个人项目
| 软件工程 | ?https://edu.cnblogs.com/campus/gdgy/CSGrade21-34 |
|---|---|
| 作业要求 | ?https://edu.cnblogs.com/campus/gdgy/CSGrade21-34/homework/13023 |
| GitHub链接 | ?https://github.com/CloseCG/3121005043 |
| 作业目标 | 设计一个论文查重算法,并且给出原文和指定文件的相似度 |
PSP表格
| *PSP2.1* | *Personal Software Process Stages* | *预估耗时(分钟)* | *实际耗时(分钟)* |
|---|---|---|---|
| Planning | 计划 | 20 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 200 | 240 |
| Development | 开发 | 240 | 200 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 180 |
| · Design Spec | · 生成设计文档 | 40 | 30 |
| · Design Review | · 设计复审 | 20 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 10 |
| · Design | · 具体设计 | 120 | 80 |
| · Coding | · 具体编码 | 120 | 120 |
| · Code Review | · 代码复审 | 30 | 10 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 200 |
| Reporting | 报告 | 60 | 70 |
| · Test Repor | · 测试报告 | 30 | 20 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 10 |
| · 合计 | 1120 | 1230 |
一
需求分析
分析题目,这是一个NLP任务,在自然语言处理中,经常需要判断两篇文章的相似度。
关于如何判断对比内容重复,则需要依靠文本相似度算法。经过查询资料,发现有如下算法:
-
Jaccard 相似度算法
-
余弦相似性
-
SimHash算法
分词:将句子、段落或者文章这种长文本,分解为以适当颗粒度的字词为单位的数据结构,方便后续的处理分析工作。
余弦相似度:依靠分词后每个分词的频数构建向量,在欧式空间中计算余弦度,感觉蛮骚的,不过处理大文本会不会太慢了(仔细想想,也不一定)。
Jaccard算法:计算集合的交集与集合的并集的比例。如果两篇文章有字/分词重复,则会增加相似度,比余弦相似度的频数貌似更加严格,一想到我的毕设仅仅字重复就让查重率蹭蹭涨太恐怖了,就不用了。
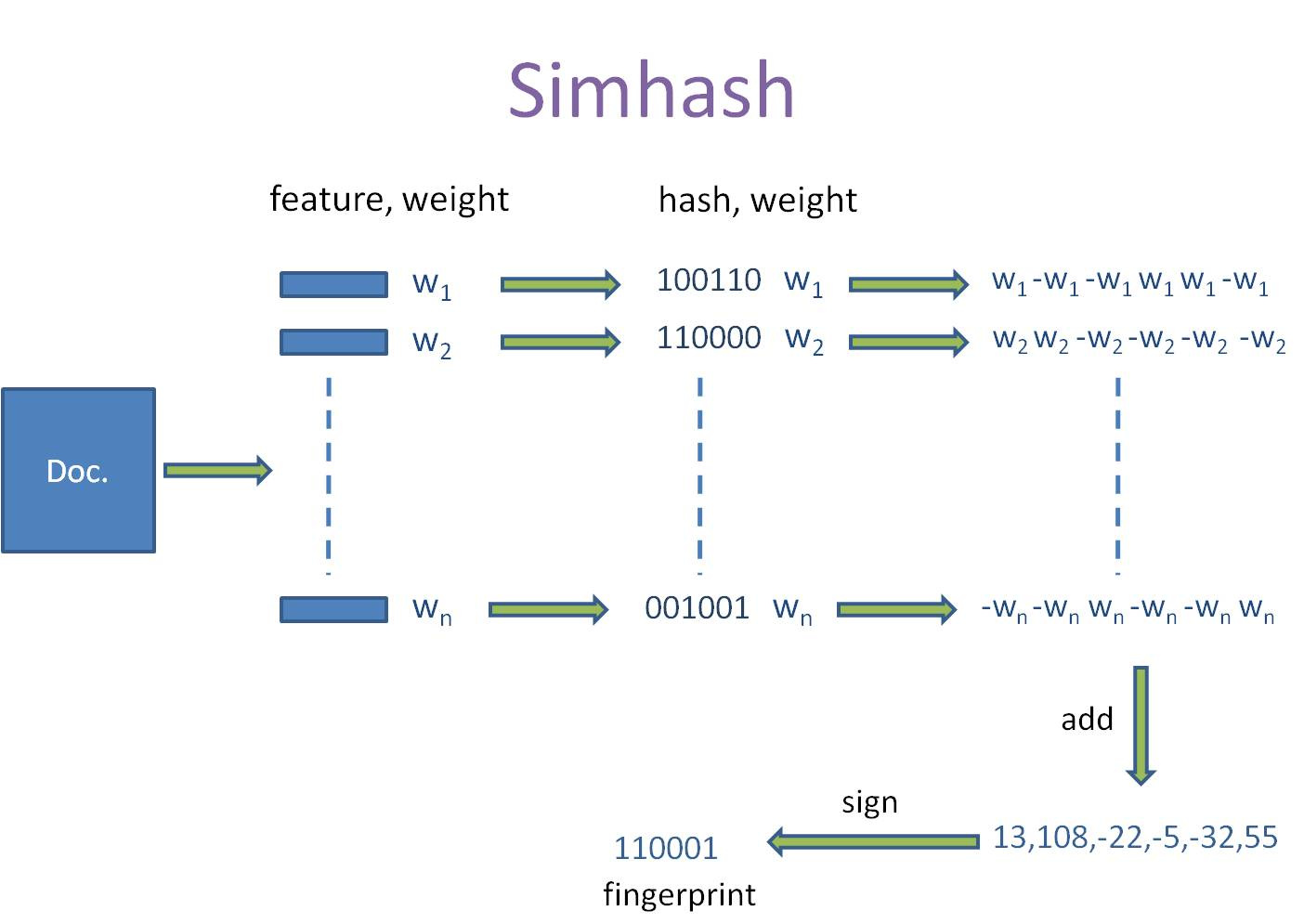
Sim Hash:
- 将文档分词,得到一个"词-权重"的集合
- 对其中的词(feature),进行普通的哈希之后得到一个64位的二进制。
- 根据(2)中得到一串二进制数(hash)中相应位置是1是0,对相应位置取正值weight和负值weight。例如一个词进过(2)得到(010111:5)进过步骤(3)之后可以得到列表[-5,5,-5,5,5,5]
- 对(3)中的列表进行列向累加得到一个列表。如[-5,5,-5,5,5,5]、[-3,-3,-3,3,-3,3]、[1,-1,-1,1,1,1]进行列向累加得到[-7,1,-9,9,3,9],这样,我们对一个文档得到,一个长度为64的列表。
- 对(4)中得到的列表中每个值进行判断,当为负值的时候去0,正值取1。例如,[-7,1,-9,9,3,9]得到010111,这样,我们就得到一个文档的simhash值了。
- 计算相似性。连个simhash取异或,看其中1的个数是否超过3。超过3则判定为不相似,小于等于3则判定为相似。
经过考虑后,本文决定按照以下思路解决此任务:
- 考虑到文本较长,决定利用SimHash算法求相似度
- 先利用jieba库进行分词,求得TF-IDF权重最高的前20个词(feature)和其对应权重(weight),得到"词-权重"的集合
- 对集合的"词"使用普通hash算法,求得相同长度二进制位串,即使得集合的每个元素变为"位模式-权重"
- 对集合的每一个元素,让其位模式与权重相乘,即集合的每个元素变为"位模式*权重",得到长度为64的列表
- 对集合的每一个元素,让其位模式与权重相乘,即集合的每个元素变为"位模式*权重"
- 让每个元素求和再降维(大于0为1,否则为0)
- 异或求得相似度
模块接口设计
本文分为三个模块进行设计,分别是文件读取、计算相似度和文件存储。并且还有一个用于判空的自定义异常类EmptyException
关键函数执行流程如下图:
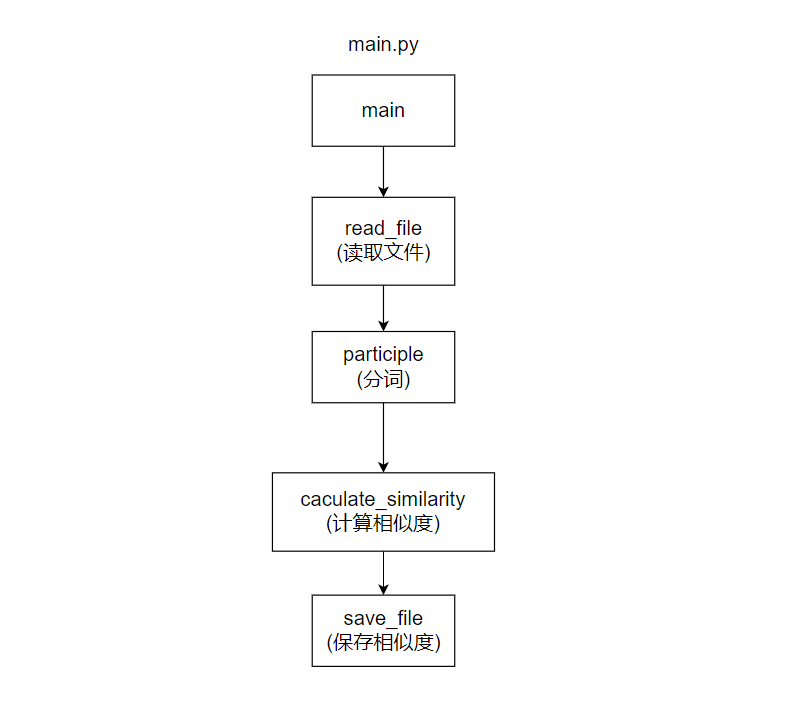
单个模块详实描述如下:
文件读取
关键之处
主要是要捕获两个方面的异常,如文件未找到和文件为空
def read_file(file_path):
# Open the file in read-only mode 'r'
try:
with open(file_path, 'r') as file:
# Read the entire file content
file_content = file.read()
check_empty(file_content)
except FileNotFoundError:
print(f"File '{file_path}' not found")
return FileNotFoundError
except EmptyException as e:
print(f"Caught custom exception: {e}")
return EmptyException
except Exception as e:
print(f"An error occurred: {e}")
return Exception
else:
return file_content
分词
关键之处
第一,考虑输入的类型,并且要检查是否为空。第二,设置停用词(如去掉一些语气助词等等)。第三,设定带权标志位为true,并且只留下权重最高的前20位分词。
def participle(content):
```
if not isinstance(content, str):
raise TypeError
check_empty(content)
jieba.analyse.set_stop_words('./CNstopwords.txt')
tags = jieba.analyse.extract_tags(content, topK=20, withWeight=True)
```
计算相似度
关键之处
此处的o_simhash和p_simhash已经是上述simhash步骤的第四步所得到的值了。
使用o_simhash.distance(p_simhash),这个包会自动执行上述simhash步骤的第五和低六步
注意:此处使用Simhash类时,需要去把源码的collections.Iterable改为collections.abc.Iterable
def calculate_similarity(original_text_weight, plagiarized_text_weight):
```
o_simhash = Simhash(original_text_weight)
p_simhash = Simhash(plagiarized_text_weight)
max_hash_len = max(len(bin(o_simhash.value)), len(bin(p_simhash.value)))
# Hamming distance
distance = o_simhash.distance(p_simhash)
print(f"The hamming distance(they are similar when the value is less than 4): {distance}")
similar = 1 - distance / max_hash_len
```
文件存储
关键之处
主要是要考虑到两个方面的异常,得到的相似度不为float类型或者区间不在[0,1]。并且要记得保留两位小数。
def save_file(file_path, file_content):
# Determine whether it's a float type and whether the size is in [0, 1]
try:
if not isinstance(file_content, float):
raise TypeError
if file_content < 0 or file_content > 1:
raise ValueError
# Open the file in write mode 'w'
with open(file_path, 'w') as file:
# Write content
file.write("{:.2f}".format(file_content))
except TypeError:
print("I say float! You understand")
return TypeError
except ValueError:
print("Keep your value in [0, 1]!")
return ValueError
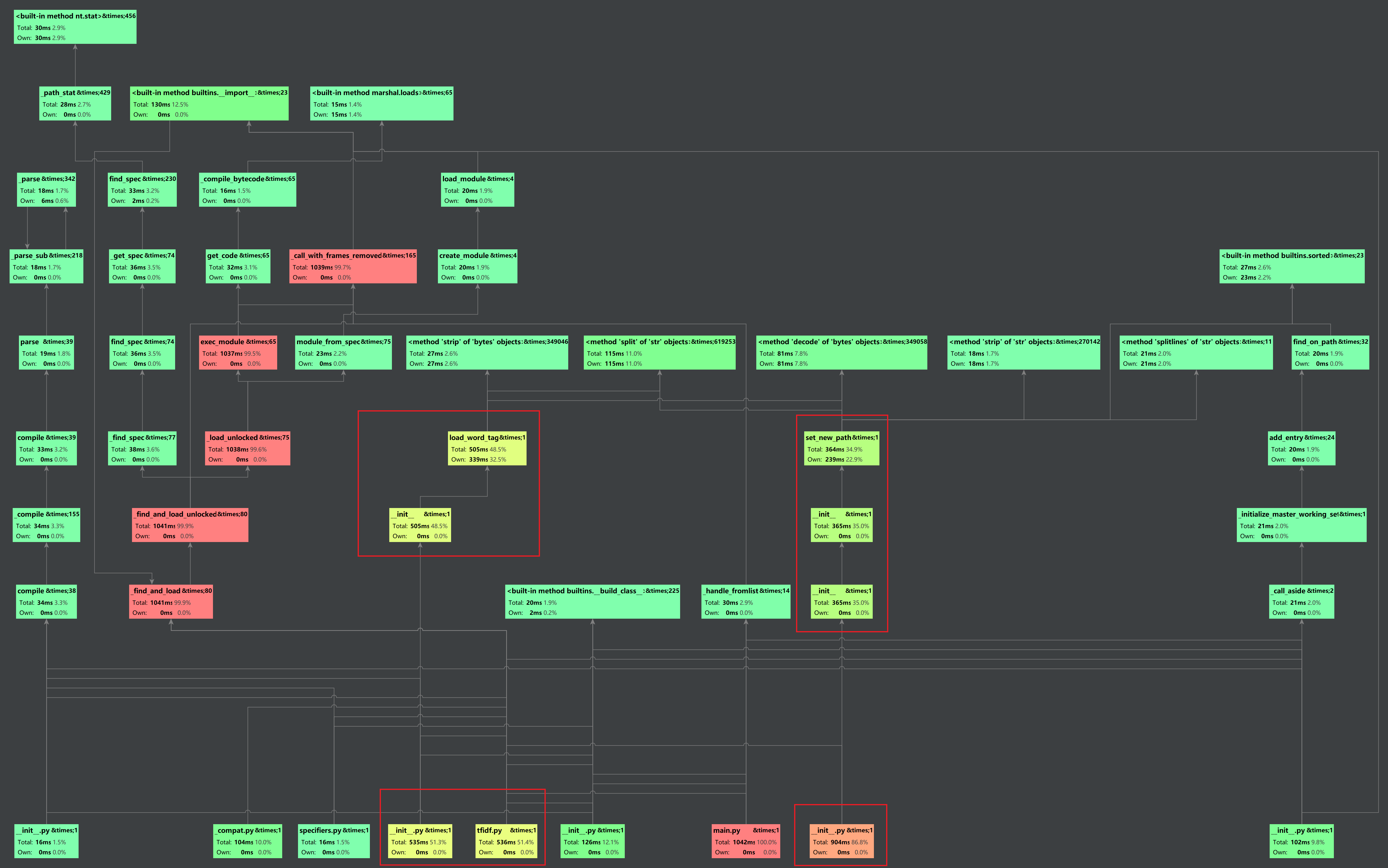
性能改进
使用PyCharm的profile工具,得到下面的Call Graph,除去必需的库函数(红色板块),剩下的圈出红线的各版块就是阻碍高性能的罪魁祸首,但由于是jieba包的库函数,此处确实无法优化。
单元测试
覆盖率
本文设置了13个测试用例
利用Python的coverage包求得如下的覆盖率:
| Module | statements | missing | excluded | coverage |
|---|---|---|---|---|
| main.py | 92 | 5 | 0 | 95% |
| test.py | 58 | 0 | 0 | 100% |
| Total | 150 | 5 | 0 | 97% |
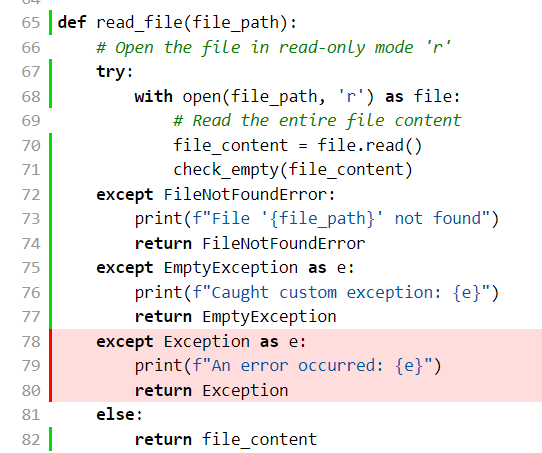
main.py唯一没有测试的部分如下红色部分,故覆盖率基本达到百分之百
部分测试代码
本文主要分为针对四个函数进行测试:
测试calculate_similarity求相似度函数,输入非以元组为元素的list类型,发现它返回了TypeError
def test_calculate_type(self):
s = caculate_similarity('元氏人', '什么档次')
self.assertEqual(s, TypeError)
测试participle分词函数,不输入字符串类型,发现它返回了TypeError
def test_participle_type(self):
s = participle(1)
self.assertEqual(s, TypeError)
测试read_file函数,给出一个错误路径时它会返回FileNotFoundError;而给出一个空文件的时候它会返回一个EmptyException
def test_read_fileNotFound(self):
s = read_file('where are you now')
self.assertEqual(s, FileNotFoundError)
def test_read_empty(self):
s = read_file('test_empty.txt')
self.assertEqual(s, EmptyException)
测试sav_file,给出不位于[0,1]区间的相似度,它会返回一个ValueError
def test_save_value_upperOne(self):
s = save_file('output.txt', 1.1)
self.assertEqual(s, ValueError)
def test_save_value_lowerZero(self):
s = save_file('output.txt', -0.1)
self.assertEqual(s, ValueError)
测试结果
Caught custom exception: There is an empty value in your input!
The hamming distance(they are similar when the value is less than 4): 34
I say list! You understand?
I say string! You understand?
I say string! You understand?
I say list! You understand?
I say float! You understand
What's up bro? Just check your input OK?
Caught custom exception: There is an empty value in your input!
I say string! You understand?
Caught custom exception: There is an empty value in your input!
File 'where are you now' not found
I say float! You understand
Keep your value in [0, 1]!
Keep your value in [0, 1]!
Ran 13 tests in 0.016s
OK
异常处理
本文有四个类型的异常处理
EmptyException
为了检测某个函数的参数输入是否为空,为空则上抛空异常并且打印错误信息
def test_read_empty(self):
s = read_file('test_empty.txt')
self.assertEqual(s, EmptyException)
# output
Caught custom exception: There is an empty value in your input!
TypeError
检测是否函数参数的输入是否为所需的类型,不是则上抛TypeError并且打印错误信息
def test_participle_type(self):
s = participle(1)
self.assertEqual(s, TypeError)
# output
I say string! You understand?
ValueError
检测输入的值是否位于所需区间,不是则上抛ValueError并打印错误信息
def test_save_value_upperOne(self):
s = save_file('output.txt', 1.1)
self.assertEqual(s, ValueError)
# output
Keep your value in [0, 1]!
FileNotFoundError
不是则上抛FileNotFoundError并打印错误信息
def test_read_fileNotFound(self):
s = read_file('where are you now')
self.assertEqual(s, FileNotFoundError)
# output
File 'where are you now' not found
结果分析
由于对于simhash,判断相似依靠的是hamming distance(小于4即为相似),包中相似度的计算emmm感觉不对头啊就不贴了
给出如下每个抄袭文件的海明距离
- orig_0.8_add.txt: 2
- orig_0.8_del.txt: 10
- orig_0.8_dis_1.txt: 2
- orig_0.8_dis_10.txt: 1
- orig_0.8_dis_15.txt: 10
结论:抄袭的时候添加词汇是没用的,应该尽量删除原文的词汇;并且观察后三个文件,以不同的距离将内容打乱,理论上应该是距离越远查重率越小。
但是为什么距离为1的比距离为10的查重率低呢,我猜应该是以1为单位的文件,破坏一部分词组,导致分词时没分出来。
但是以10为单位的文件看似打乱很多词汇,但是却保留了一部分权重高的词组没有打乱,相当于反而筛出了那些容易拿来判断的词组,所以导致查重率高。故遥遥领先。