由浅入深:Stable-Diffusion 原理解析01 —— 基本概念的介绍
由于实习工作需要,最近一段时间的学习,自己也对 Stable-Diffusion 有了一些基础的理解,在学习和阅读论文的过程中,发现信息比较碎片化,于是决定产出一个 SD 原理的系列解析。
本系列相比于本人之前的代码阅读系列没那么“硬核”,内容也更容易理解一些。
希望各位大佬多多批评指正。
什么是Stable Diffusion?它是怎么组成的?

Stable Diffusion就是一种深度学习模型(后文简称SD模型)。它是由几个模块组成的
-
Text Encoder
这一部分的主要功能是,把提示词(prompt)转化成计算机能够理解的一种数学表示,是一种 Clip 模型,在后面系列中会重点介绍 Clip 模型,在这里只是做一个功能上的诠释。自己书写的提示词最终生成图像,肯定离不开AI对提示词的“理解”,而 Clip 就是一种能够支持多模态输入的模型。
需要注意的是,在谷歌的 Imagen 模型中提到,语言模型比图像生成模型更关键
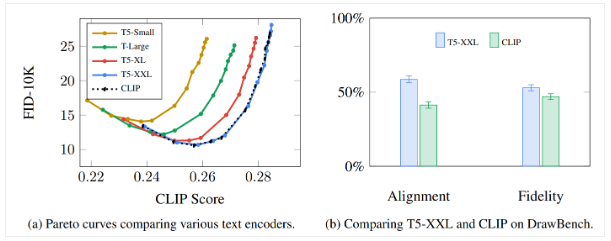
Imagen 是由谷歌公司提出的一种 txt2img 的 Diffusion 模型,它和Stable在根本原理上大体一致,都是一种扩散(Diffusion)模型。他们原理上的区别在后面再详细说,从小白的角度,SD模型是开源的,也就是大家都可以看到代码,而Imagen是闭源的,我们无法了解更详细的信息。
-
Image Information Creator
在收获了提示词等引导信息后,SD模型需要根据这些提示词抽象成的数学信息,来对一张随机的图(它看起来只是纯随机的像素点,也称为噪声 noise )进行一些“改变”,最终得到一个结果。而这个“改变的过程”,我们使用的方法是“扩散(Diffusion)”,这也就是这个模型名字的由来。当然,这个过程实际上很复杂,也有许多优化的地方,在后面会更详细的介绍。
图像信息创建器(Image Information Creator)是整个SD模型的核心所在,也是它的性能比其他模型更好的关键所在。从技术角度来说,它由UNet神经网络和调度算法组成,在后面文章中也会进行详细介绍。而本文的关键也是介绍图像的改变(扩散)过程。
-
Image Decoder
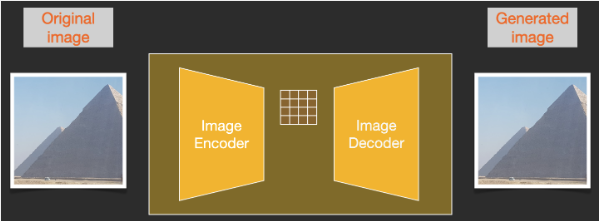
在上文得到了一个结果之后,利用图像解码器,将结果图像(其实更应该称为一组低维度的信息)转化为最终生成的图像。
这里的 Decoder 模型只会运行一次,将“潜空间”的图(4*64*64)转化为人类能够欣赏的 RGB 的图像(3*512*512)(这里默认生成一张512*512大小的图)
当然,如果您能够欣赏高维空间,或者您的视网膜可以识别更多原色,那么这里的转化也会改变。让我们脱下人类的伪装再次相认!
扩散模型(Diffusion model)

注意,这里还没有提到本文的主角 SD,我们这里只是介绍它的“前身”。
扩散模型是一种深度学习模型,它是一种生成式模型。于是它也离不开基本的结构:拿一些数据集进行训练,最终“学会”一些技能。
为什么叫扩散模型呢,因为在它的数学原理上,很像一种扩散,而我们能够进行训练和生成的根源在于:扩散可以进行前向扩散与反向扩散,这两种扩散
具体的逆向扩散转化为前向扩散的数学过程非常神奇且优美,在后续文章中会进行论文和数学推导层面的详解
而让扩散模型本身与 VAE,GAN这些同样是生成式模型不同的,也就是它的扩散:在前向扩散阶段,对图像逐渐添加噪声,直到图像完全变成高斯噪声。在逆向扩散阶段,让受过训练的预测器预测一些噪声,将完全随机的噪声图像逐渐去噪,最终还原
这个过程听起来十分匪夷所思,听起来就像是违反了自然界的熵增定律,对此,本人有不成熟的一种解释:
从深度学习的几何层面来说,有一个定律叫流形分布定律,它描述了自然界中,同一种类别的高维数据,往往可以集中在某个低维的某个流形结构里。
而同一个类别的高维数据,在不同的子类中对应了这个流形结构的不同概率分布,而可以通过这些概率分布对子类进行区分
而深度学习本身就是从数据中学习这种流形结构和概率分布。同样还可以发现,现实中,自然界的图像信息基本都符合流式分布,不是随机的,无论是人脸还是花草树木,一切的图像特征都能在某个低维度的某个流形附近分布,所以我们可以通过深度学习的方式最终得到结果
以上的解释也只是我的个人理解,希望各位能够批评指正。
从结果证明,深度学习模型确实可以掌握一些图像关系,也能从完全随机的高斯噪声中生成符合自然界图像规律的图像(虽然有些也很鬼畜)。我们暂且放下对深度学习这件“反直觉”事情的不信任,来看扩散的过程。

前向扩散(Forward diffusion)
前向扩散就是将高斯噪声加入到用来训练的图像中,让他变得越来越没有特点,就像是熵增过程,图像本身的有序性和规律性会随着噪声的不断增加而越来越弱。
反向扩散 (Reverse diffusion)
反向扩散的前提是一张完全随机的高斯噪声,而为了最终能够得到一张我们想要的图片,我们需要知道图像中添加了多少的噪声,这就是扩散模型的关键所在,噪声预测因子noise predictor,拿大量的图片和数据来训练这样一个噪声预测器,最终得到一个能够预测噪音的工具。
在 SD 模型中,使用Unet神经网络。
最终,我们不断地在纯随机的噪声图片内,不断减去预测的噪声,就可以得到一张图片。
可以看到,噪声预测器是和训练的数据高度相关的,这是因为我们在训练时,让预测出来的噪声是倾向于接近“训练集内原始图片添加噪声后的结果”的。所以在图片中把预测出来的噪声去掉后,最后得到的清晰图片与训练集的原图有着相同的信息分布规律。
Stable Diffusion 模型的原理
您可能会在下文中看到许多模型的名称!
我们上文提到了众多概念,都仍只是“开胃菜”,因为真正要介绍的重点是 SD 模型,之前提到的扩散和预测等过程,本质上都是数学计算。而目前来说,我们的独立计算机算力都是难以支持这些扩散模型的。(至少在量子计算机商用之前),而 SD 模型,主要就是解决了计算速度的问题。
潜在扩散模型(latent diffusion)
计算量大的一大原因就在于图像本身过大,比如512*512的图片,光挨个像素过一遍(包括RGB)都需要78万的计算/访问次数,SD 模型可以将图像压缩在潜空间(latent space)中,(4*64*64)相比于原空间,小了48倍,所以计算速度可以提升许多。
变分自编码器(VAE,Variantional Autoencoder)
对 SD 模型作图比较熟悉的可以了解,VAE 在图像生成时可以接近“滤镜”的效果,在效果层面作用不如Lora,而在原理上,VAE 就重要的多,它是 SD 可以将模型转化到潜空间的保障。
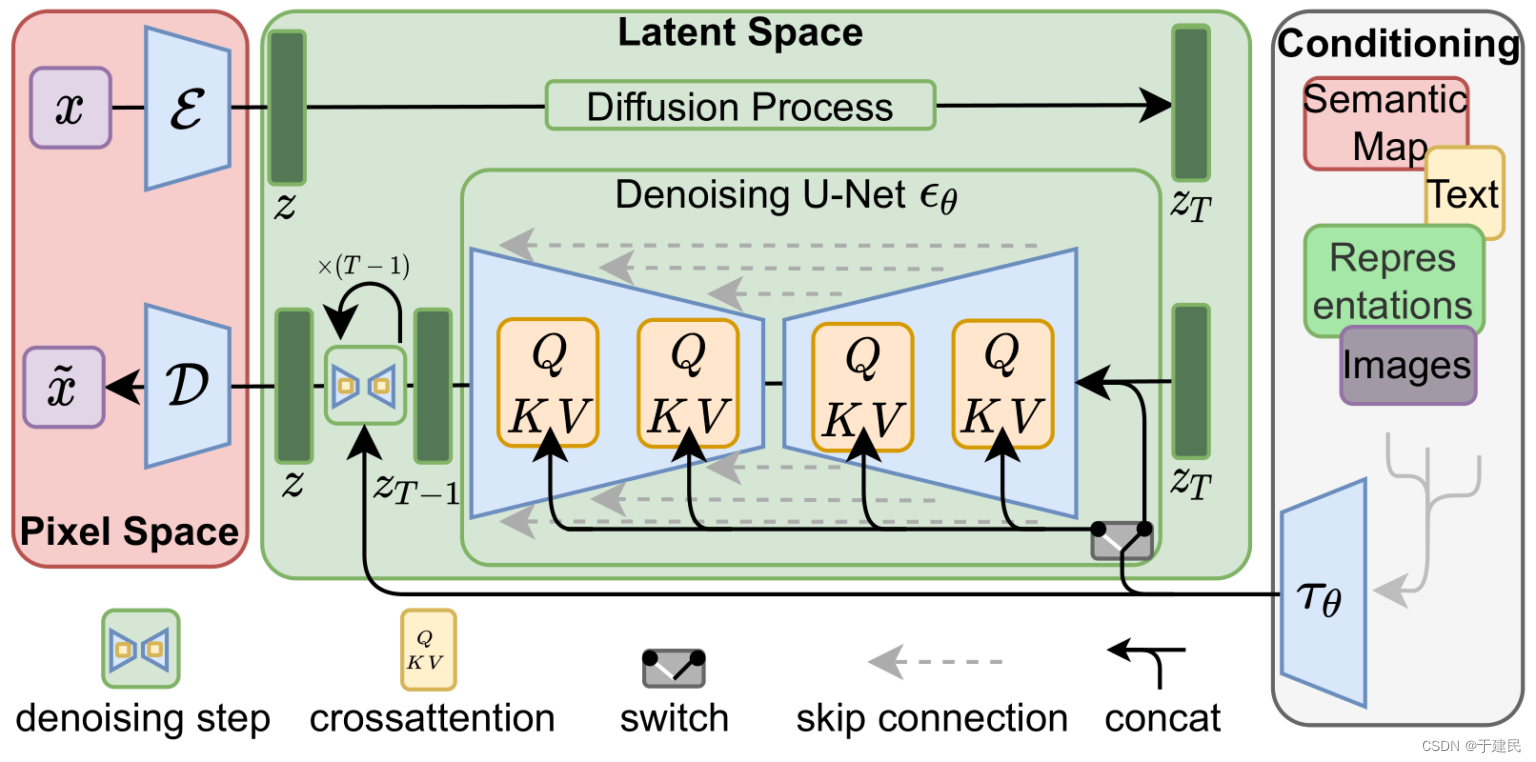
所以,SD 模型并没有在原本的像素空间内生成噪声去破坏训练图像,而是在潜空间内,用潜在噪声破坏“图像在潜空间的表示”
这样是不是听起来对于那些作为训练集的小猫小狗没有这么残忍了?
而把图像压缩为潜在空间而不会丢失信息,原因还是前文提到的流形假设,在高维空间的信息表示中,往往存在着冗余,这也就意味着他们存在“被转化为低维空间信息表示同时不丢失太多信息”的机会。
就像如果用三维坐标去表示球面某个坐标,那么有太多的坐标属性都被浪费了,他们可能在球内可能在球外。无论如何,这种高维表示方法的信息密度较低,而学过初中地理的我们就可以知道,在地球上,只需要经度和纬度就可以表示一个球面的位置,此时信息的表示维度就降低了。
而许多其他模型,如Imagen模型,选择在像素空间内直接进行推理,当然也有模型自己独特的加速手段。
提示条件的引入
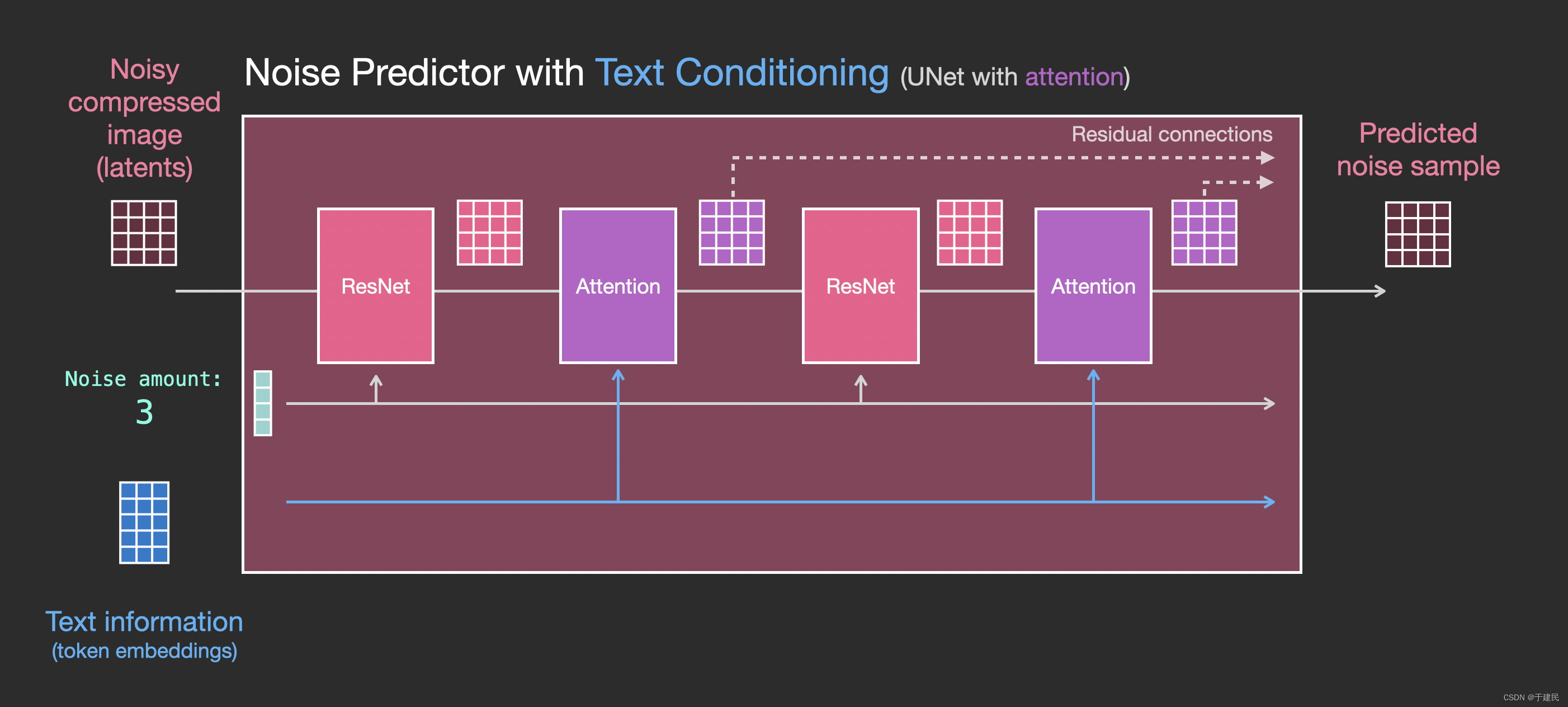
至此,本文已经基本介绍了 SD 模型的工作原理,但是仍未涉及 SD 模型的一个核心点 —— 提示词(Prompt),这部分也是十分值得深入的,在后续的文章中,也会详细介绍。
我们之前在扩散模型中,对于噪声预测器进行了介绍,而其实噪声预测器的输入除了当前的潜空间内的图片,还有提示词的作用。
在 Clip 模型中,将每一个提示词固定在一个嵌入向量里。最后在文本转换器(Text transformer)内进一步处理嵌入,最后影响 Noise perdictor
嵌入(Embedding)也是一个十分关键的机制,整个馈送的过程需要仔细阅读代码才可以完全理解,本系列后续文章中也会提到,同时对此感兴趣可以阅读代码分析系列文章
Img2Img
SD 模型的另一核心功能,Img2Img,是SDEdit方法中首次提到的方法,它主要做的工作是,不再完全随机地在潜空间内生成一个噪声,而是在输入图片本身添加一定的噪声,添加噪声的程度和设置的参数有关。
总结
至此,本文介绍了 SD 模型的基础流程和概念,本着互联网的开源精神做出技术分享。
因为篇幅受限,还有许多十分有价值的内容没有介绍。无数学者和从业者在该领域做出的创新,比如采样器(Sampler),超网络(HyperNetwork),Lora等。这些内容都会在后续的文章中,逐步深入地介绍。
本人也是AIGC领域的初学者,希望前辈们多多指教!
希望对有所帮助。
附录
参考文章:
- The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time. (jalammar.github.io)
- 【Stable Diffusion】之原理篇 - 知乎 (zhihu.com)
- [2006.11239] Denoising Diffusion Probabilistic Models (arxiv.org)
- 深入浅出讲解Stable Diffusion原理,新手也能看明白 - 知乎 (zhihu.com)
- [2205.11487] Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (arxiv.org)
- Stable Diffusion原理解读 - 知乎 (zhihu.com)