ABSTRACT
现存的KGE方法无法适用于大规模的图(由于存储和推理效率的限制)
作者提出了一种LightKG框架:
自动的推断出码本codebooks和码字codewords,为每个实体生成合适的embedding。
同时,框架中包含残差模块来实现码本的多样性,并且包含连续函数来近似的实现码字的选择。
为更好的提升KGE的表现,作者提出了基于量化的动态负采样方法,可用于LightKG框架和其他框架中(效果可以提升19%)。
1 Introduction
往常方法:学习实体和关系的embedding在连续的空间中。
假设空间维数为d,实体个数为\(n_e\),关系个数为\(n_r\)。
存储所用空间为\(4n_ed+4n_rd\)。
例如任务\((h,r,?)\),时间复杂度约为\(O(n_ed + Klogn_e)\)
\(n_e\)越大,时间复杂度越高。
哈希和PQ算法可能会导致更低的精度,容易出错。
基于上述的挑战,本文提出了LightKG。仅考虑实体嵌入。
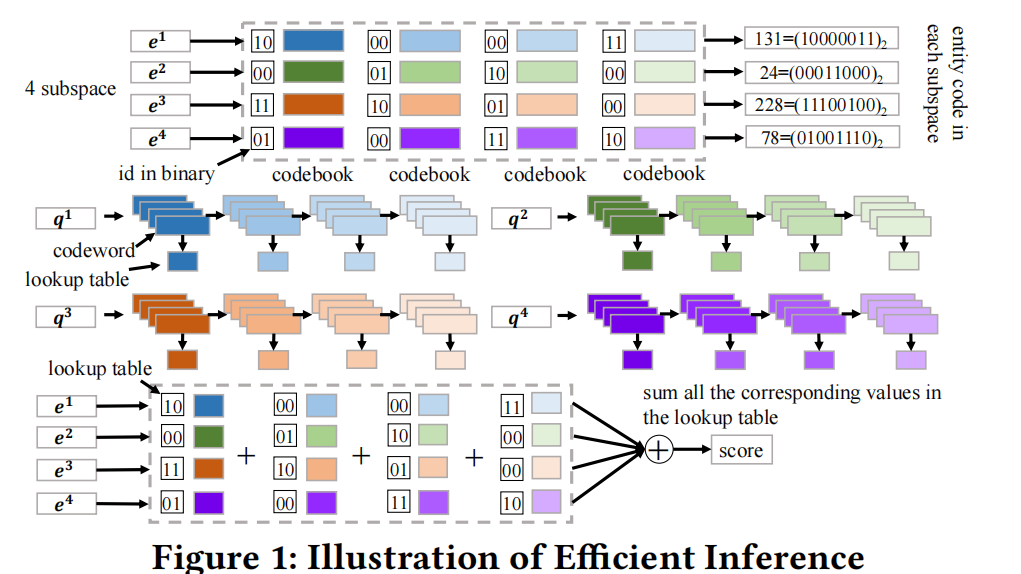
整体架构如上所示。
先将d维的向量划分到m个子空间中。
假设每个空间有B个码本,每个码本中有m个码字。
在每个码本中找到最接近的码字,再将码字相加,可以与原始embedding近似。
对于一个实体,可以用最相近码字的下标来表示。
每个向量编码后内存为\(\frac{1}{8}mBlogW\)
原始向量占内存为\(4d\).
当进行向量查询时,先对query向量(根据码本中的码字)建立lookup表。
之后,和每个实体间相似性分数的计算就转化为在lookup表中查询再求和。
总的时间复杂度为\(O(n_e+BWd)\)
2 Related work
KGE方法主要分为三类
- Translation-based model:主要应用欧几里得距离和曼哈顿距离等
- bilinear model
- deep learning-based model:如ConvE,R-GCN等
同时轻量级框架也在快速发展,比如:二值化网络,PQ等
负采样:RotatE
3 Methodology
3.1 Problem Formulation
{$G = {(h,r,t)|h,t\in E, r \in }R $}
学习embedding \(h,t\in \mathbb{R}^d, r\in \mathbb{R}^d\)
同时设定相关性评分有:\(f(\cdot): E×R×E \rightarrow \mathbb{R}\)
3.2 Overview
先把向量划分为多个子空间并学习码字(codeword),
同时采用残差模型,利用多个码字实现压缩的embedding。
也会额外介绍损失函数和训练过程。
同时会采用动态下采样的方法来弥补压缩带来的性能下降。
3.3 Codeword learning
现存的量化方法(基于kmeans)无法微分。
将d维向量e分割到m个子空间中,可以知道\(e^i\in \mathbb R^{d/m}\)
原始向量可以表示为\(e = [e^1,e^2,....,e^m]\)
每个子空间对应B个码本,每个码本中有W个码字。
学习码字的过程可以表示为:
\(c_{w^b(i)}^b(i)=C^b(i)o\),其中\(C^b(i)\in \mathbb R^{d/m×W}\),
o表示独热编码\(o_{w^b(i)}=1\)
独热编码是不能微分的,采用近似
\(o_j \approx \hat{o_j} = \frac{exp(s(e^i,c_j^b(i))/T)}{\sum_{j'}exp(s(e^i,c_{j'}^b(i))/T)}\)
基于softmax回归和Straight-Through Estimator实现codebooks的学习。
同时,相似度函数也是重要的,本篇文章采用的相似性函数是
\(s(e,c) = e^TMc\)
3.4 Residual Module
如何利用B个codebooks得到合适的embedding
简单的对embedding进行B次编码得到B个codewords的话。
B个codebooks会有相似的趋势,然而要求对向量编码codebook要尽可能地丰富。
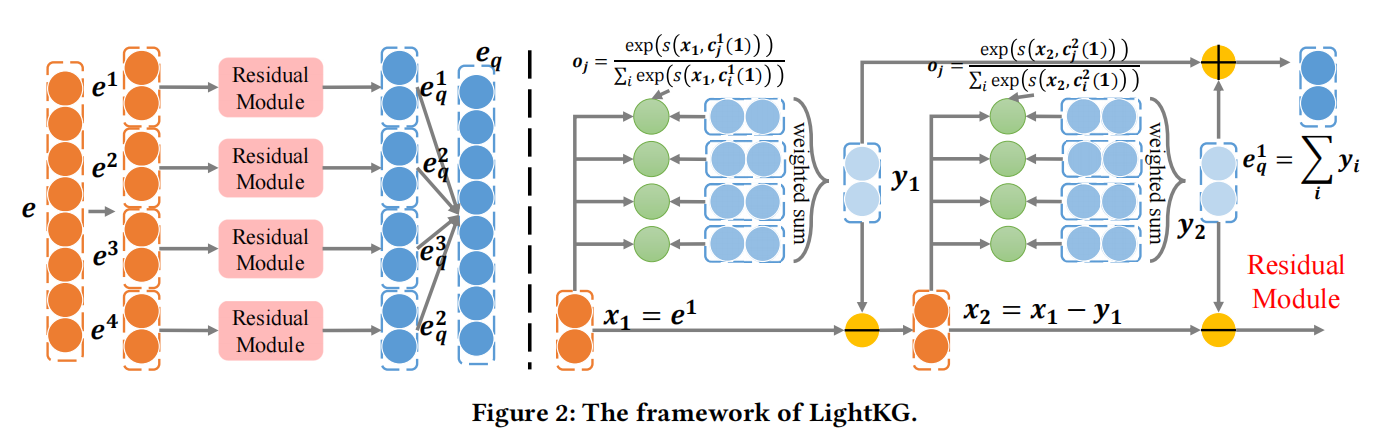
本文提出了一种残差模型来实现向量编码的多样性。
整体过程如上所示。
记\(c_{w^b(i)}^b=Q(x;C^b(i))\),相当于对向量x在码本b中找到一个合适的码字。
整体过程如下:\(x_{b+1}=x_b - Q(x_b;C^b(i)), x_1=e^i\)
每次的输入是不同的,得到的码字也会不同。
最后会在B个码本中找到多样化的b个码字。
最后将所有码字联系起来,即为最终的表示。
3.5 Loss Function
LightKG输入为三元式,输出为量化后的embedding。。
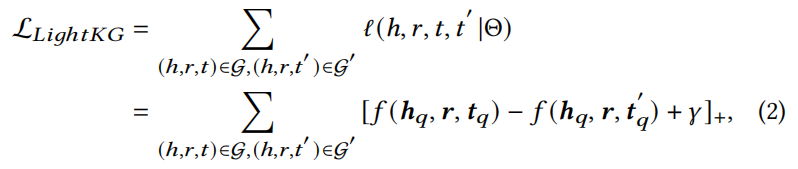
采用margin-based损失函数
3.6 Advantages of LightKG
主要在拟合精度不会有较大下降的情况下,存储效率有很大的提升。
存储方面:
当采用内积时,公式如下:
\(\langle q,e_k\rangle=\sum_{i=1}^m\sum_{b=1}^B\langle q^i,c_{w_k^b(i)}^b(i)\rangle\)
当采用欧几里得公式时,如下所示:
\(||q-e_k||_2^2 = \sum_{i=1}^m||q^i||_2^2+\sum_{i=1}^m||e_k^i||_2^2-2\sum_{i=1}^m\sum_{b=1}^B\langle q^i,c_{w_k^b(i)}^b(i) \rangle\)
当使用第一种距离时,仅需要存储\(4BWd + \frac{1}{8}n_e mBlogW\),
当使用第二种距离时,仅需要存储\(4BWd + \frac{1}{8}n_e mBlogW+4n_e\)。
并且,采用LightKG也可以减少查询的时间。
直接查询,时间复杂度为\(O(n_ed)\)。
当采用码表时,时间复杂度为\(O(n_e + BWd)\)
因为\(q_i\)和码表中所有码本进行距离计算的时间复杂度是很低的,之后只要对每个实体进行查询操作即可。