Elasticsearch 分词
为什么自定义分词
当 Elasticseach 自带的分词器无法满足时,可以自定义分词器,通过自组合不同的组件实现
-
Character Filter
-
Tokenizer
-
Token Filter
Character Filter
在 Tokenizer 之前对文本进行处理,例如增加删除及替换字符,可以配置多个 Character Filter 。
自带的 Character Filter
HTML strip —— 移除 html 标签
Mapping —— 字符串替换
Pattern —— 正则匹配替换
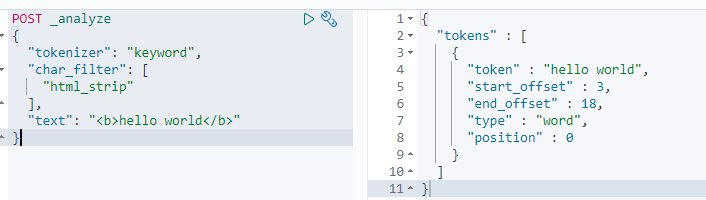
Tokenizer
将原始的文本按照一定的规则,切分为词(term or token),也可以用 java 开发插件,实现自己的 Tokenizer
内置的 Tokenizer
whitespace/standard/uax_url_email/pattern/keyword/path hierarchey
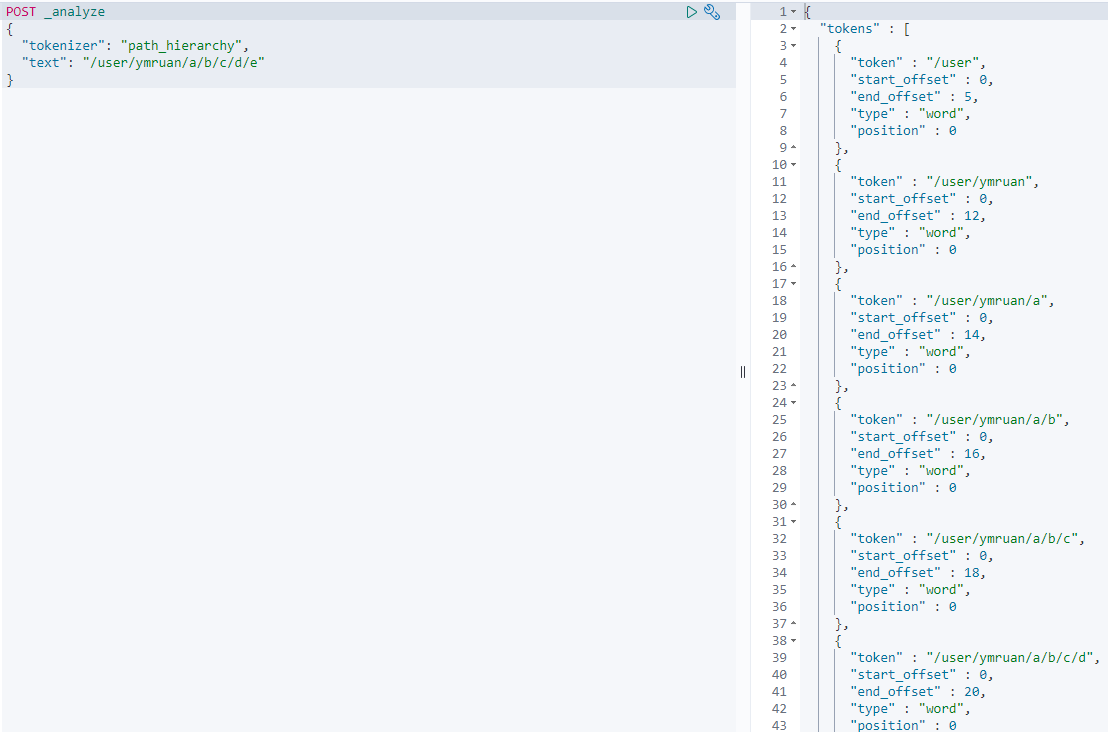
Tokenizer Filter
将 Tokenizer 输出的单词,进行增加,修改,删除
自带的 Token Filter
-
Lowercase
-
stop
-
synonym(添加近义词)
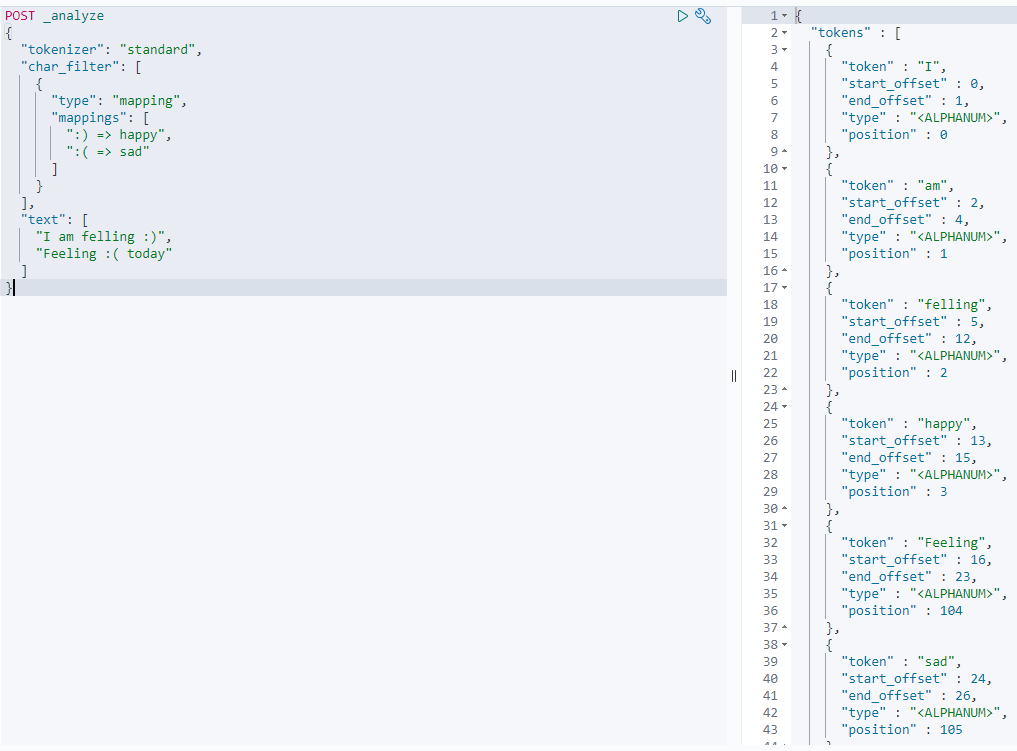
使用char filter 替换表情符号
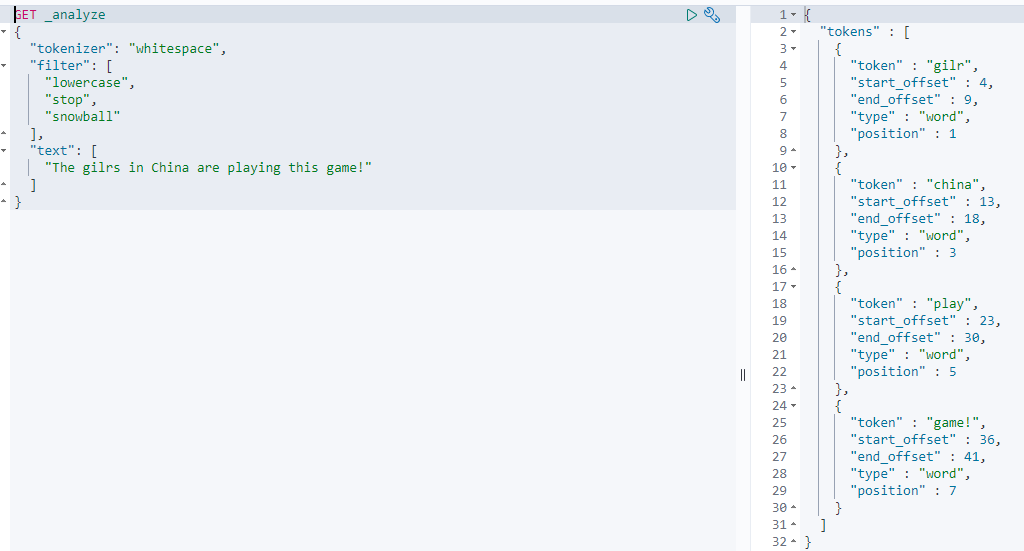
lowercase stop snowball 组合使用
正则表达式 pattern
