回归
回归(regression)是能为一个或多个自变量与因变量之间关系建模的一类方法。 在自然科学和社会科学领域,回归经常用来表示输入和输出之间的关系。
在机器学习领域中的大多数任务通常都与预测(prediction)有关。 当我们想预测一个数值时,就会涉及到回归问题。 常见的例子包括:预测价格(房屋、股票等)、预测住院时间(针对住院病人等)、 预测需求(零售销量等)。 但不是所有的预测都是回归问题。 在后面的章节中,我们将介绍分类问题。分类问题的目标是预测数据属于一组类别中的哪一个。
线性回归
线性回归(linear regression)可以追溯到19世纪初, 它在回归的各种标准工具中最简单而且最流行。 线性回归基于几个简单的假设: 首先,假设自变量和因变量<span class="math notranslate nohighlight">之间的关系是线性的, 即<span class="math notranslate nohighlight">可以表示为<span class="math notranslate nohighlight">中元素的加权和,这里通常允许包含观测值的一些噪声; 其次,我们假设任何噪声都比较正常,如噪声遵循正态分布。
为了解释线性回归,我们举一个实际的例子: 我们希望根据房屋的面积(平方英尺)和房龄(年)来估算房屋价格(美元)。 为了开发一个能预测房价的模型,我们需要收集一个真实的数据集。 这个数据集包括了房屋的销售价格、面积和房龄。 在机器学习的术语中,该数据集称为训练数据集(training data set) 或训练集(training set)。 每行数据(比如一次房屋交易相对应的数据)称为样本(sample), 也可以称为数据点(data point)或数据样本(data instance)。 我们把试图预测的目标(比如预测房屋价格)称为标签(label)或目标(target)。 预测所依据的自变量(面积和房龄)称为特征(feature)或协变量(covariate)。
线性模型

损失函数
在开始寻找最好的模型参数(model parameters)w和b之前, 我们还需要两个东西: (1)一种模型质量的度量方式; (2)一种能够更新模型以提高模型预测质量的方法。
在我们开始考虑如何用模型拟合(fit)数据之前,我们需要确定一个拟合程度的度量。损失函数(loss function)能够量化目标的实际值与预测值之间的差距。 通常我们会选择非负数作为损失,且数值越小表示损失越小,完美预测时的损失为0。
回归问题中最常用的损失函数是平方误差函数。
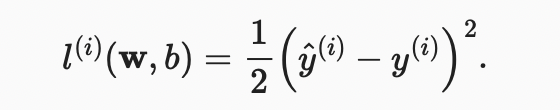
常数1/2不会带来本质的差别,但这样在形式上稍微简单一些 (因为当我们对损失函数求导后常数系数为1)。