在本质上,音乐、语音、文本和视频都是连续的。 如果它们的序列被我们重排,那么就会失去原有的意义。 比如,一个文本标题“狗咬人”远没有“人咬狗”那么令人惊讶,尽管组成两句话的字完全相同。
处理序列数据需要统计工具和新的深度神经网络架构。 为了简单起见,我们以 图8.1.1所示的股票价格(富时100指数)为例。


统计工具
自回归模型、马尔可夫模型和因果关系是统计学中的三种不同的模型。这些模型在不同的情况下被用来描述数据之间的关系。
-
自回归模型是一种时间序列模型,它使用自身过去的数据来预测未来。这种模型假设当前数据与之前的观察数据是相关的。自回归模型通常用于预测时间序列数据,如股票价格、气温等。
- 隐变量自回归模型则是一种潜在变量模型,它使用潜在变量来描述数据之间的关系。隐变量自回归模型通常用于建模具有状态的系统,如语音识别、自然语言处理等。
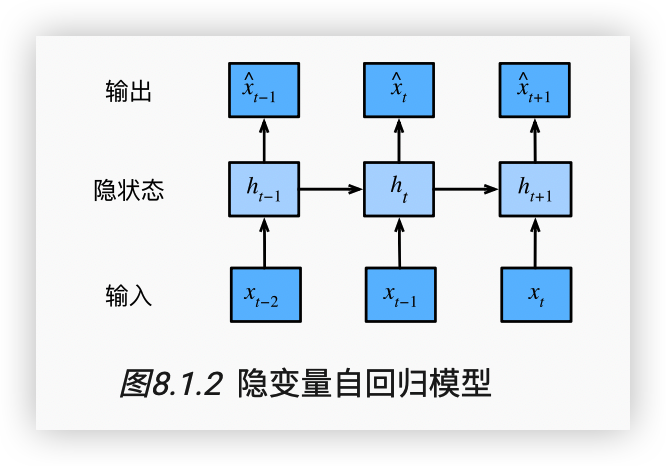
-
马尔可夫模型是一种随机过程,它假设当前状态只与最近的少数状态相关。马尔可夫模型通常用于建模具有状态的系统,如语音识别、自然语言处理等。
-
因果关系是指两个事件之间的因果联系。因果关系通常用于分析因果关系,如药物治疗对疾病的影响等。
这三种模型之间的联系在于它们都是用来描述数据之间的关系。自回归模型和马尔可夫模型都是用来描述数据之间的相关性,而因果关系则是用来描述数据之间的因果关系。这些模型可以相互补充,以提供更全面的数据分析。
内插法和外推法
内插法和外推法是两种不同的方法,用于在现有观测值之间进行估计和对超出已知观测范围进行预测。内插法通常用于填补数据中的缺失值,而外推法则用于预测未来的值。这两种方法在实践中的难度上差别很大,因为外推法需要对超出已知观测范围的数据进行预测,而这些数据可能会受到许多未知因素的影响,从而导致预测结果的不确定性。
对于所拥有的序列数据,在训练时始终要尊重其时间顺序,即最好不要基于未来的数据进行训练。这是因为在实际应用中,我们通常只能使用过去的数据来预测未来的趋势。如果我们使用未来的数据来训练模型,那么模型将无法准确地预测未来的趋势,因为它没有考虑到未来的情况。因此,我们应该始终尊重时间顺序,并使用过去的数据来预测未来的趋势。
总结
-
内插法(在现有观测值之间进行估计)和外推法(对超出已知观测范围进行预测)在实践的难度上差别很大。因此,对于所拥有的序列数据,在训练时始终要尊重其时间顺序,即最好不要基于未来的数据进行训练。
-
序列模型的估计需要专门的统计工具,两种较流行的选择是自回归模型和隐变量自回归模型。
-
对于时间是向前推进的因果模型,正向估计通常比反向估计更容易。
-
对于直到时间步t的观测序列,其在时间步t+k的预测输出是k步预测;。随着我们对预测时间k值的增加,会造成误差的快速累积和预测质量的极速下降。