果园浇水服务作为果园项目的P0级别死保服务,因业务场景需要,具有qps高,功能多,负载大的特点。早先的浇水服务偶有超时现象,发现接口超时大多时候,数据库有建连操作。线上机器31台,YZ和ZW各有15,16台,单实例8c16g。
后续为了响应公司计划,将机器缩容至YZ和ZW机房各4台,单实例4c16g。浇水接口的性能问题,因为缩容而放大了。根据我们的QPS估计,理论上讲,8台机器完全可以承载线上请求。
实际情况是:当核数缩至4c后,cpu不足以处理请求,ktrace和日志中均存在无法追踪的停顿(无日志),高峰期由于请求处理不过来,grpc连接池被撑爆。
在此情况下,为了排查接口问题,并确定问题的产生,过程中对几个资源池进行了优化,优化后接口响应及早晚高峰的情况有所改观,但未能彻底解决早晚高峰请求处理不过来的问题。最后把核数恢复8core。由于grpc线程池不再被撑爆,线程池活跃线程数始终在***以下,于是调整了一下grpc线程池大小,接口响应明显降低。
之后不再出现无法追踪的超时报警,且延迟请求曲线正常情况下表现平缓稳定,接口优化有了阶段性的成果。
解决问题
一:合理配置线程池资源
场景
接口超时的突刺经常出现在数据库建立连接时,优先解决这个问题就涉及到了合理配置资源线程池。
通过服务监控发现redis和mysq的连接一直不停在建立,之后排查发现我们一直使用的是默认的线程池。
夸张的情况像这样:
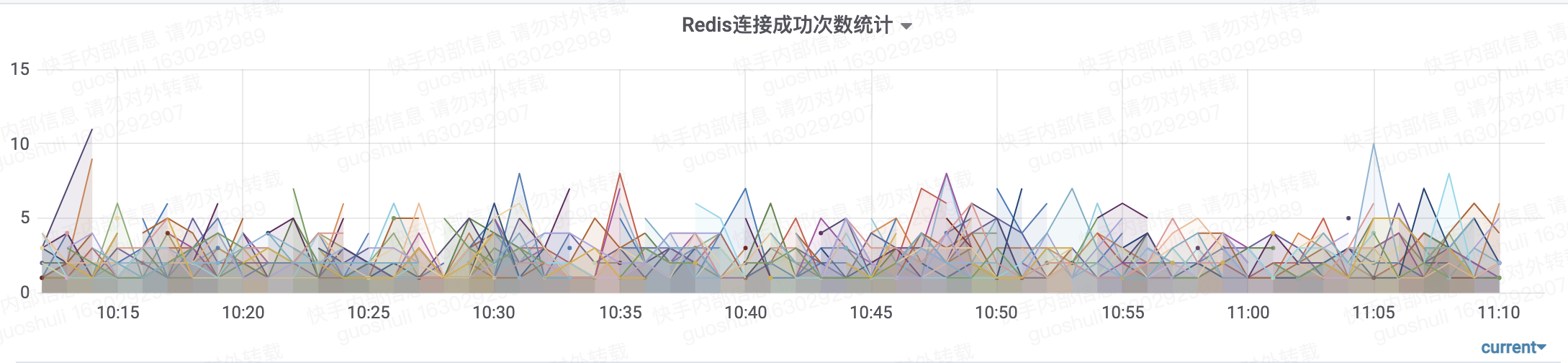
因此对数据库资源池,连接数,keep-alive时长等进行了配置优化,针对不同服务对数据库的使用情况进行了定制化配置。
理论
合理配置线程池可以有效地减少内存及CPU开销,当我们和数据库创建连接时,如果每次都需要重新创建线程和连接,不仅会消耗内存,造成不必要的资源浪费,多个线程导致CPU在线程上下文上的切换开销增大,使CPU资源紧张,同时也会增加JVM的回收频率,对程序造成一定的影响。频繁创建&回收连接,会阻塞持续打过来的请求,进而拖慢服务响应。
何为合理配置,背书方式告诉我们区分IO密集型及CPU密集型、混合型。根据不同操作选择:
CPU密集型:线程池核心数 = CPU核心数+1线程
IO密集型:因为处理IO的时间不会占用CPU,因此可以根据使用多配置一些线程。
鉴于我们大多操作既有IO也有CPU,没必要教条跟核心数扯上太多关系。利特尔法则更适合实操场景,利特尔法则提出了这样一个理论:L = λW
L表示一个系统的任务数,λ表示任务入队频率,W代表任务系统中平均的等待时间。
用个知乎上的例子来说明一下:
- 已知你正在就读的大学每年从全国各地招收2000名学生, 每名学生均需要4年才能毕业离校,请估算目前在你们大学就读的学生总人数。
这道题目的答案是8000 (2000 * 4), 原因是你的大学一直保持着4年招收学生的人数,而每年学校招收2000人,因此得出答案。
所以,我们在估算线程数时,最好是按一段时间内的真实任务数来估算线程池大小。
有个比较常见的场景是,线程池设置得很大,然而线程池过大在一些场景反而会导致程序性能下降。CPU资源、内存资源、I/O资源都是有限的,过大的线程池,过多的负载需求反而可能导致资源临界,导致性能低下;同时,核心线程不会被销毁,大量闲置的线程资源在回收中不停被标记,也会有一定程度影响程序响应。
综上,我们要对默认的连接池进行调整,用以适配真实服务场景,并且对资源连接时间进行优化,能保持合理的数据库连接数不被释放,不用在每日晚上低流量时连接释放,早上流量打进来频繁建连导致性能拖垮。
mysql线程池调整
- 配置
- 默认配置
- KDB查看资源配置在这里,这里配置的值是公共配置,如果想对不同服务配置,需要去Kconf中进行灰度配置

- Kconf配置路径:
- Ks官方指导:https://wiki.corp.kuaishou.com/pages/viewpage.action?pageId=865245419
- Ks官方指导:数据源配置刷新
- https://kconf.corp.kuaishou.com/#/mysql/dataSourceClientConfig/
- 配置方式
- 配置方式在官方指导里说明得很清晰,设置的connection指的是单实例对每一个库的连接数,主要关注三个参数,以下为默认值
"maxConnection": 100,
"minConnection": 0,
"idleTimeoutMs": 1h
从默认配置我们得到一个结论,如果我们使用默认配置:最大连接数是100,最小连接数是0,当1小时连接不被使用,连接就会被释放。同redis配置一样,过一晚上,大部分连接都会失效。
- 观察监控

- 以及资源池

- 配置
- 方式和redis一样,利用一段时间的total连接数除以实例数量
- minConnection = total / 实例数量
- 重复步骤直到高峰期不会频繁建连,如上两张图一样
- 如果不想连接被释放,minConnection要调大
改造后的P995监控在高峰期没有产生突刺
redis线程池适配
- 配置
- cronus代码配置类:
- 服务启动时会根据集群配置对客户端进行初始化
JedisClusterByZooKeeper(AvailableZone az, JedisClusterConfig clusterConfig,Supplier<? extends ILogTopic> oldReplicaTopic) {}
- 能重写的方法(定制的属性)有限,只能定义operationTimeout即socketTimeoutMs
- 客户端资源池属性配置类:RedisClientConfig
- 初始化:这个方法里指定了一种从kconf读取配置方式
static ConfigAdaptor<RedisConfigModel.RedisClientConfig> getCoverRedisClientConfig(JedisClusterConfig config) {}
- 默认配置:
//从这个方法找到的
static GenericObjectPoolConfig getObjectPoolConfig(@Nullable JedisClientConfig jedisClientConfig) {}
//默认配置是这个
Integer poolMaxTotal = 100;
Integer poolMaxIdle = 100;
Integer poolMinIdle = 0;
Long poolMaxWaitMs = 2s;
Long poolMinEvictableIdleTimeMillis = -1;
Long poolTimeBetweenEvictionRunsMillis = 10min;
Integer connectTimeoutMs = 2000;
Integer socketTimeoutMs = 8000;
从默认配置我们得到一个结论,如果我们使用默认配置:最大连接数是100,最小连接数是0,当10分钟连接不被使用,连接就会被释放。
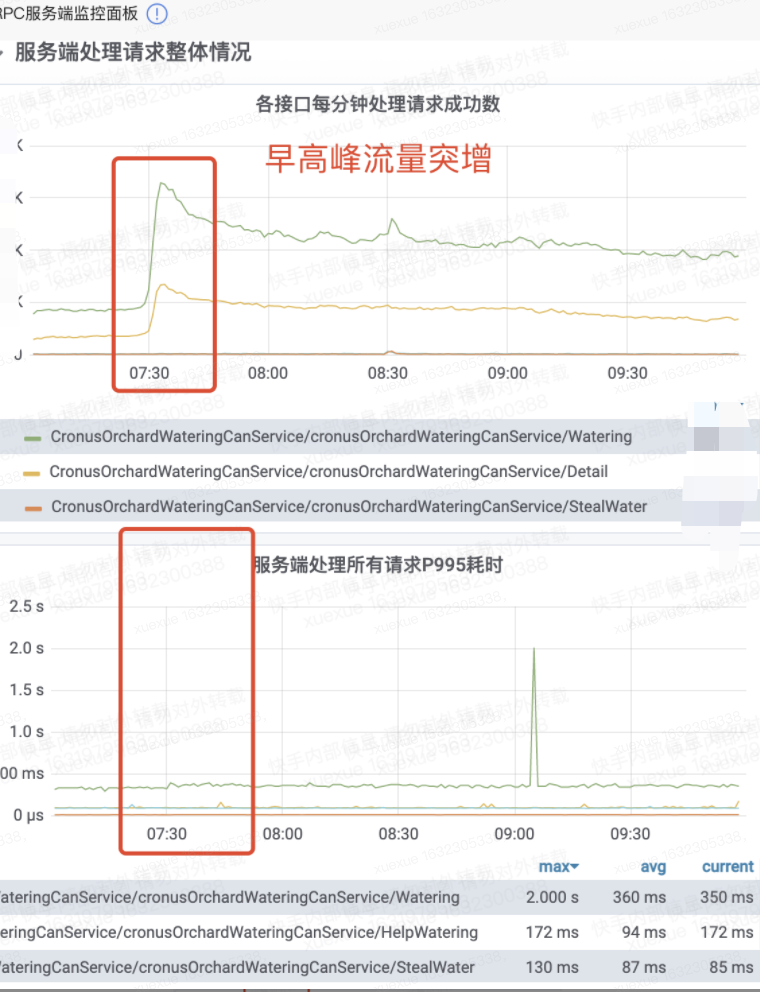
而浇水服务特点之一就是,qps在夜里达到低谷,早上7:30左右一分钟qps翻倍甚至多倍。那么连接池的大多资源已被释放,在流量激增时,便开始频繁建立连接,占用了本不需要重新分配的IO资源和CPU资源。

- 资源池(链接)
当时的现场已经在裂变平台侧不好找了,下面是一个使用默认资源池的资源池使用监控
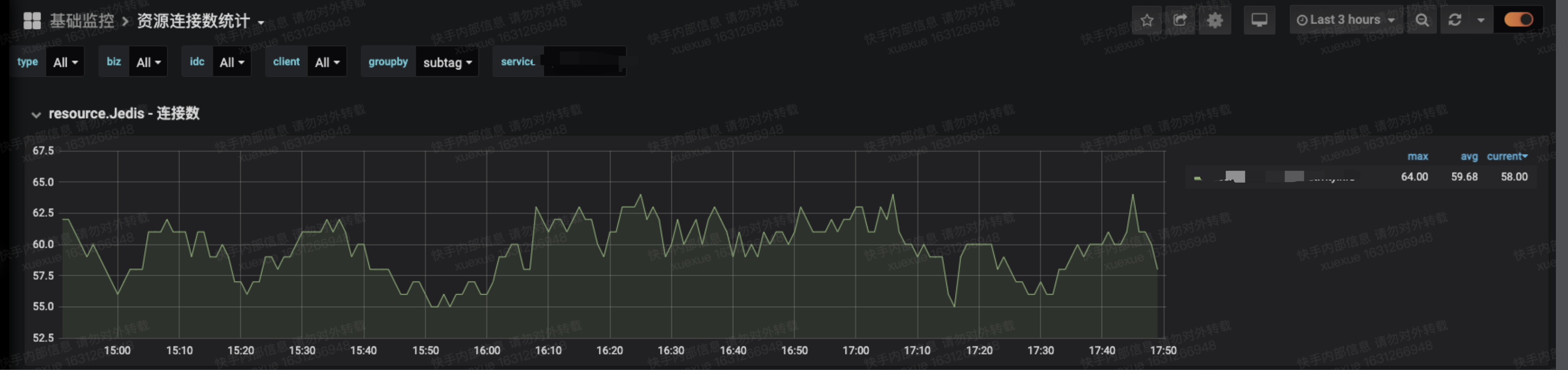
- 配置
比方我们观察到早高峰有一波建连,或服务的建立连接情况类似于下图

a. 选中建连比较频繁的一段监控(表象明显,从无到有,持续一段时间,然后又变无),如果像上图一样建连很规律很平均,就选择释放连接时间(默认的poolTimeBetweenEvictionRunsMillis = 10min)打开此表的edit页面,选中total配置,查看这段时间总共创建了多少次连接。
b. poolMinIdel = total / 实例个数,其他配置酌情配置,poolMinIdel这个参数的关键处在于,无论空闲多久都不会被释放
c. 创建完后,继续观察监控,一个是redis链接成功次数统计中,建连依然频繁,或是资源池跟上面一样起起伏伏,那么说明poolMinIdel还不够大,我们再继续重复a步骤,直到这样
(以下为浇水服务)

以及

Grpc线程池 & 自定义业务线程池配置
- 配置
- 官方文档:https://infra.corp.kuaishou.com/02-service-governance/09-service-governance-framework/03-service-governance-java/02-service-governance-java-guide/14-server-thread-model.html
- 监控
- https://grafana.corp.kuaishou.com/d/_p-WFFaGk/java-fu-wu-xian-cheng-chi-jian-kong
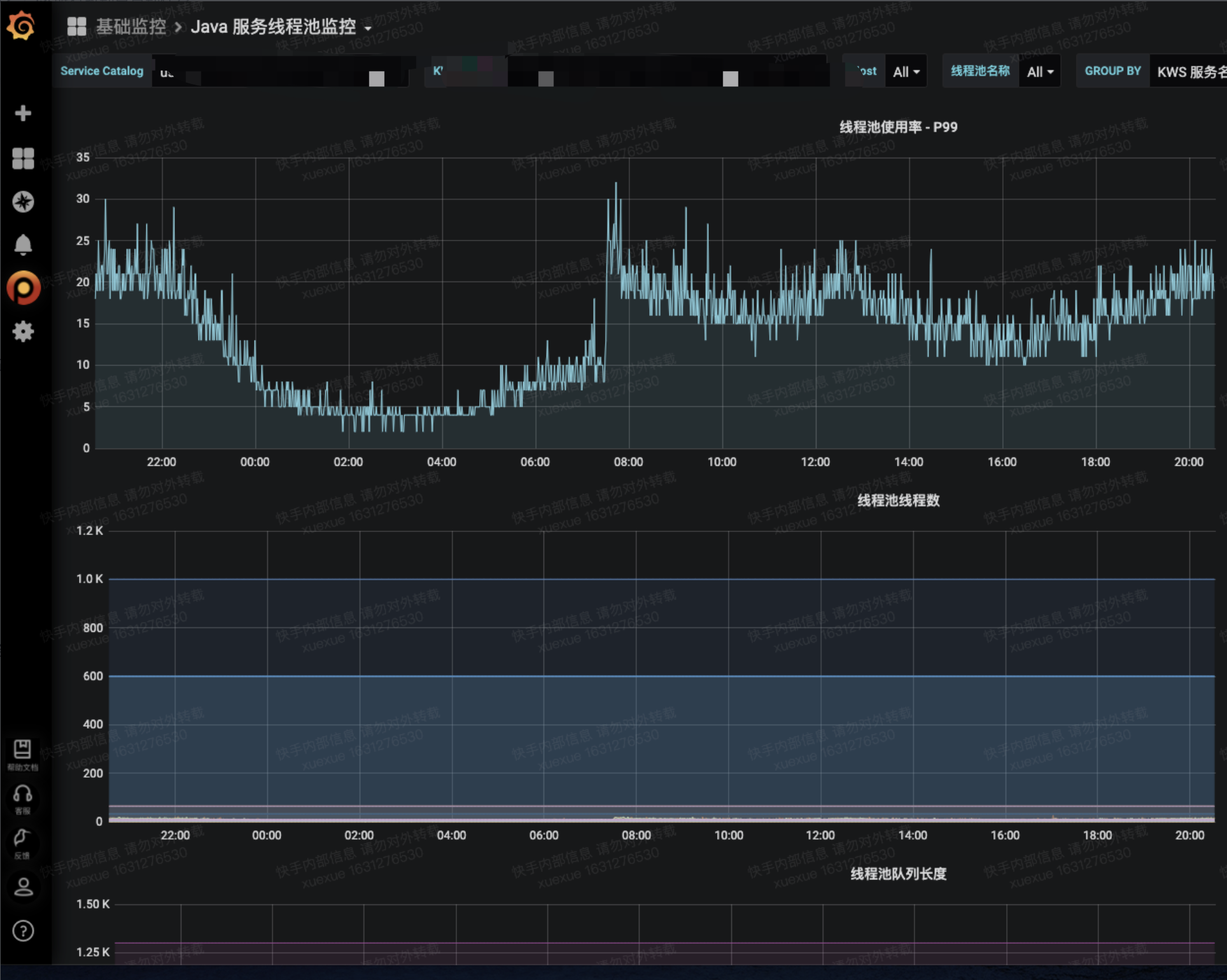
- 配置方式
- 尽可能大地利用线程池,不要浪费资源,使用率留有一定buffer即可,比如浇水服务线程池是这样的,从核心线程数600,队列长度300,改为核心线程数64,队列128
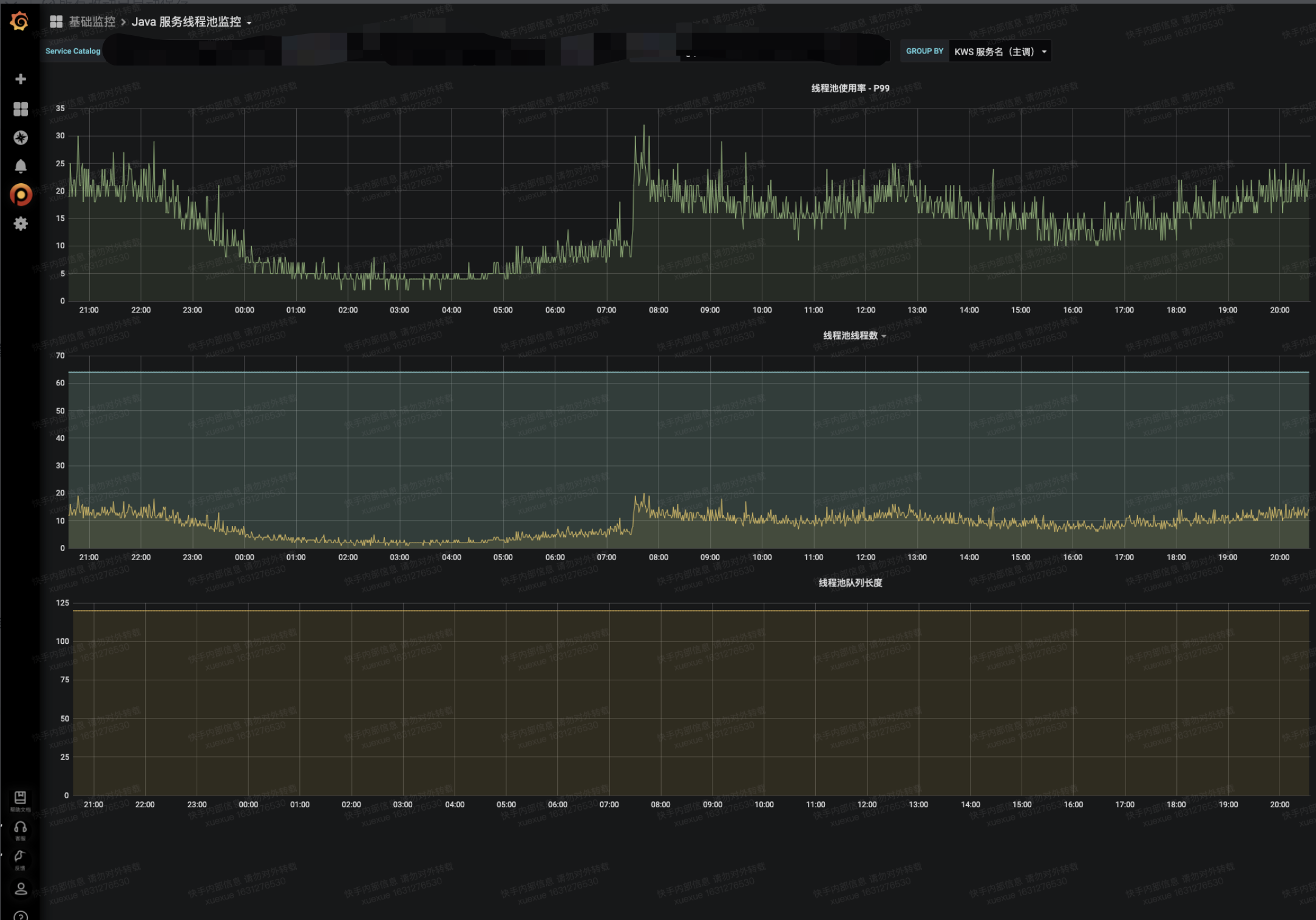
改造后接口平均延迟明显下降(在四点半修改后分机房升级后的表现明显优于之前)

二:流量治理
场景
调整完线程池后,解决了由于数据库建连导致的突刺,剩余的突刺大多是由于第三方服务可用性下降导致的,这是难以避免的,机房间通信,第三方服务性能本身都可能造成问题。为保障被调用服务的延迟不影响到自己的服务,必要的限流阻断措施是有必要的。
KESS流量治理
- 解决
- https://kess-test.corp.kuaishou.com/#/strategy/detail
- tips:
- 请结合实际场景进行配置
- 找组内人review
- 隔板配置可以先进行测试打点,再进行实际运行
- 其他的文档里写的很详细,我也是初次趟趟,感觉还挺方便
三:容器管理
CPU Throttled
搞到这里,其实我们还没有解决缩容后带来的问题,为什么超时会增加,为什么早上的流量扛不住了,为什么单个请求,同一个线程中有莫名的停顿,在高峰期达到了5s甚至更高,而这时,我们的CPU逻辑核平均使用率看起来很正常?同时,用top命令能观察到有si和sy的值很高的逻辑核
之后就关注到了CPU Throttled这个指标,发现cpu节流时有发生,因节流而导致的中断时间也很“可观”。如下图的监控:
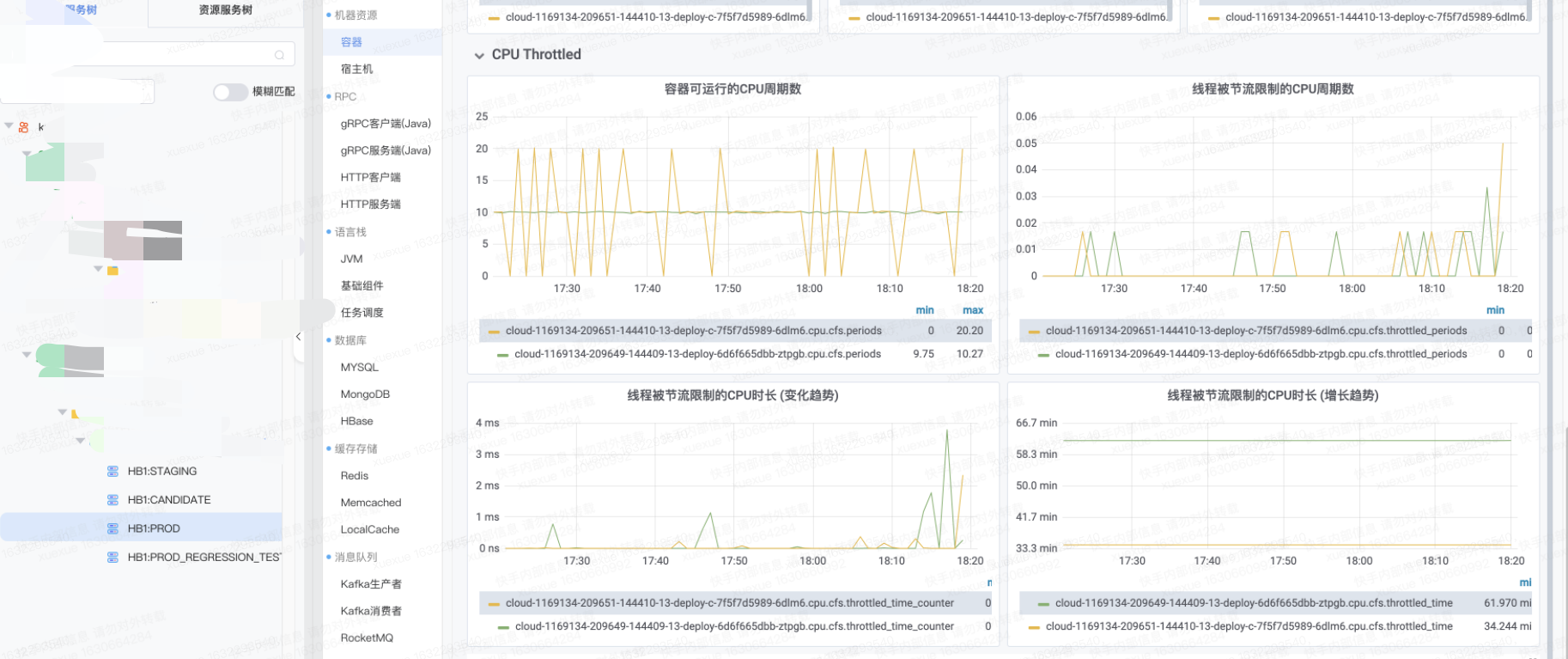
之后便把视线聚焦到了CPU Throttled这个监控上。CPU Throttled,是k8s借助cgroup和CFS对CPU资源的限制和管控机制。CFS调度器(Completely Fair Scheduler)是Linux的内核调度器,可以理解为调度器维护着一个任务池,确定某一时刻CPU到底应该执行哪个任务。为了尽可能维持Fair,它的模型在轮询调度的基础上增加了针对单个进程的vriture_runtime的计算,利用进程权重配置和实际运行时间计算出来的vruntime最终决定了哪个进程被分配更多的CPU。如果vruntime值越小,说明这个进程该被优先执行(被分配更多的处理器时间片)。
k8s利用cgroup进行资源管理和隔离,我们在为容器分配资源时,比如
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
单位后缀m表示“千分之一个核心”,所以这个资源对象的容器进程需要250/1000的核心(25%),并且最多使用500/1000的核心(50%)。类似的,2000m表示两颗完整核心,可以用2,2.0来表示
最终会被翻译成cgroups和CFS的参数配置
$ cat cpu.shares
256
$ cat cpu.cfs_quota_us //cpu.cfs_quota_us:表示该control group限制占用的时间(微秒),默认为-1,表示不限制。如果设为50000,表示占用50000/100000=50%的CPU。
50000
$ cat cpu.cfs_period_us //cpu.cfs_period_us:cpu分配的周期(微秒),默认为1秒即1000000
100000
还有一个默认参数
$ cat /proc/sys/kernel/sched_latency_ns
24000000
所以在这个节点上,正常压力下,系统的CFS调度周期为24ms,CFS重分配周期为100ms,而该POD在一个重分配周期最多占用50ms的时间,在有压力的情况下,POD可以占据的CPU Share比例是256
有关CFS等姿势可以参照官方指导(链接)
找个例子说明一下不同资源需求的POD容器是如何在CFS调度下占用CPU资源的:

在这个例子中,有如下系统配置情况:
- CFS 调度周期为 10ms,正常负载情况下,进程 ready 队列里面的进程在每 10ms 的间隔内都会保证被执行一次
- CFS 重分配周期为 100ms,用于保证一个进程的 limits 设置会被反映在每 100ms 的重分配周期内可以占用的 CPU 时间数,在多核系统中,limit 最大值可以是 CFS 重分配周期 * CPU 核数
- 该执行进程队列只有进程 A 和进程 B 两个进程
- 进程 A 和 B 定义的 CPU share 占用都一样,所以在系统资源紧张的时候可以保证 A 和 B 进程都可以占用可用 CPU 资源的一半
- 定义的 CFS 重分配周期都是 100ms
- 进程 A 在 100ms 内最多占用 50ms,进程 B 在 100ms 内最多占用 20ms
所以在一个 CFS 重分配周期 (相当于 10 个 CFS 调度周期) 内,进程队列的执行情况如下:
- 在前面的 4 个 CFS 调度周期内,进程 A 和 B 由于 share 值是一样的,所以每个 CFS 调度内 (10ms),进程 A 和 B 都会占用 5ms
- 在第 4 个 CFS 调度周期结束的时候,在本 CFS 重分配周期内,进程 B 已经占用了 20ms,在剩下的 8 个 CFS 调度周期即 80ms 内,进程 B 都会被限流,一直到下一个 CFS 重分配周期内,进程 B 才可以继续占用 CPU
- 在第 5-7 这 3 个 CFS 调度周期内,由于进程 B 被限流,所以进程 A 可以完全拥有这 3 个 CFS 调度的 CPU 资源,占用 30ms 的执行时间,这样在本 CFS 重分配周期内,进程 A 已经占用了 50ms 的 CPU 时间,在后面剩下的 3 个 CFS 调度周期即后面的 30ms 内,进程 A 也会被限流,一直到下一个 CFS 重分配周期内,进程 A 才可以继续占用 CPU
另一个简单的例子来说:
假使cpu.cfs_period_us设定为100毫秒(这是全局统一的设置),cpu.cfs_quota_us设定为20毫秒(这是每个应用在K8s自己设定的,当前的配置等同于给Pod分配200millicore)。这意味着CFS会每隔100毫秒会重新分配应用的CPU使用权,而在每个100毫秒内,应用可以占用CPU20毫秒。在物理机上单独部署,由于我们没有使用cgroups,程序可以用尽空闲的CPU。但是假如一个请求在物理机上需要花100毫秒,在刚刚设定的K8s环境下则会发生如下现象:
运行20毫秒 -> 挂起并等待80毫秒(节流) -> 运行20毫秒 -> 挂起并等待80毫秒-> 运行20毫秒 -> 挂起并等待80毫秒-> 运行20毫秒 -> 挂起并等待80毫秒-> 运行20毫秒 -> 请求完成并返回
原本只需100毫秒的请求,现在却花费了420毫秒。
这就是为什么在物理机上部署的程序,放到容器里反而响应变慢的原因。
如果想解决这个问题,我们需要调整节流的限制,由于我们没有权限直接修改,那么增加核心数就可以提高limit的限制。
最后我们从4Core恢复了8Core核心数,修改后效果明显,解决了高峰期需求处理不过来的情况。
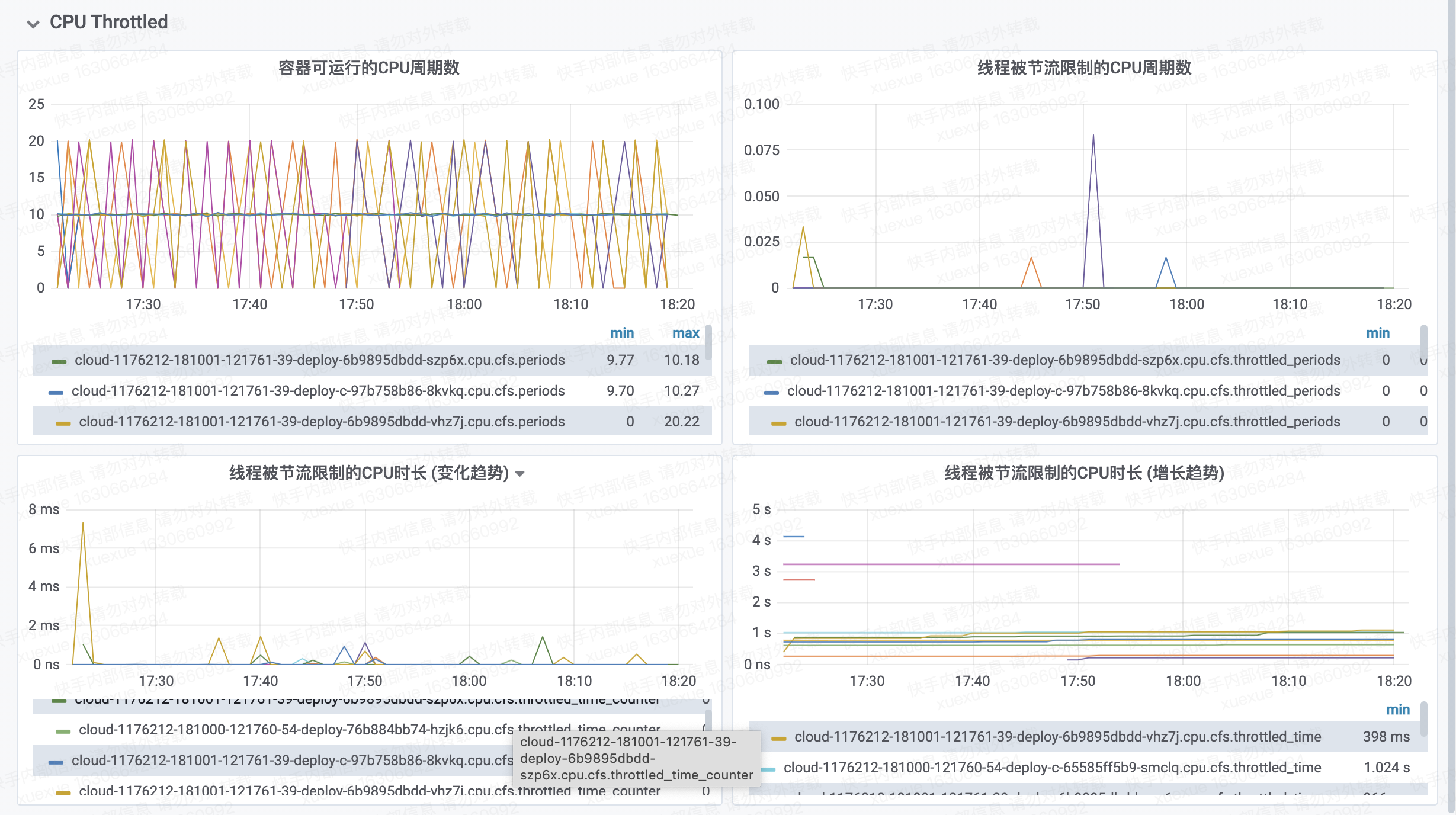
接口性能比对,改造前:
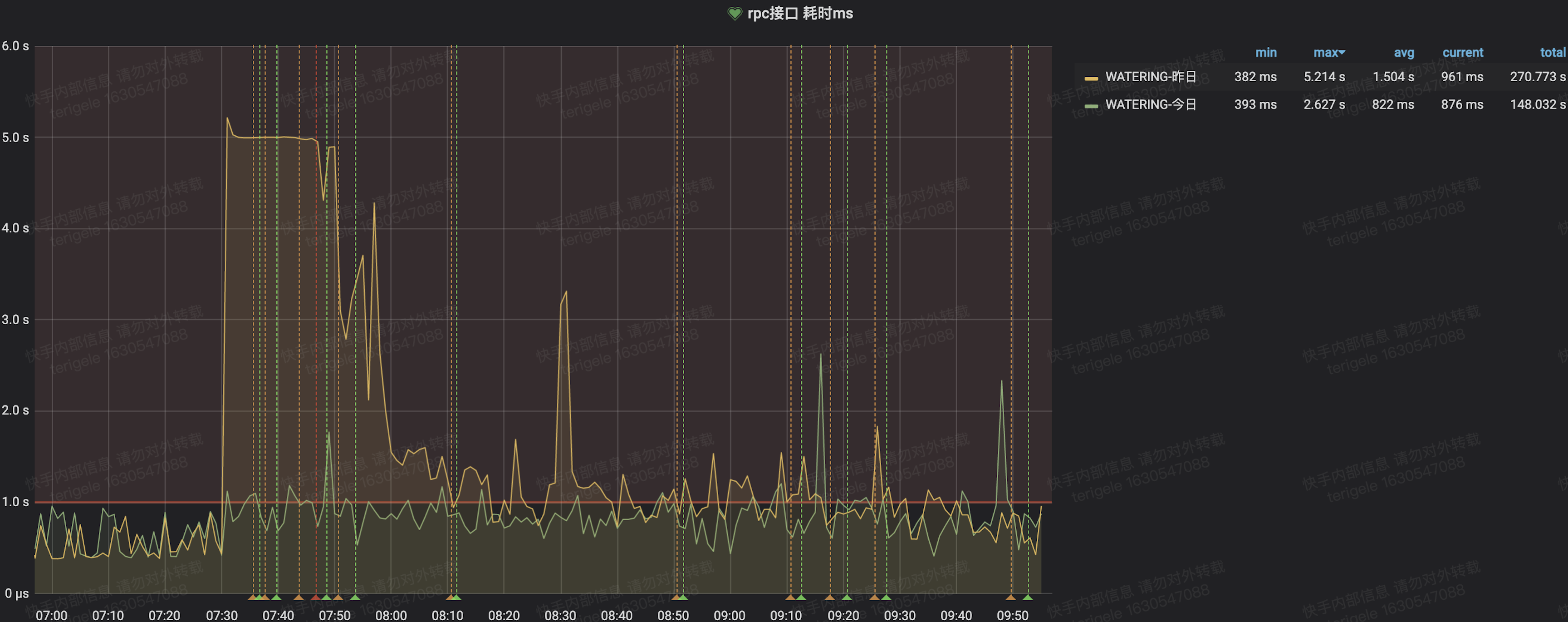
改造后:

服务端P995监控:
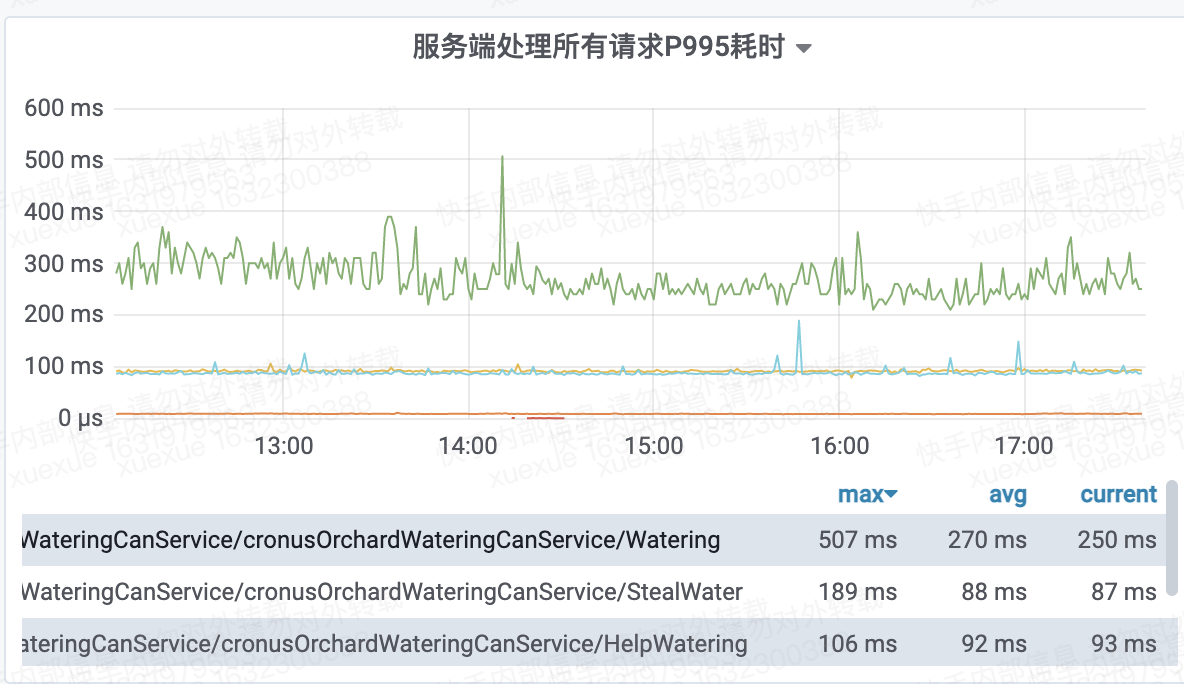
四:监控配置
场景
小伙伴排查时发现我们的报警配置是每次有p995超过1000ms就报警,这会把一些网络抖动也计算进去,太多的偶发性警报,容易让大家忽略掉真正需要处理的报警信息。
Grafana报警配置
- tips:配置要容忍可能的网络抖动,可以配置为三分钟采集平均时常的时间大于1s时报警,慎选max()函数
- 配置完后是这样

解决结果
- 浇水接口每日早上流量激增时,不再爆grpc线程池
- 接口耗时监控 (P995&P99)无异常突刺,曲线平稳
- 异常突刺不包括:
- 公司基础架构、KCC、容器、网络等公共组件报警
- 数据库连接异常中断
- 具有突发性、偶见性、可追溯的非裂变平台业务导致的性能问题
- 曲线平稳特征:十分钟内(P995&P99)无超过200ms的异常连续起伏
从31台机器缩到现在的8台,性能无明显大的损失