作业①
要求
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站
输出信息:
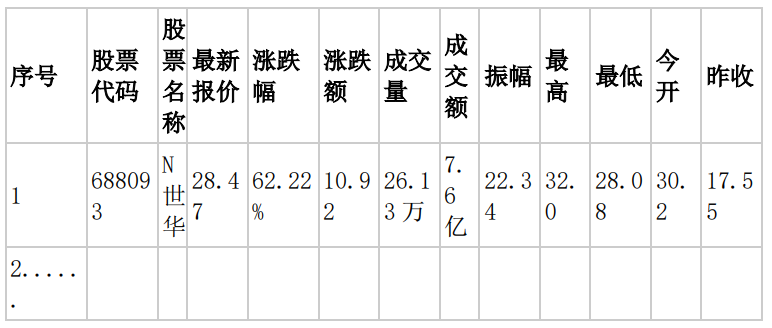
- MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号,id,股票代码:bStockNo……,由同学们自行定义设计表头:
思路
- 之前处理这个网站主要是通过json请求的截获,而Selenium则可以直接爬取网站,不需要翻找页面数据流向找json文件的链接。
代码
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import random
import pymysql
# 声明一个谷歌驱动器,并设置不加载图片,间接加快访问速度
options = webdriver.ChromeOptions()
options.add_experimental_option('prefs', {'profile.managed_default_content_settings.images': 2})
browser = webdriver.Chrome(options=options)
def start_spider(url):
# 请求url
browser.get(url)
# 显示等待商品信息加载完成
WebDriverWait(browser, 1000).until(
EC.presence_of_all_elements_located(
(By.ID, "table_wrapper-table")
)
)
# 将滚动条拉到最下面的位置,因为往下拉才能将这一页的商品信息全部加载出来
browser.execute_script('document.documentElement.scrollTop=10000')
# 随机延迟,等下元素全部刷新
time.sleep(random.randint(3, 6))
browser.execute_script('document.documentElement.scrollTop=0')
# 开始提取信息,找到ul标签下的全部li标签
for link in browser.find_elements(By.XPATH,'//tbody/tr'):
#代码
id_stock = link.find_element(By.XPATH,'./td[position()=2]').text
#股票名
name = link.find_element(By.XPATH,'.//td[@class="mywidth"]').text
#价格
new_price = link.find_element(By.XPATH,'.//td[@class="mywidth2"]').text
#涨跌幅
ud_range= link.find_element(By.XPATH,'.//td[@class="mywidth"]').text
#涨跌额
ud_num = link.find_element(By.XPATH,'./td[position()=6]').text
#成交量
deal_count = link.find_element(By.XPATH,'./td[position()=8]').text
#成交额
turnover = link.find_element(By.XPATH,'./td[position()=9]').text
# 振幅
amplitude = link.find_element(By.XPATH,'./td[position()=10]').text
# 最高
high = link.find_element(By.XPATH,'./td[position()=11]').text
# 最低
low = link.find_element(By.XPATH,'./td[position()=12]').text
# 今开
today = link.find_element(By.XPATH,'./td[position()=13]').text
# 昨收
yesterday = link.find_element(By.XPATH,'./td[position()=14]').text
print(id_stock,name,new_price,ud_range,ud_num,deal_count,turnover,amplitude,high,low,today,yesterday)
conn = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="1234", db="spider_ex", charset="utf8")
# 获取游标
cursor = conn.cursor()
cursor.execute("create table if not exists stocks1(id int AUTO_INCREMENT primary key,id_stock varchar(20),name varchar(20),new_price varchar(20),ud_range varchar(20),ud_num varchar(20),deal_count varchar(20),turnover varchar(20),amplitude varchar(20),high varchar(20),low varchar(20),today varchar(20),yesterday varchar(20))")
# 插入数据,注意看有变量的时候格式
try:
cursor.execute(
"INSERT INTO stocks1(`id_stock`,`name`,`new_price`,`ud_range`,`ud_num`,`deal_count`,`turnover`,`amplitude`,`high`,`low`,`today`,`yesterday`) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)", (id_stock,name,new_price,ud_range,str(ud_num),deal_count,turnover,amplitude,high,low,today,yesterday))
# 提交
except Exception as err:
print("error is ")
print(err)
# 关闭连接
conn.commit()
conn.close()
# 遍历
def main():
# url
str = ['hs','sh','sz']
for i in str:
url = 'http://quote.eastmoney.com/center/gridlist.html#'+i+'_a_board'
start_spider(url)
if __name__ == '__main__':
main()
# 退出浏览器
browser.quit()
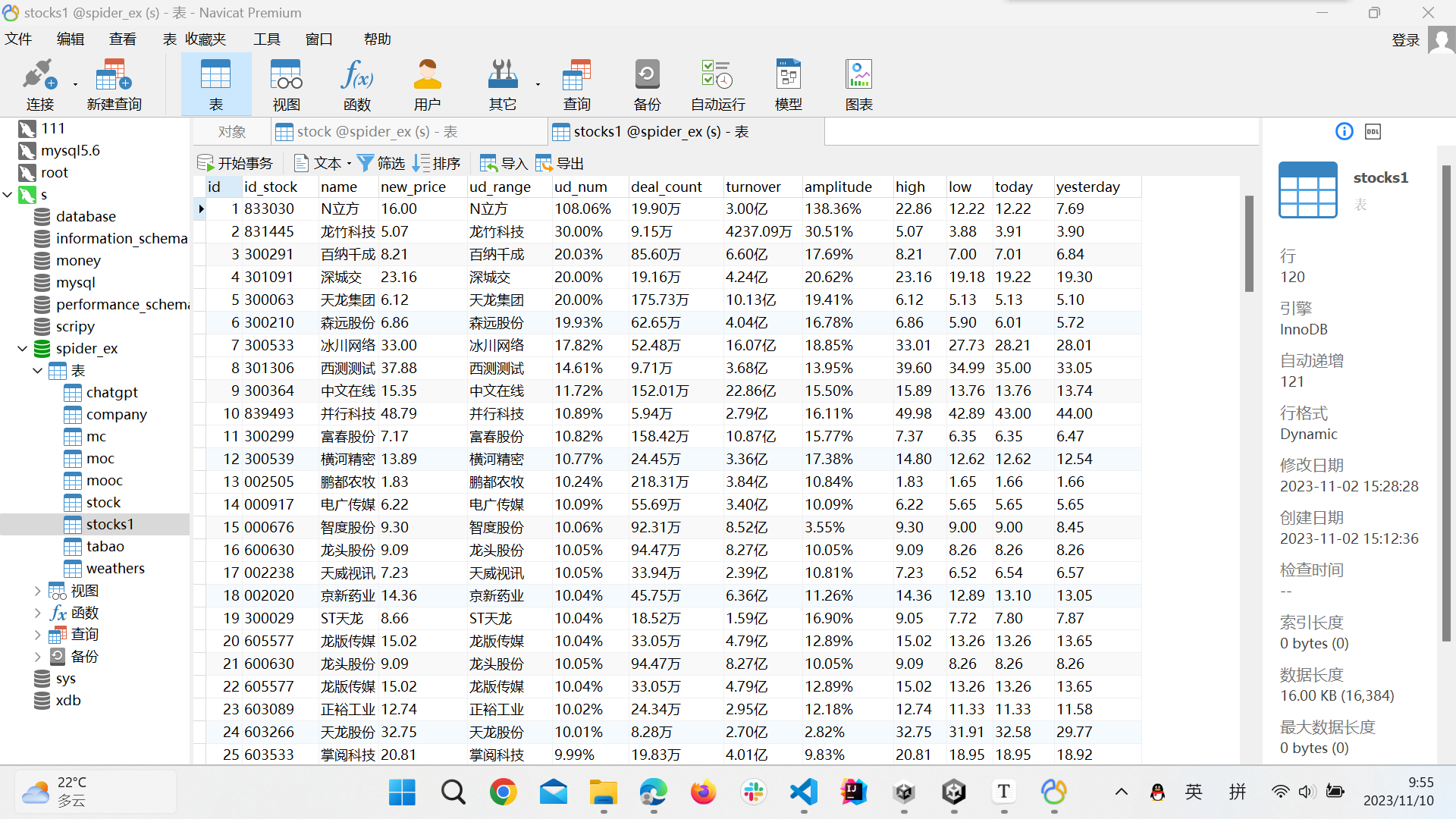
运行截图
心得体会
- 翻页的功能遇到了一点问题,所以干脆用输入页码的形式进行翻页。
- 此外,这个网站要在开盘时间才能爬到数据,且不能过于频繁地爬取数据,容易出现TIME OUT的问题,可能是网站本身的限制。
作业二
要求
- 熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、
- 等待 HTML 元素等内容。
候选网站
输出信息:
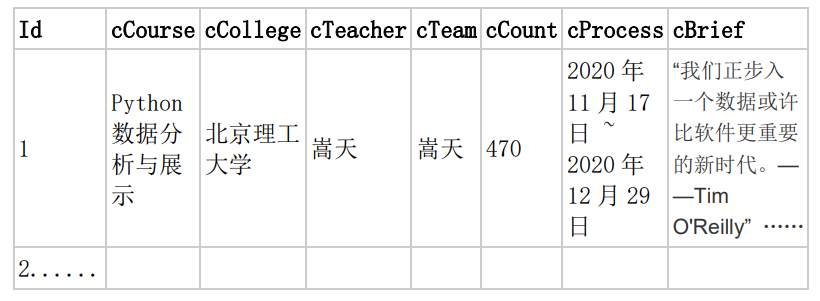
- MYSQL 数据库存储和输出格式
思路
- 由于mooc平台课程过多,于是选择爬取所有的国家精品课程
代码
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import random
import mydb
# 声明一个谷歌驱动器,并设置不加载图片,间接加快访问速度
class Spider(object):
def __init__(self):
self.db = mydb.mydb()
self.url = "https://www.icourse163.org"
self.options = webdriver.ChromeOptions()
self.options.add_experimental_option('prefs', {'profile.managed_default_content_settings.images': 2})
self.db.create("create table if not exists moc(id int AUTO_INCREMENT primary key,course varchar(20),college varchar(20),teacher varchar(20),team varchar(20),count varchar(20),process varchar(20),brief varchar(100))")
def login(self):
driver = webdriver.Chrome(options=self.options)
driver.get(self.url)
wait = WebDriverWait(driver, 10)
element = wait.until(EC.visibility_of_element_located((By.CSS_SELECTOR, ".navLoginBtn")))
loginbutton = driver.find_element(By.CSS_SELECTOR, ".navLoginBtn")
loginbutton.click()
time.sleep(2)
iframe = driver.find_element(By.TAG_NAME, "iframe")
driver.switch_to.frame(iframe)
phone_input = driver.find_element(By.ID, "phoneipt").send_keys("18859436985")
psd_input = driver.find_element(By.CSS_SELECTOR, ".j-inputtext").send_keys("111111111")
loginbutton = driver.find_element(By.ID, "submitBtn")
loginbutton.click()
time.sleep(5)
driver.switch_to.default_content()
return driver
def start_spider(self):
driver = self.login()
input_element = driver.find_element(By.XPATH, "//input[@name='search']")
input_element.send_keys("大数据") # 输入要搜索的文本
nextbutton = driver.find_element(
By.CSS_SELECTOR, 'span[class="u-icon-search2 j-searchBtn"]')
nextbutton.click()
for i in range(1,6):
WebDriverWait(driver, 1000).until(
EC.presence_of_all_elements_located(
(By.ID, "j-courseCardListBox")
)
)
driver.execute_script('document.documentElement.scrollTop=10000')
time.sleep(random.randint(3, 6))
for link in driver.find_elements(By.XPATH,'//div[@class="u-clist f-bgw f-cb f-pr j-href ga-click"]'):
course_name = link.find_element(By.XPATH,'.//span[@class=" u-course-name f-thide"]').text
print("course name ",course_name)
try:
school_name = link.find_element(By.XPATH,'.//a[@class="t21 f-fc9"]').text
print("school ", school_name)
except Exception as err:
school_name = "can't find school"
#主讲教师
try:
m_teacher = link.find_element(By.XPATH,'.//a[@class="f-fc9"]').text
print("teacher:", m_teacher)
except Exception as err:
m_teacher = 'no teacher'
#团队成员
try:
team_member = link.find_element(By.XPATH,'.//span[@class="f-fc9"]').text
except Exception as err:
team_member = 'only'
print("团队:",team_member)
#参加人数
try:
join = link.find_element(By.XPATH,'.//span[@class="hot"]').text
join.replace('参加','')
print("参加人数",join)
except Exception as err:
join = '0'
#课程进度
try:
process = link.find_element(By.XPATH,'.//span[@class="txt"]').text
print('进度 ',process)
except Exception as err:
process = 'no process'
#课程简介
try:
introduction = link.find_element(By.XPATH,'.//span[@class="p5 brief f-ib f-f0 f-cb"]').text
print(introduction)
except Exception as err:
introduction = 'no introduction'
try:
self.db.insert("INSERT INTO moc(`course`,`college`,`teacher`,`team`,`count`,`process`,`brief`) VALUES (%s,%s,%s,%s,%s,%s,%s)",(course_name,school_name,m_teacher,m_teacher+team_member,join,process,introduction))
except Exception as err:
print("error is ")
print(err)
nextbutton = driver.find_element(
By.CSS_SELECTOR, 'li[class="ux-pager_btn ux-pager_btn__next"]')
nextbutton.click()
# self.db.__del__()
driver.quit()
if __name__== "__main__":
spider = Spider()
spider.start_spider()
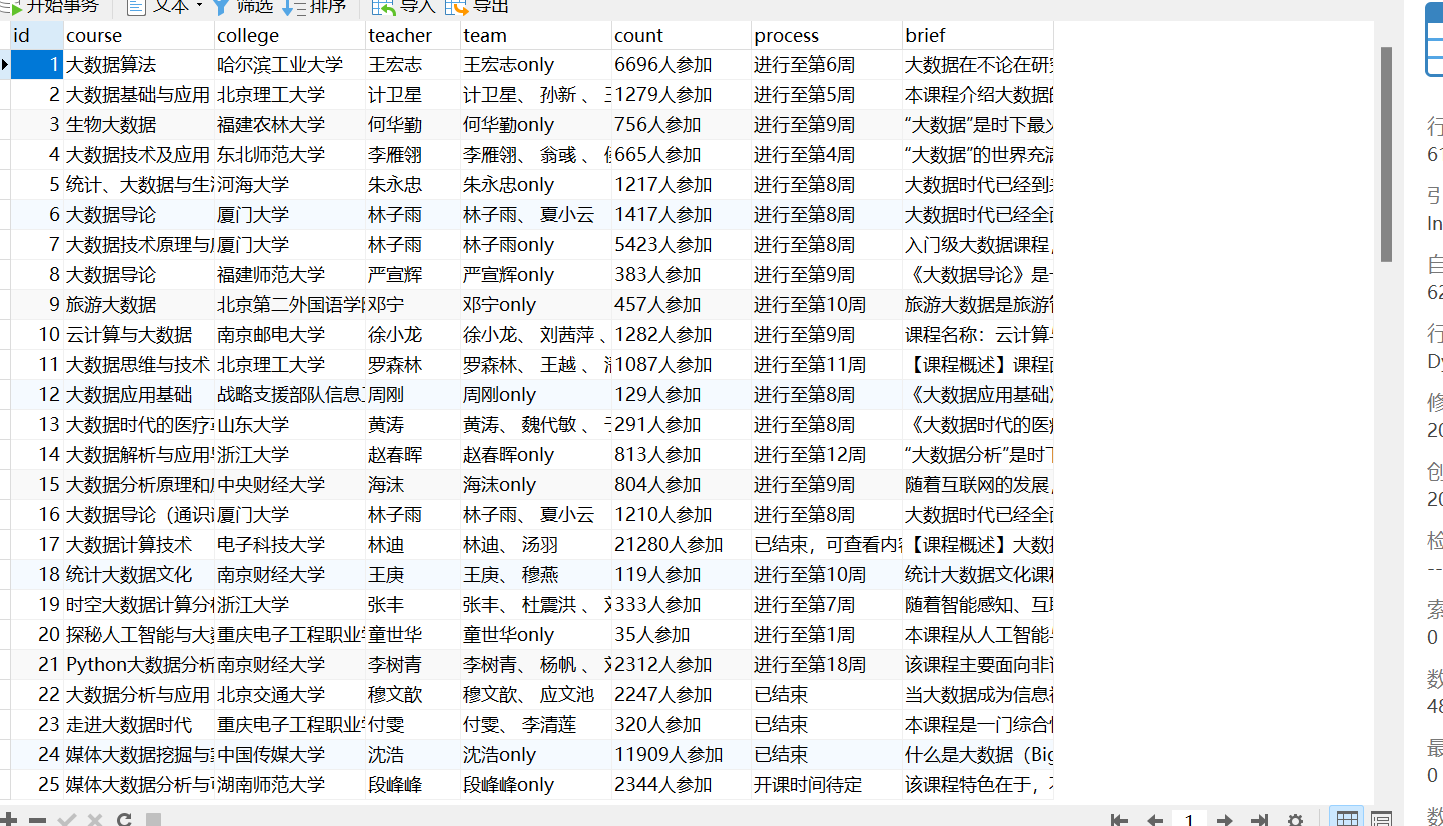
运行截图
心得体会
- switch_to.frame(),然后才可以查找输入框元素。
- driver.switch_to.default_content()然后返回
作业③
要求
- 掌握大数据相关服务,熟悉 Xshell 的使用
- 完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档。
环境搭建
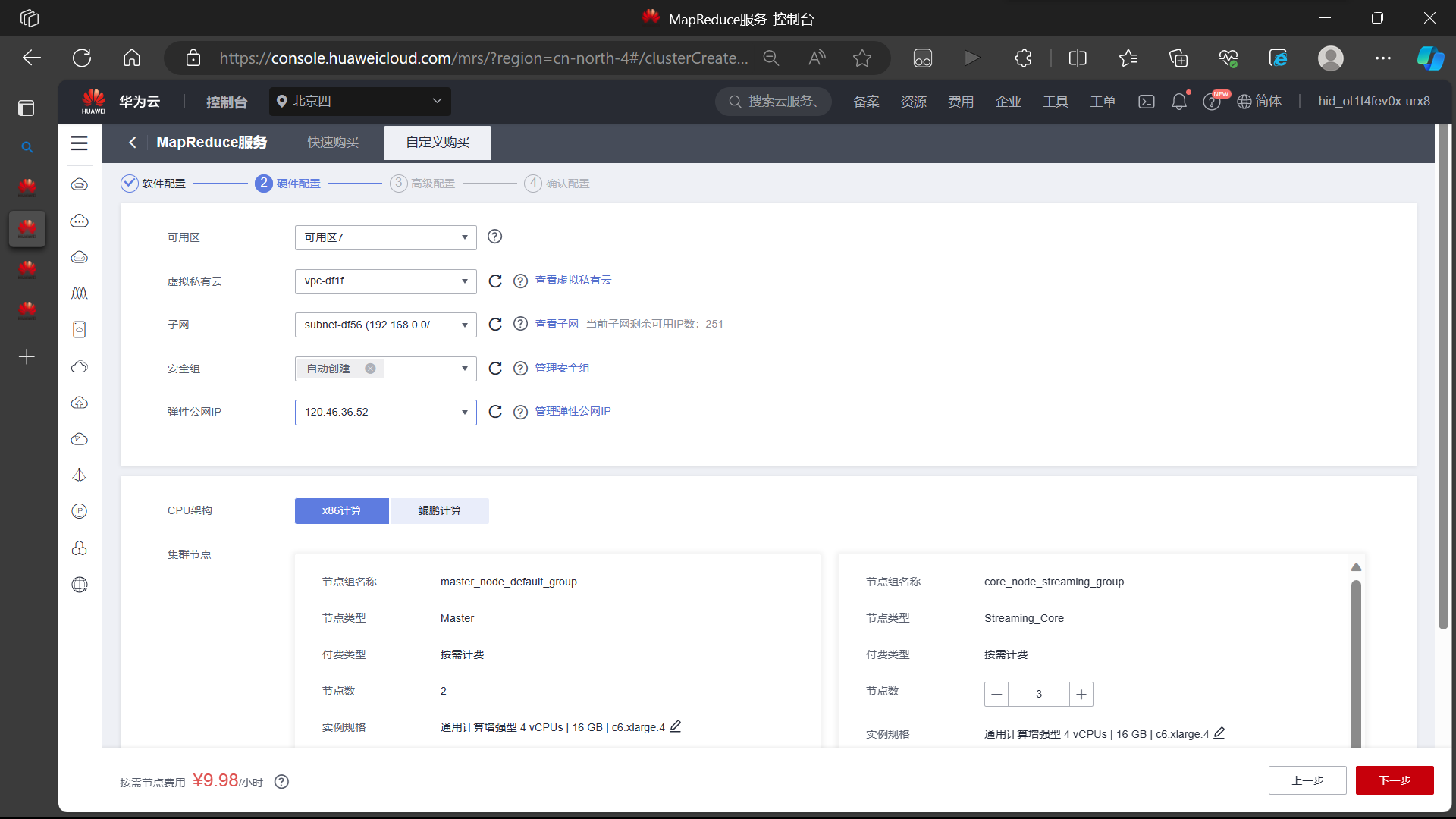
- 开通 MapReduce 服务
实时分析开发实战
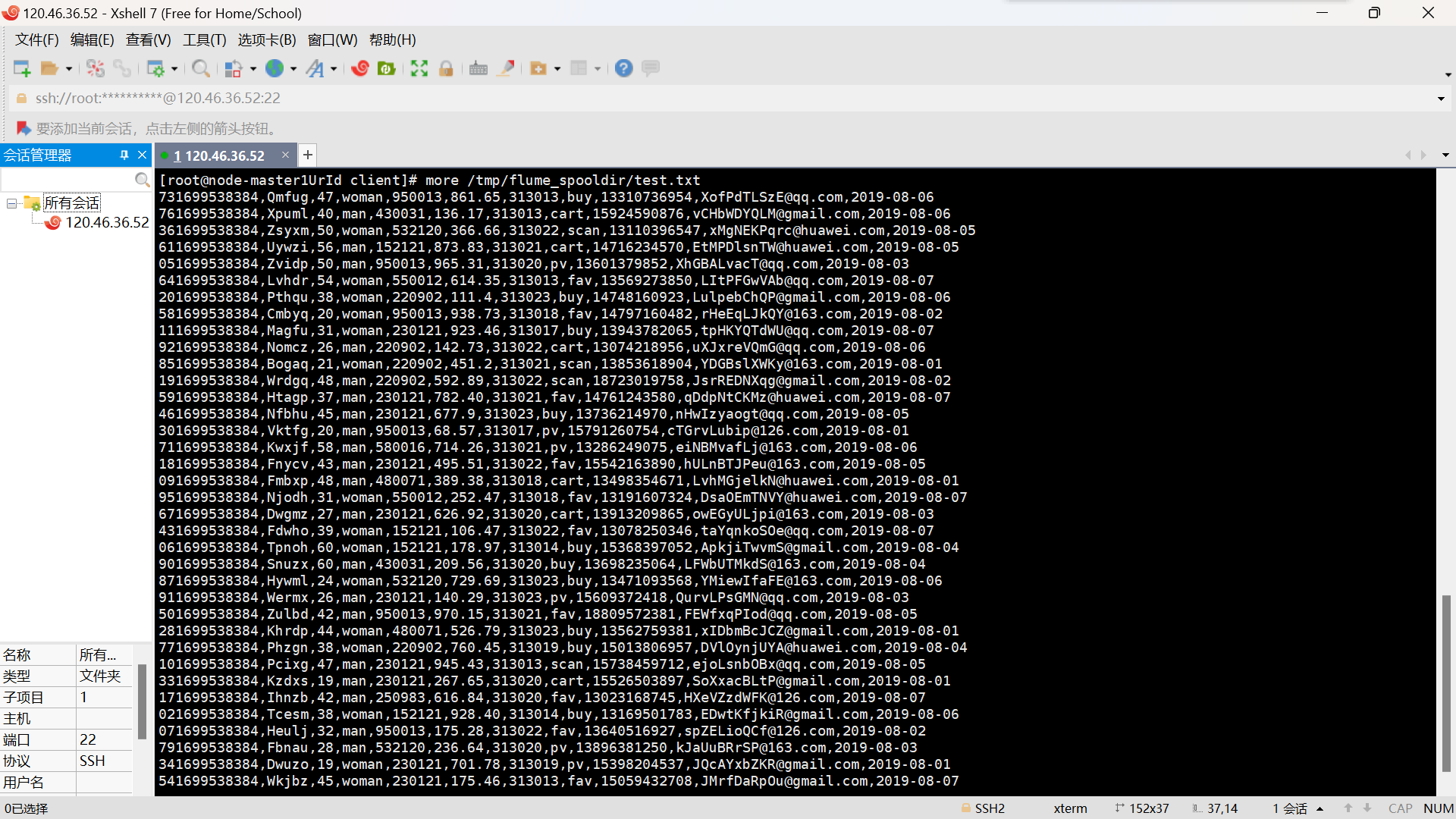
- 任务一:Python 脚本生成测试数据
- 任务二:配置 Kafka

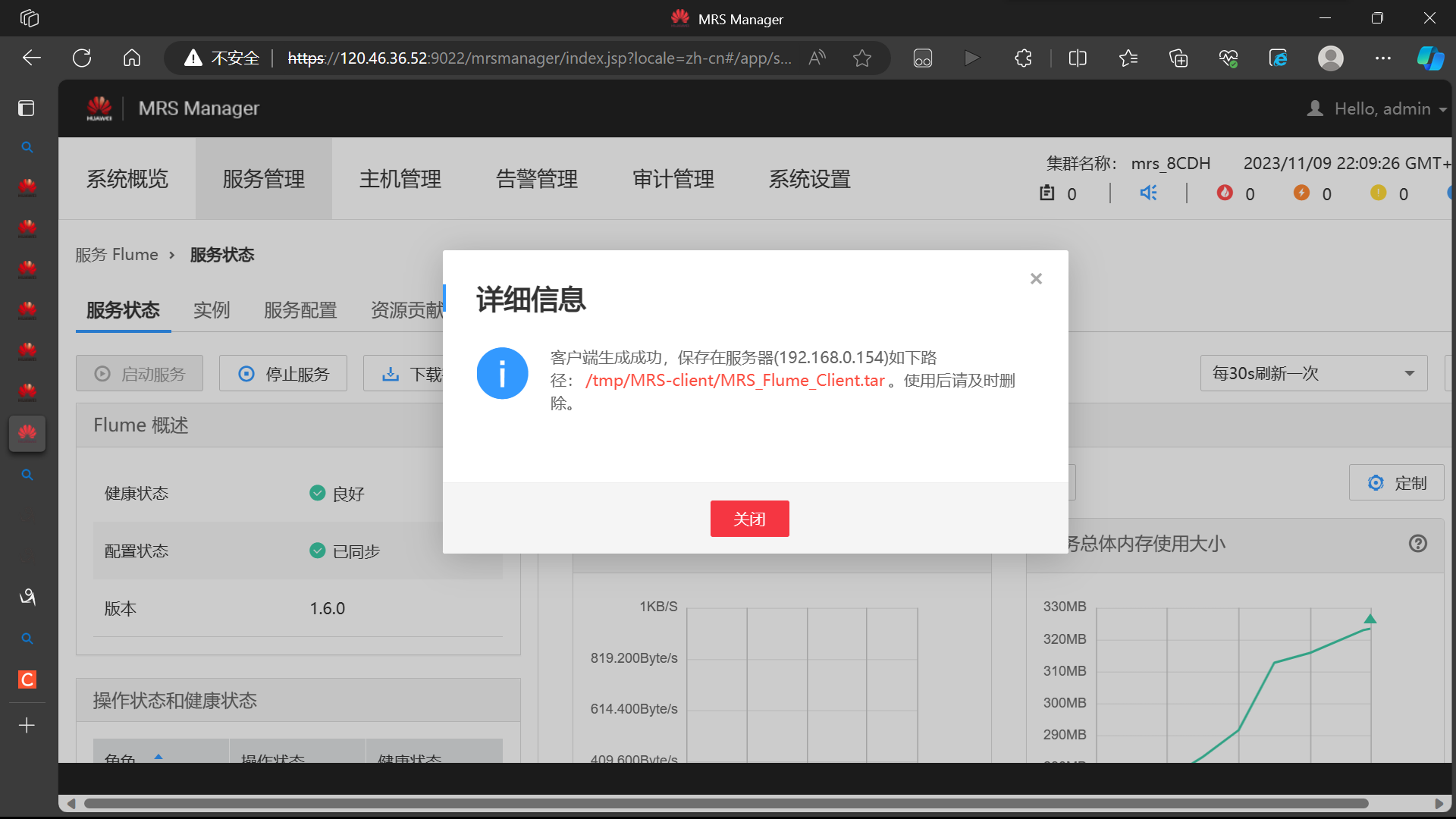
- 任务三: 安装 Flume 客户端
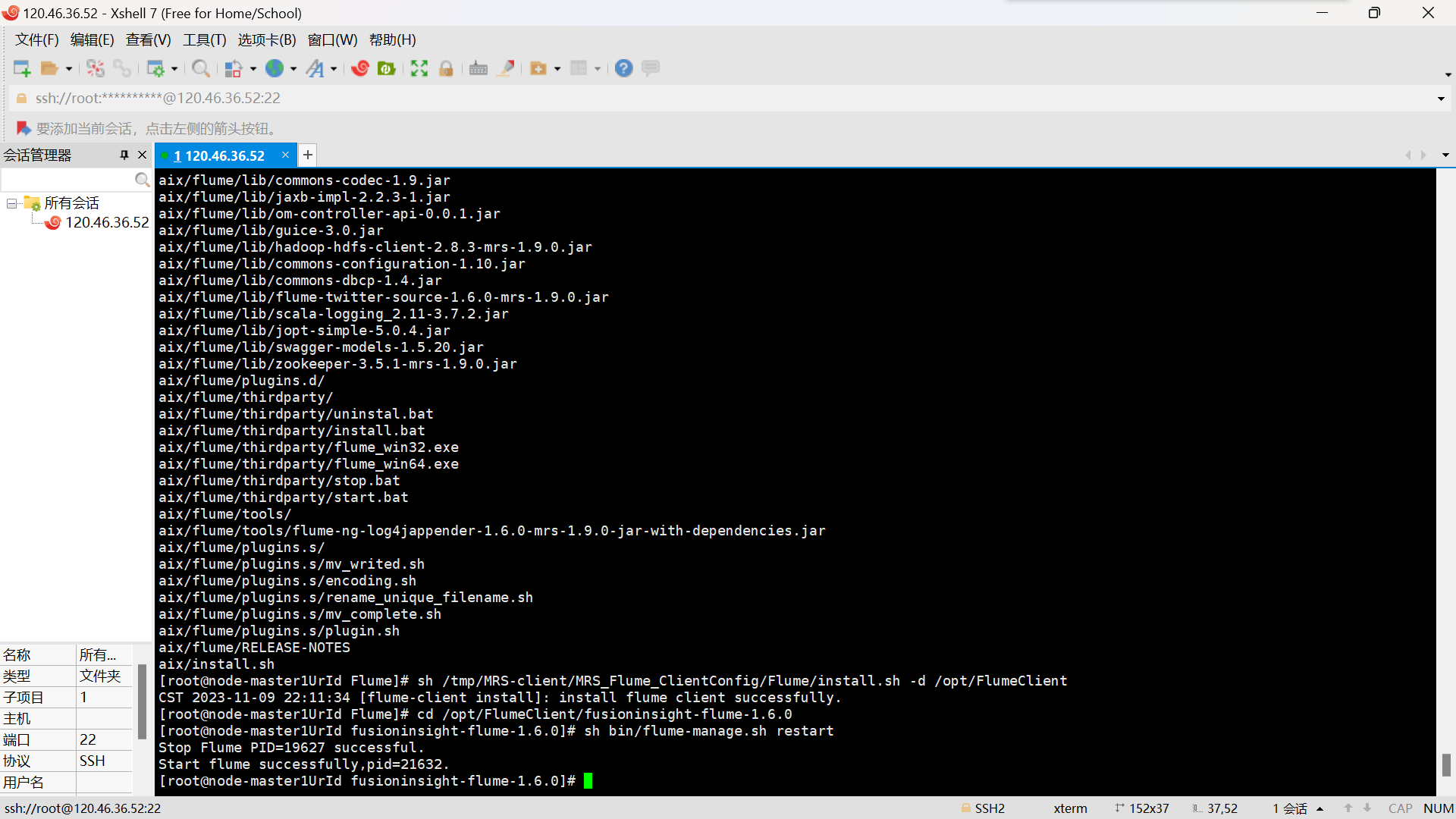
- 任务四:配置 Flume 采集数据
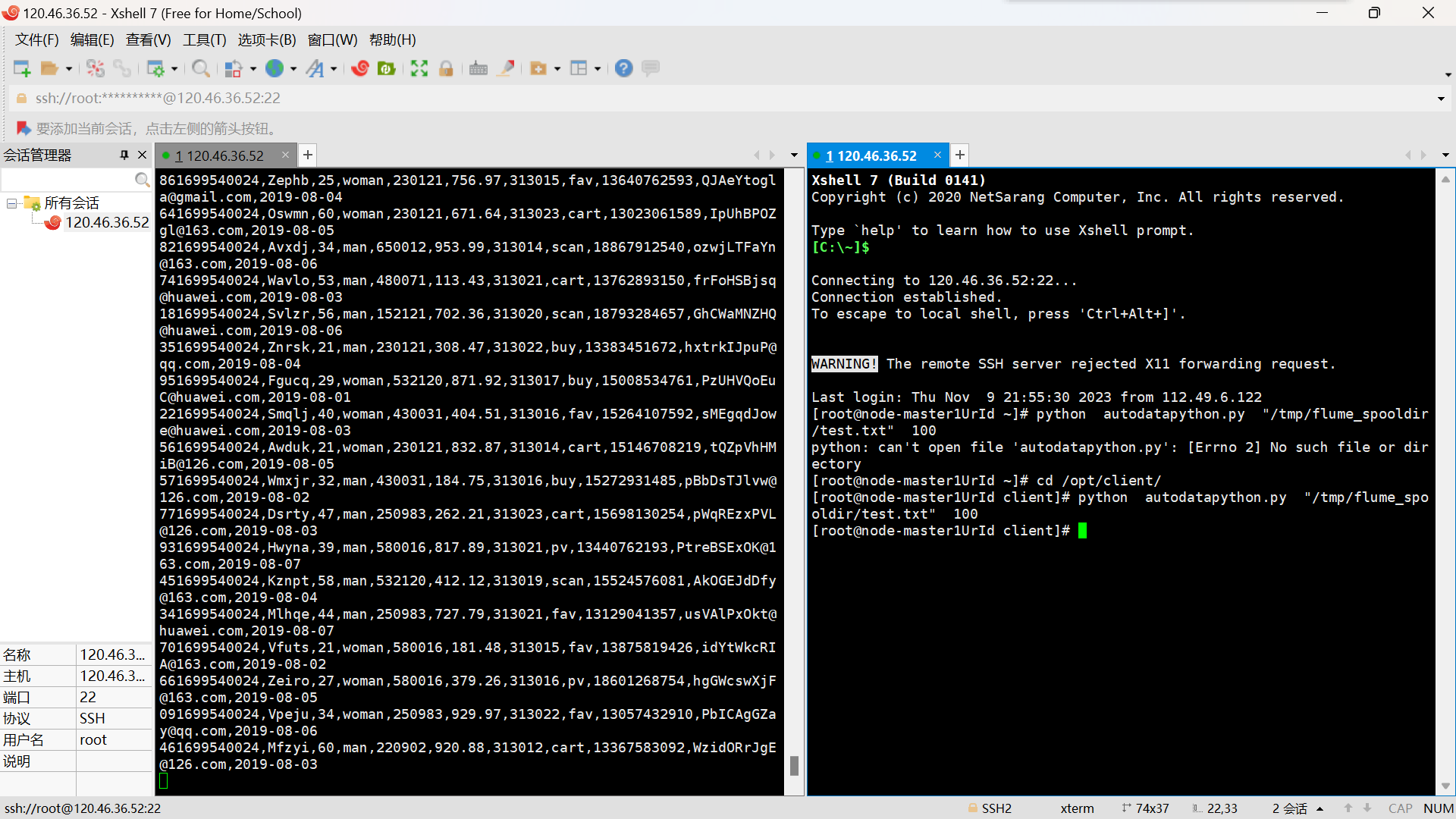
心得体会
- 学会了运用华为公有云的MRS服务,了解了Flume的作用和环境搭建的过程。
- 跟着老师的教程走,虽然版本变化了,但还是非常顺利地完成了。
- 初步了解了一下Xshell连接服务器,了解了Flume的作用和环境搭建的过程。。