作业①
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
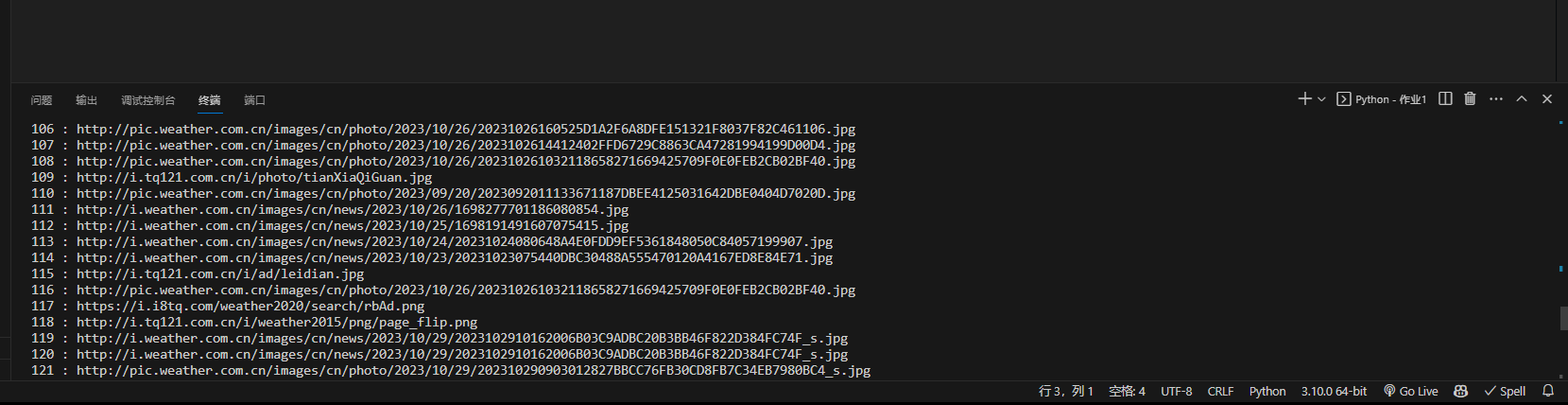
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
myspider.py
import scrapy from demo1.items import weatherItem import reclass myspider(scrapy.Spider):
name = 'demo'
start_urls = ["http://www.weather.com.cn/"]count = 0 total = 0 def parse(self, response): html = response.text urlList = re.findall('<a href="(.*?)" ', html, re.S) for url in urlList: self.url = url try: yield scrapy.Request(self.url, callback=self.picParse) except Exception as e: print("err:", e) pass if (self.count >= 8): break def picParse(self, response): imgList = response.xpath("//img/@src") for k in imgList: k = k.extract() if self.total > 128: return try: item = weatherItem() item['img_url'] = k item['number'] = self.total self.total += 1 yield item except Exception as e: print(e) # pass
items.py
class weatherItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
img_url = scrapy.Field() # 图片链接
number = scrapy.Field() # 图片编号
pipelines.py
class weatherPipeline(object):def open_spider(self, spider): self.threads = [] print("爬虫开始") def process_item(self, item, spider): url = item['img_url'] print(str(item['number'])+" : "+url) T = threading.Thread( target=self.download_img, args=(url, item["number"]) ) T.setDaemon(False) T.start() self.threads.append(T) return item def download_img(self, url, number): img_data = requests.get(url=url).content img_path = "D:\\schoolfile\\desktop\\images" if not os.path.exists(img_path): os.makedirs(img_path) img_path = img_path + f"\\{number}.jpg" with open(img_path, 'wb') as fp: fp.write(img_data) def close_spider(self, spider): for i in self.threads: i.join() print("爬虫结束")
多线程
def process_item(self, item, spider):
url = item['img_url']
print(str(item['number'])+" : "+url)
T = threading.Thread(
target=self.download_img,
args=(url, item["number"])
)
T.setDaemon(False)
T.start()
self.threads.append(T)
return item
单线程
def process_item(self, item, spider):
url = item['img_url']
img_data = requests.get(url=url).content
img_path = 'D:\\schoolfile\\desktop\\images'
if not os.path.exists(img_path):
os.makedirs(img_path)
img_path = img_path + f"\\{item["number"]}.jpg"
with open(img_path, 'wb') as fp:
fp.write(img_data)
return item
心得体会:
了解到可以在在settings.py中开启多线程,还可以设置线程数CONCURRENT_REQUESTS = number,以及scrapy专门
巩固了
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
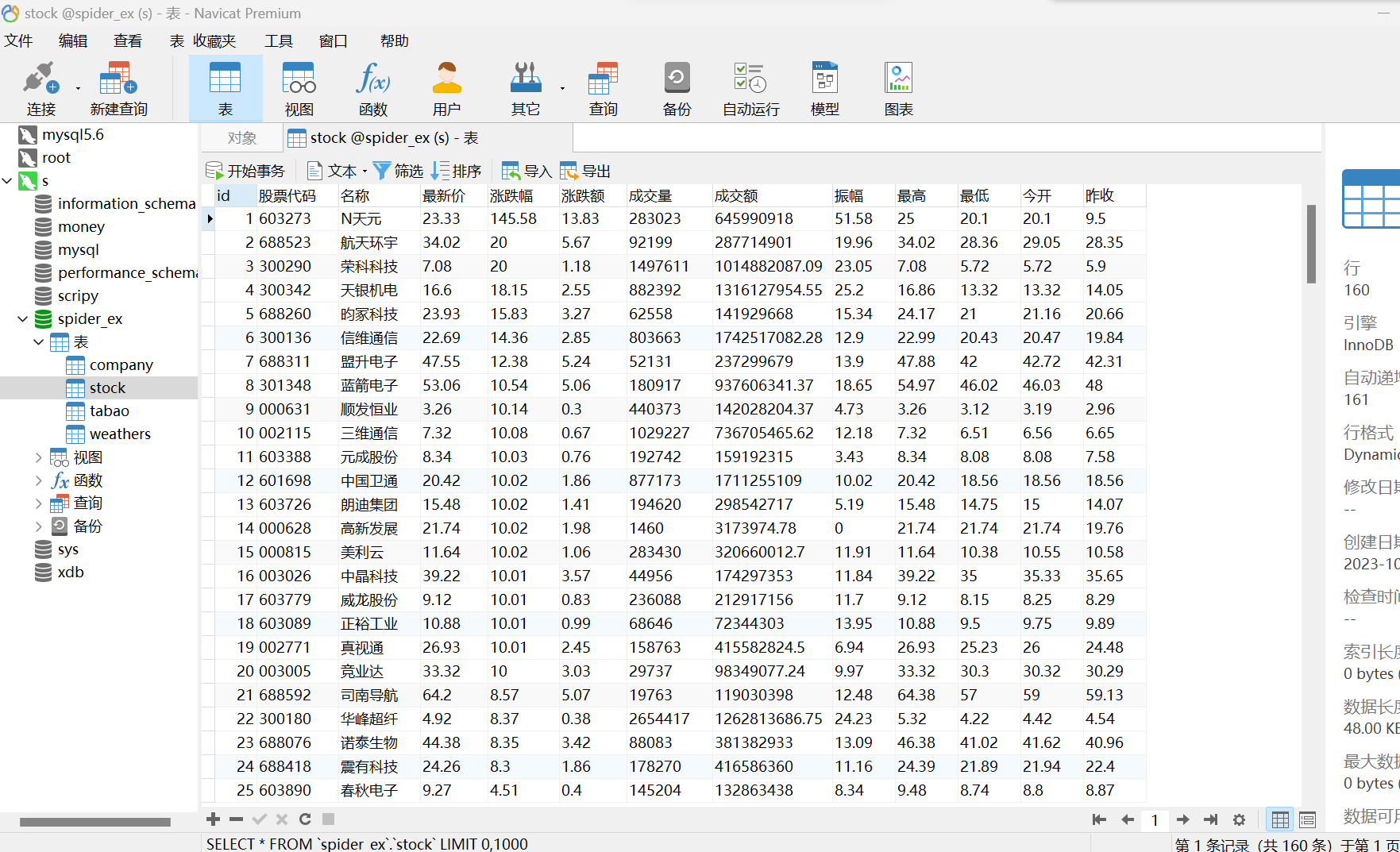
输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
myspider.py
import scrapy import re from demo2.items import Demo2Item import jsonclass MyspiderSpider(scrapy.Spider):
name = "mySpider"start_urls = [ f"http://69.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112404051870421148309_1698029610476&pn={page}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1698029610477" for page in range(1, 8) ] def parse(self, response): data = response.body.decode("utf-8") datastr = re.compile('"diff":\[(.*)\]', re.S).findall(data) # print(datas) datas = re.compile('{(.*?)}', re.S).findall(datastr[0]) # print(datas) for data in datas: data = json.loads('{'+data+'}') item = Demo2Item() item["股票代码"] = data["f12"] item["名称"] = data["f14"] item["最新价"] = data["f2"] item["涨跌幅"] = data["f3"] item["涨跌额"] = data["f4"] item["成交量"] = data["f5"] item["成交额"] = data["f6"] item["振幅"] = data["f7"] item["最高"] = data["f15"] item["最低"] = data["f16"] item["今开"] = data["f17"] item["昨收"] = data["f18"] yield item
items.py
import scrapy
class Demo2Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
股票代码 = scrapy.Field()
名称 = scrapy.Field()
最新价 = scrapy.Field()
涨跌幅 = scrapy.Field()
涨跌额 = scrapy.Field()
成交量 = scrapy.Field()
成交额 = scrapy.Field()
振幅 = scrapy.Field()
最高 = scrapy.Field()
最低 = scrapy.Field()
今开 = scrapy.Field()
昨收 = scrapy.Field()
pipelines.py
from itemadapter import ItemAdapter from demo2.mydb import mydbclass Demo2Pipeline:
def __init__(self): self.db = mydb() self.db.create('create table if not exists stock(id int AUTO_INCREMENT PRIMARY KEY,股票代码 varchar(20),名称 varchar(20),最新价 varchar(20),涨跌幅 varchar(20),涨跌额 varchar(20),成交量 varchar(20),成交额 varchar(20),振幅 varchar(20),最高 varchar(20),最低 varchar(20),今开 varchar(20),昨收 varchar(20))') def process_item(self, item, spider): sql = "Insert into stock(股票代码,名称,最新价,涨跌幅,涨跌额,成交量,成交额,振幅,最高,最低,今开,昨收) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)" values = ( item["股票代码"], item["名称"], item["最新价"], item["涨跌幅"], item["涨跌额"], item["成交量"], item["成交额"], item["振幅"], item["最高"], item["最低"], item["今开"], item["昨收"] ) self.db.insert(sql,values) return item def close_spider(self,spider): self.db.show('stock')
心得体会
依旧使用接口的方法来,配合正则表达式获取数据,将长用的数据库操作封装起来使用,后来发现真是多此一举
作业③
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
输出信息:
myspider.py
import scrapy from bs4 import UnicodeDammitfrom wb.items import MoneyItem
class ChangeSpider(scrapy.Spider):
name = 'mySpider'def start_requests(self): start_urls = ['https://www.boc.cn/sourcedb/whpj/'] for i in range(1, 5): url = 'https://www.boc.cn/sourcedb/whpj/index_%d.html' % i start_urls.append(url) for url in start_urls: yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): dammit = UnicodeDammit(response.body, ["utf-8", "gbk"]) data = dammit.unicode_markup selector = scrapy.Selector(text=data) money = selector.xpath("//table[contains(@align,'left')]//tr") for moneyitems in money[1:]: # 处理表头 currency = moneyitems.xpath("./td[position()=1]/text()").get() TSP = moneyitems.xpath("./td[position()=2]/text()").get() CSP = moneyitems.xpath("./td[position()=3]/text()").get() TBP = moneyitems.xpath("./td[position()=4]/text()").get() CBP = moneyitems.xpath("./td[position()=5]/text()").get() Time = moneyitems.xpath("./td[position()=8]/text()").get() item = MoneyItem() item["currency"] = currency if currency else "" # 处理空标签 item["TSP"] = TSP if TSP else "" item["CSP"] = CSP if CSP else "" item["TBP"] = TBP if TBP else "" item["CBP"] = CBP if CBP else "" item["Time"] = Time if Time else "" yield item
items.py
import scrapy
class MoneyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
currency = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
Time = scrapy.Field()
pipelines.py
from itemadapter import ItemAdapter from bs4 import UnicodeDammit import pymysql import datetimeclass MoneyPipeline(object):
count = 0
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",passwd = "1234", db = "money", charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from changes")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = Falsedef process_item(self, item, spider): print("序号\t", "交易币\t", "现汇卖出价\t", "现钞卖出价\t ", "现汇买入价\t ", "现钞买入价\t", "时间\t") try: self.count = self.count + 1 self.cursor.execute("insert into changes(bId,bCurrency,bTSP,bCSP,bTBP,bCBP,bTime)values(%s,%s,%s,%s,%s,%s,%s)",(self.count,item["currency"],item["TSP"],item["CSP"],item["TBP"],item["CBP"],item["Time"])) except Exception as err: print(err) return item def close_spider(self, spider): if self.opened: self.con.commit() self.con.close() self.opened = False print("closed") print("总共爬取", self.count, "条信息")

心得体会
对scrapy框架更加熟悉了