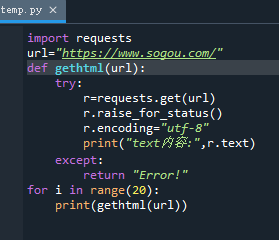
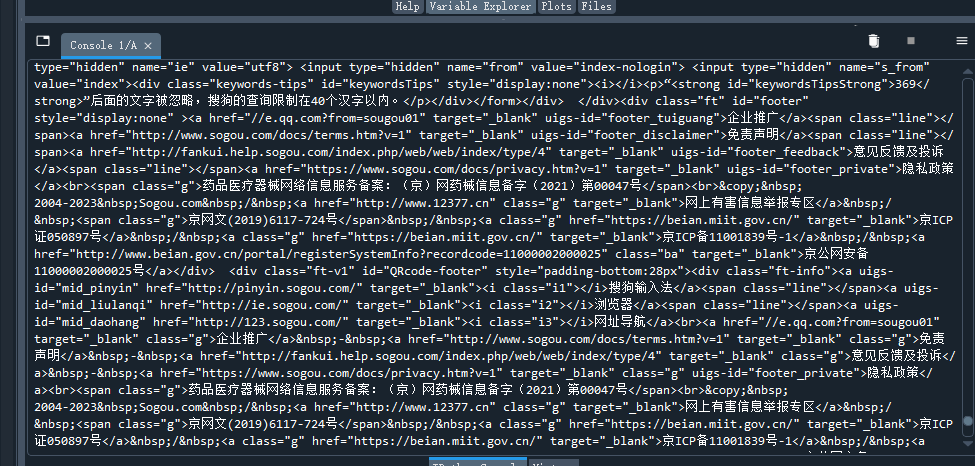
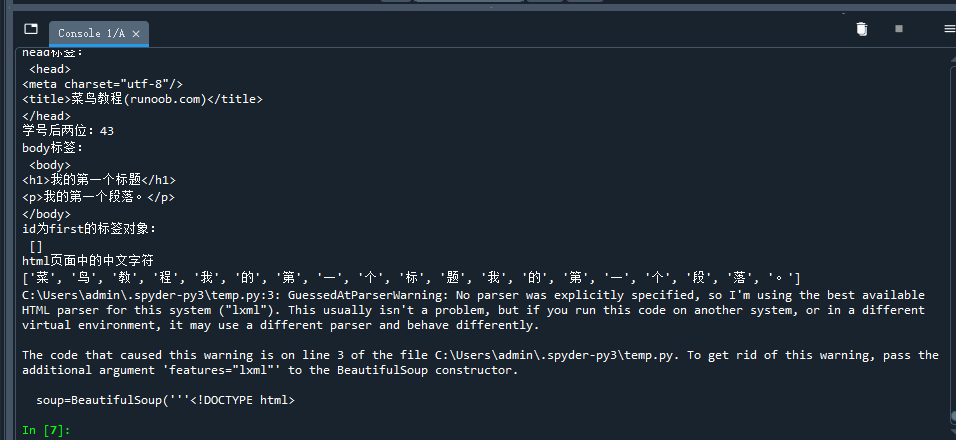
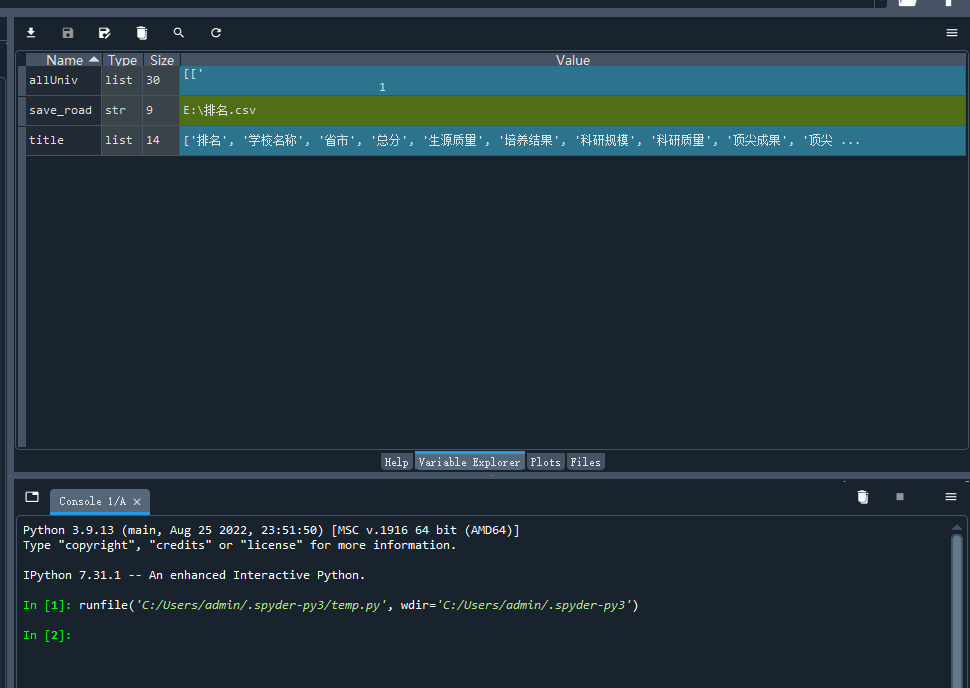
请用requests库的get()函数访问如下一个网站20次,打印返回状态,text()内容,计算text()属性和content属性所返回网页内容的长度。 这是一个简单的html页面,请保持为字符串,完成后面的计算要求 爬中国大学排名网站内容 本栏目推荐文章Python逆向爬虫入门教程: 酷狗音乐加密参数signature逆向解析【转载】淘宝爬虫sign、token详解爬虫常见的反爬手段爬虫之短信验证码scrapy -- 暂停爬虫、恢复爬虫python爬虫示例-2python爬虫示例-1Scrapy爬虫学习爬虫实战 - 微博评论数据可视化爬虫