涉及的几个重要的类:
pandas.core.frame.DataFrame:表示表格数据
pandas.core.series.Series:表示一组数据
data.xlsx数据
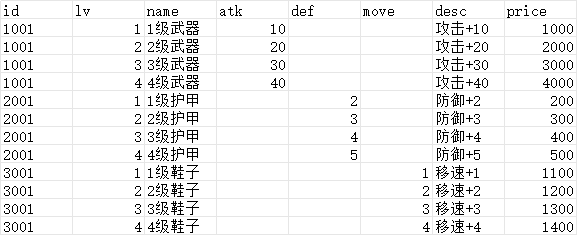
import pandas as pd df = pd.read_excel("./data.xlsx", index_col=None) # index_col表示哪一列作为索引列, 默认是额外加一个列, 用行号作为索引 print(type(df)) # <class 'pandas.core.frame.DataFrame'>, 表格类型数据
基础信息
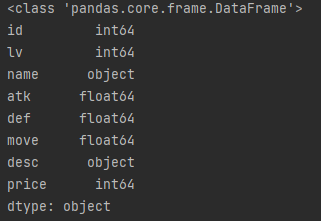
所有列的类型
print(type(df.dtypes)) # <class 'pandas.core.series.Series'> print(df.dtypes)
列类型
print(df["lv"].dtype) # int64 print(df["name"].dtype) # object
索引信息:默认就是指有多少行,从0开始编号
print(type(df.index)) # <class 'pandas.core.indexes.range.RangeIndex'> print(df.index) # RangeIndex(start=0, stop=12, step=1)
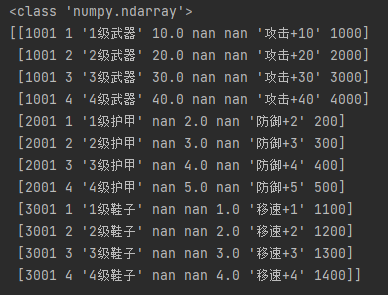
所有数据
print(type(df.values)) # <class 'numpy.ndarray'> print(df.values)
维数
print(type(df.shape)) # <class 'tuple'> print(df.shape) # (12, 8)
表头信息
print(type(df.columns)) # <class 'pandas.core.indexes.base.Index'> print(df.columns) # Index(['id', 'lv', 'name', 'atk', 'def', 'move', 'desc', 'price'], dtype='object') col0 = df.columns[0] # 第1列 print(type(col0)) # <class 'str'> print(col0) # id
筛选列
DataFrame的索引器方式,索引器key的类型:[colName | colName_tuple]
col0 = df.columns[0] col_allRows = df[col0] # 第1列所有数据 print(type(col_allRows)) # <class 'pandas.core.series.Series'> print(col_allRows) print(col_allRows.tolist()) col_allRows = df["id"] # id列所有数据 print(type(col_allRows)) # <class 'pandas.core.series.Series'> print(col_allRows)
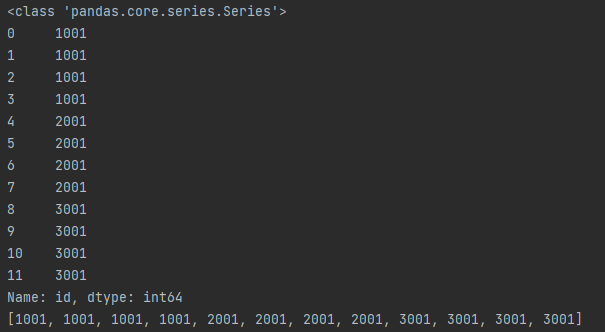
cols_allRows = df[["lv", "name"]] # lv, name列所有数据 print(type(cols_allRows)) # <class 'pandas.core.frame.DataFrame'> print(cols_allRows)
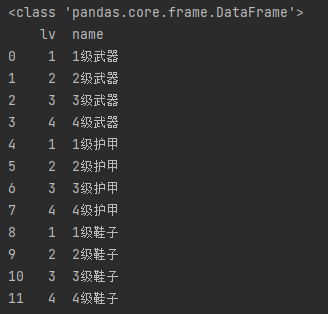
筛选行
a) 开头,结尾
head_rows = df.head(2) # 开头2行数据 print(type(head_rows)) # <class 'pandas.core.frame.DataFrame'> print(head_rows) tail_rows = df.tail(2) # 结尾2行数据 print(type(tail_rows)) # <class 'pandas.core.frame.DataFrame'> print(tail_rows)
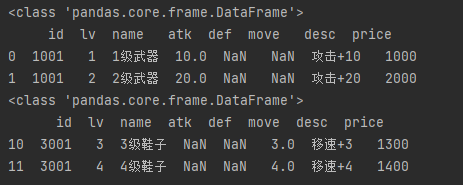
b) DataFrame的索引器方式,索引器key的类型:[row_slice]
rows = df[0:3] # 第1至3行, 所有列。不支持df[0:3, ["lv", "name]] print(type(rows)) # <class 'pandas.core.frame.DataFrame'> print(rows)
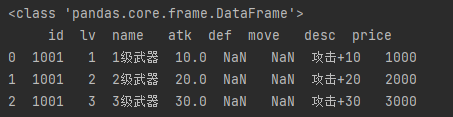
c) df.loc的索引器方式,索引器key的类型:df.loc[row_slice | row_list, colName_list | colName_slice]
row = df.loc[1] # 第2行数据,所有列 print(type(row)) # <class 'pandas.core.series.Series'> print(row)
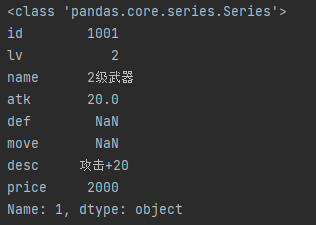
rows = df.loc[:] # 所有行,所有列。也可以写成:df.loca[:, :] print(type(rows)) # <class 'pandas.core.frame.DataFrame'> print(rows) rows = df.loc[1:3] # 第2至3行, 所有列。也可以写成df.loc[1:3, :] print(rows)
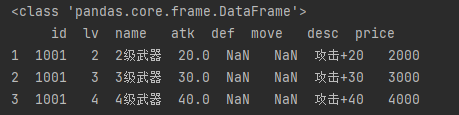
rows = df.loc[1:3, ["lv", "name"]] # 第2至3行, 只需要lv, name列 print(type(rows)) # <class 'pandas.core.frame.DataFrame'> print(rows) rows = df.loc[[0, 2, 5], ["lv", "name"]] # 第1,3,6行, 只需要lv, name列 print(rows)

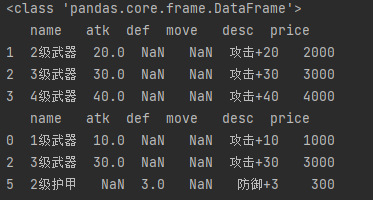
rows = df.loc[1:3, "name":] # 第2至3行, name后的所有列 print(type(rows)) # <class 'pandas.core.frame.DataFrame'> print(rows) rows = df.loc[[0, 2, 5], "name":] # 第1,3,6行, name后的所有列 print(rows)
参考
Pandas :数据分析基本操作(更新中) - 知乎 (zhihu.com)