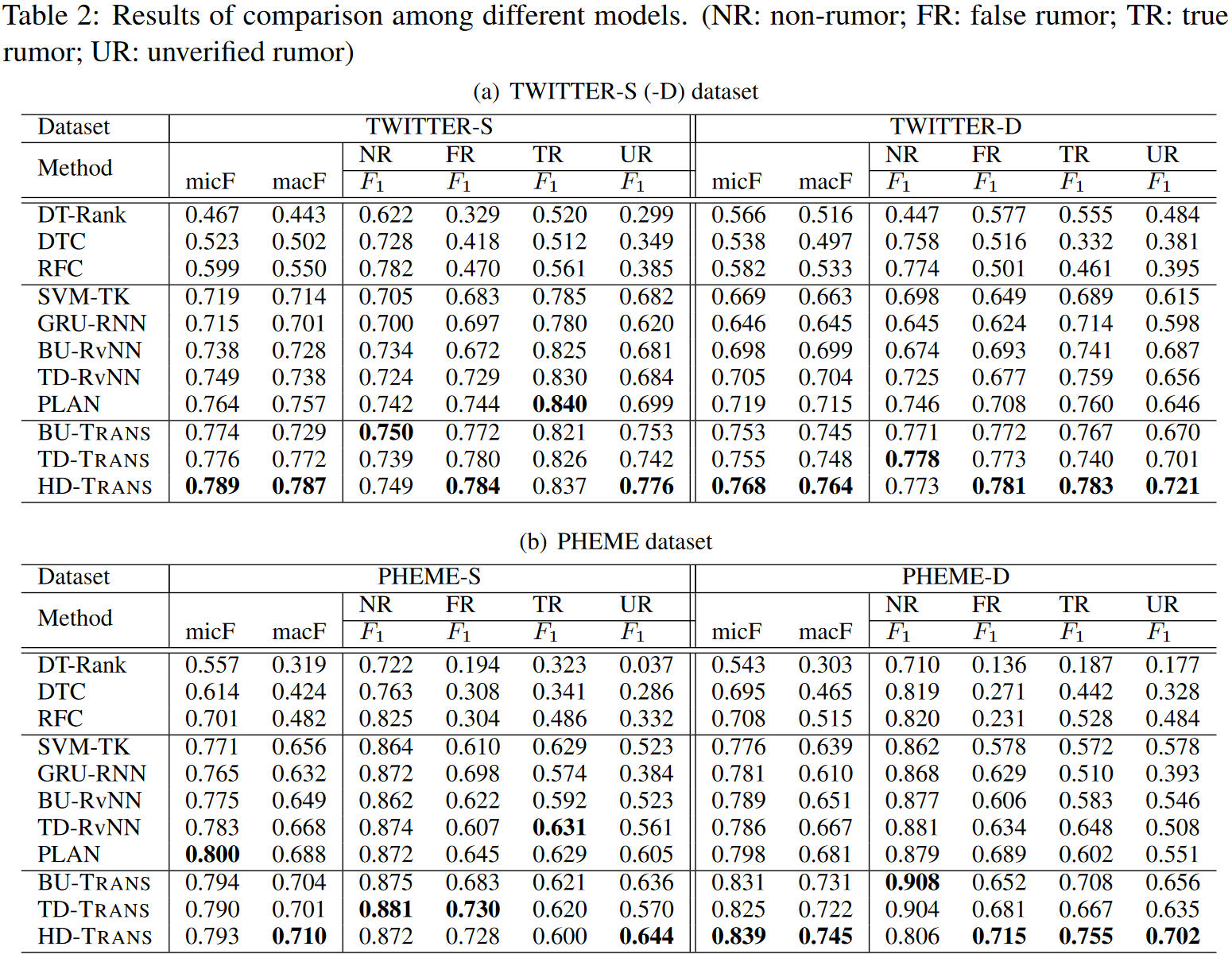
Experiment
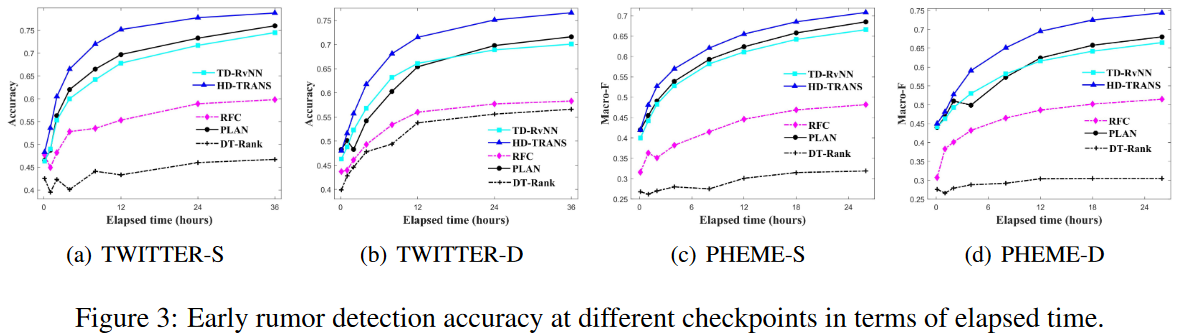
Early Rumor Detection Performance
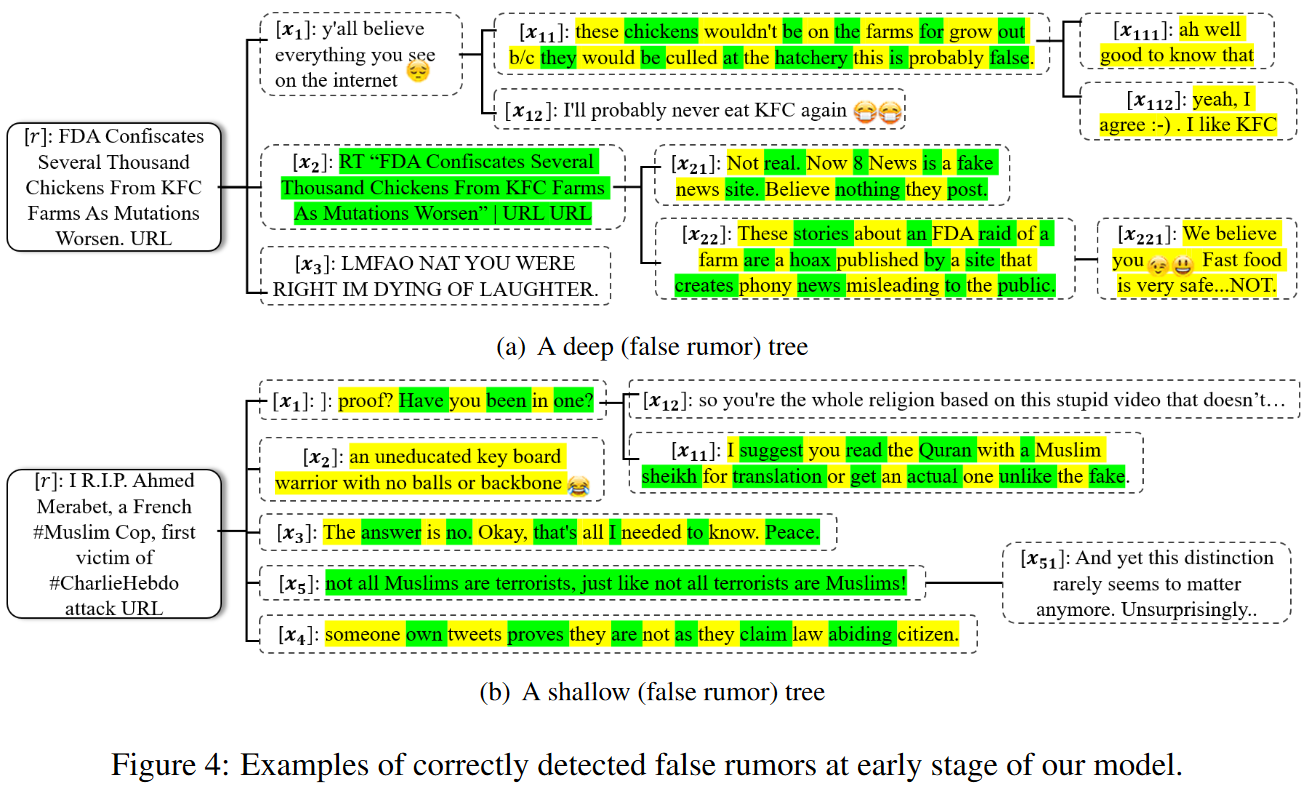
4 Conclusion:
在本文中,通过分析,建模传播结构是检测谣言的关键因素,作者提出了三种 Transformer 变体,以进一步增强针对树结构建模的表示学习:自底向上 Transformer、自顶向下 Transformer和混合模型。四个基准数据集的结果证实了本文的方法优于其他模型,特别是在具有更复杂的响应上下文的树上得到了很好的结果。
对于未来的工作,除了响应关系之外,还可能包括其他类型的边/关系,以增强谣言检测,例如:“朋友/关注者”、“引用”、“提到” 等。还可以尝试调查图像或视频等非文本信息在谣言检测有效性方面的作用。