XGBOOST
gbdt和lightgbm,xgboost的区别
GBDT将目标函数泰勒展开到一阶,而xgboost将目标函数泰勒展开到了二阶
GBDT是给新的基模型寻找新的拟合标签(前面加法模型的负梯度),而xgboost是给新的基模型寻找新的目标函数(目标函数关于新的基模型的二阶泰勒展开)
xgboost加入了和叶子权重的L2正则化项,因而有利于模型获得更低的方差。
xgboost增加了自动处理缺失值特征的策略。通过把带缺失值样本分别划分到左子树或者右子树,比较两种方案下目标函数的优劣,从而自动对有缺失值的样本进行划分,无需对缺失特征进行填充预处理。
XGBoost采用了Shrinkage 和Column Subsampling方法,这两种方法都能在一定程度上防止过拟合
XGBoost为什么要二阶泰勒展开、叶子节点的权重怎么确定的?怎么分裂节点?
统一损失函数求导的形式以支持自定义损失函数,二阶信息本身就能让梯度收敛更快更准确
当前叶子上所有样本的一阶梯度和二阶梯度计算当前叶子的权重。$w_{i}$ 是当前数的第i个叶子节点,$g_{i}$ 是落在第j个叶子节点的第i个样本的一阶梯度,$h_{i}$ 是落在第j个叶子节点的第i个样本的二阶梯度, $\lambda $ 是正则项
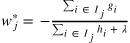
遍历所有的特征,从每个特征中找出最优的分裂点,最优分裂点是选按照此点分裂后,计算 (左树叶子节点得分 + 右树叶子节点得分 - 不分裂的叶子节点得分),取能得到最大值的点(也就是损失函数减少最多的)。

LGB和XGBoost的损失函数相同吗?LGB有什么特点?
(1)采用goss算法减少样本,(2)采用互斥特征捆绑较少特征,以便于计算,(3)先是树的生长策略level/leaf wise;(4)然后节点分裂的算法-直方图算法/预排序算法; 工程上的优化:(1)支持类别特征(2)高效并行:特征并行 、数据并行、投票并行(3)cache命中率优化
20道XGBoost面试题
https://mp.weixin.qq.com/s/a4v9n_hUgxNyKSQ3RgDMLA
特征工程和评价指标
项目特征工程选取显著变量。显著的评判依据是什么
auc,f1,recall,precision对正负样本比例是否敏感?如果有两个模型,一个随机预测,一个全预测为负,这些指标有什么变化?那你觉得现在他们还对正负样本敏感吗?
神经网络
为什么用Resnet,为什么残差连接有效,怎么避免过拟合
CNN比全连接有什么好处
梯度爆炸、梯度消失怎么办
优化器sgd和adam,我从反向介绍公式,然后面试官让我从正向思考 已经有了sgd,为什么要设计adam?然后我又正向介绍为什么会改进出这么一个优化器。
lr的参数初始化为全0有什么问题
逻辑回归怎么推导的,其和极大似然的关系,它的损失函数是什么,为什么用这个损失函数?
手撕:最大乘积子数组
手撕:三树之和
手撕:环形房屋偷窃
双端队列BFS,cpp可以用deque实现
leetcode 150. 逆波兰表达式求值
梯度下降求平方根,力扣只有二分和拟牛顿写法,写了好久靠面试官提示写出来了。。
def sqrt(y):
xt=0.0001
l=0.001
thresh=0.001
while abs(xt*xt-y)>=thresh:
loss=1.0/2*(xt*xt-y)**2
dx=(xt*xt-y)*2*xt
xt=xt-l*dx
return xt
股票冷冻期
有一个数组和target,你可以对每个数组设置正负,求有多少种设置组合使数组和为target
code 环形打家劫舍