先感谢403F的帮助
要爬的是https://soutubot.moe/
然后就遇到了问题
贯穿始终的是401未授权访问,但是请求包里不包含token一类的,cookie也放了,将整个导入到postman里面
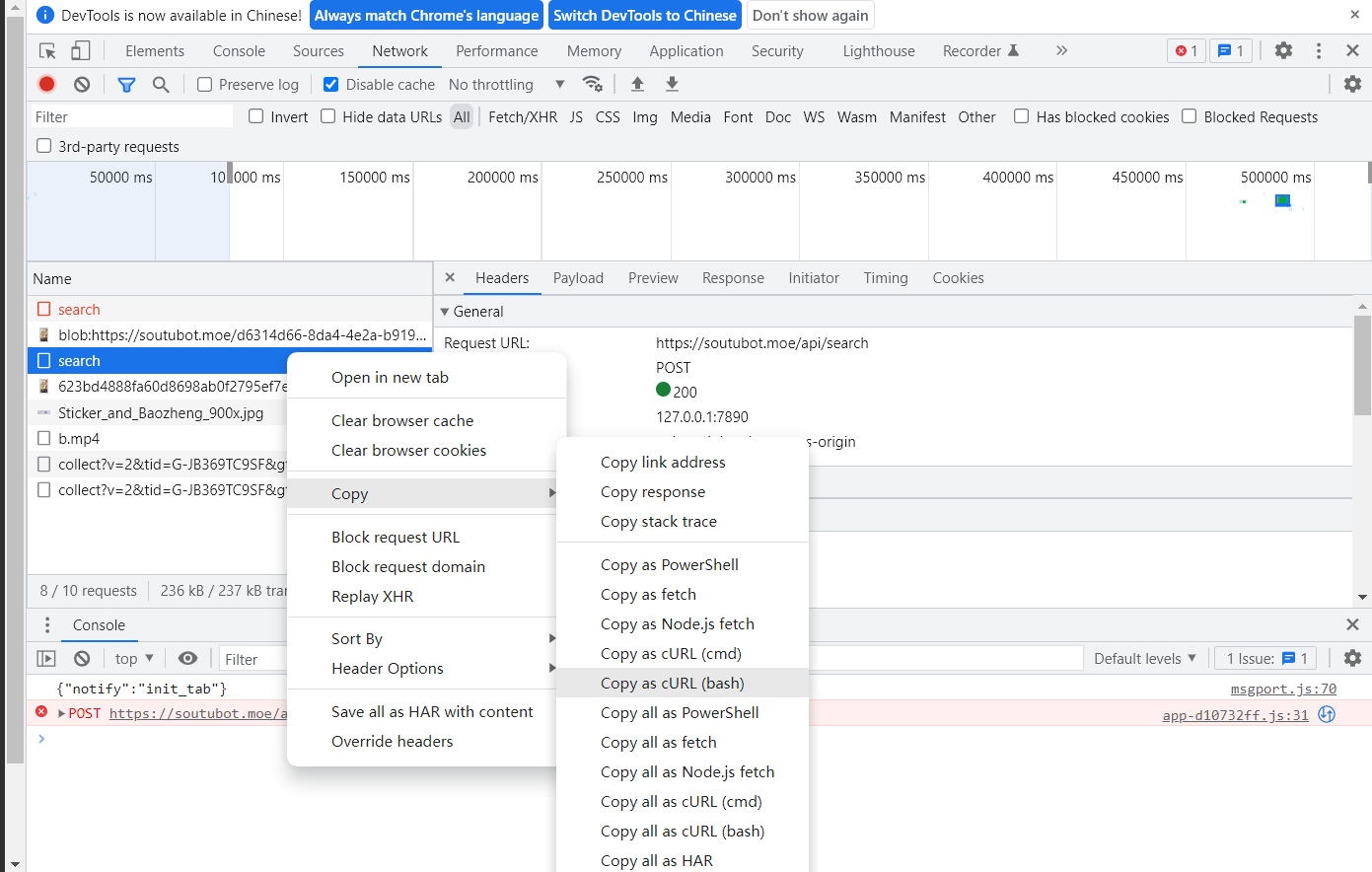
发现能够请求成功,然后只有请求头可能出问题,那就是请求头的问题
请求头一个一个去掉发现比较重要的一项是x-api-key,网站用了一个生成的x-api-key,保证安全性,x-api-key看起来是随机生成的base64,然后过期时间特别短,看看
然后
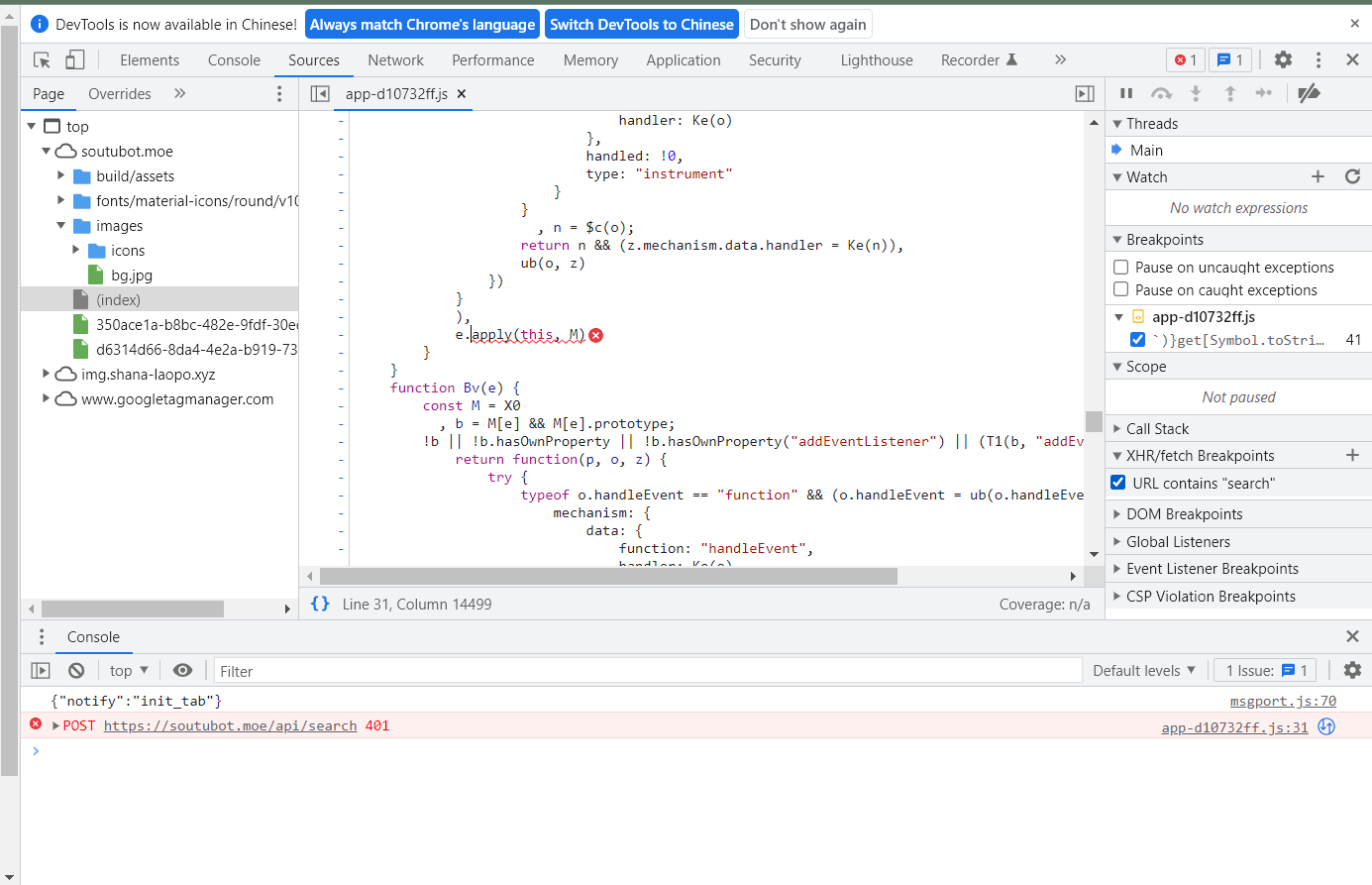
在URL contains 里面过滤包含search请求的
断点卡到search这一步
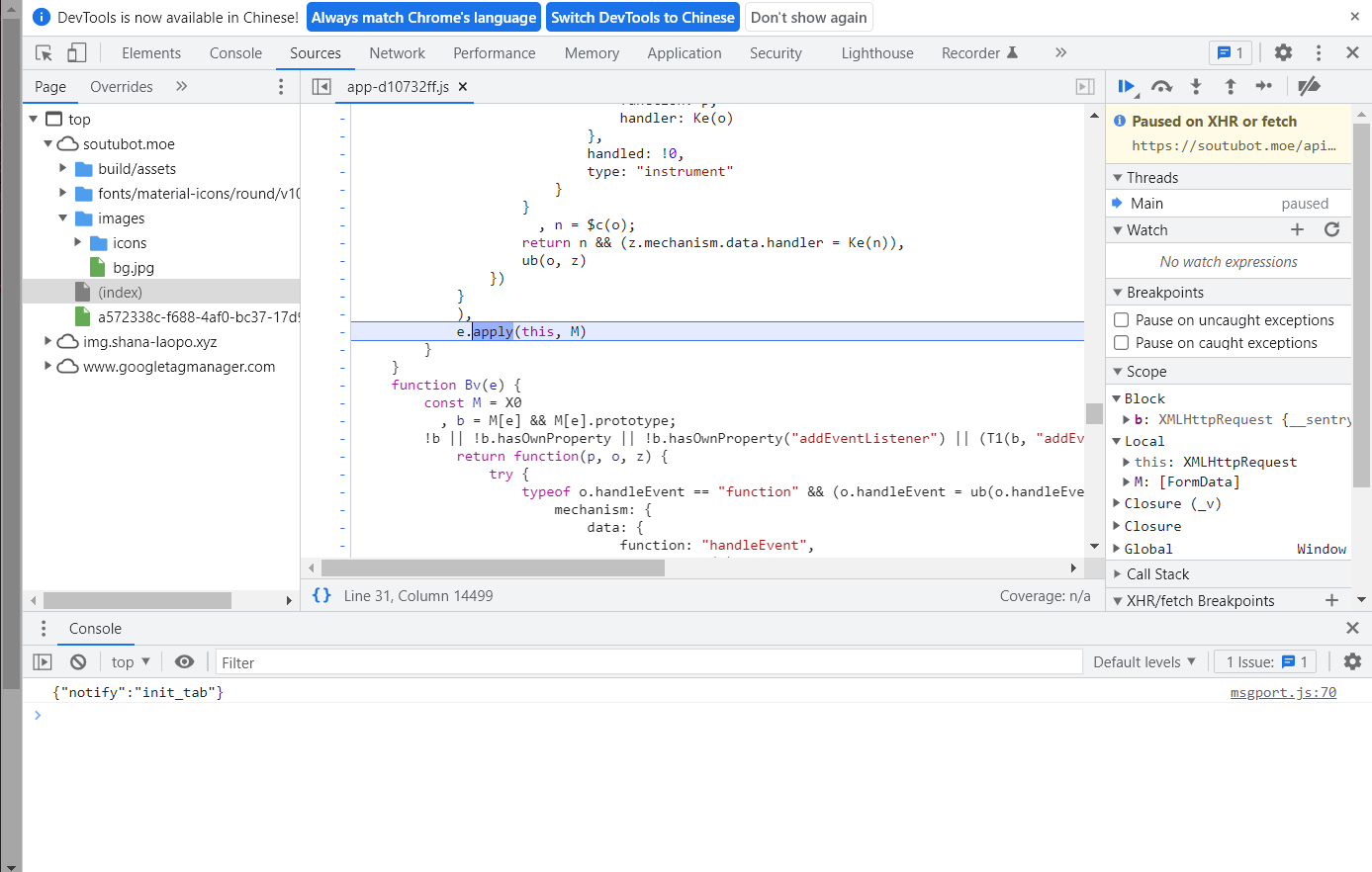
跳步运行几步
这个函数运行结束
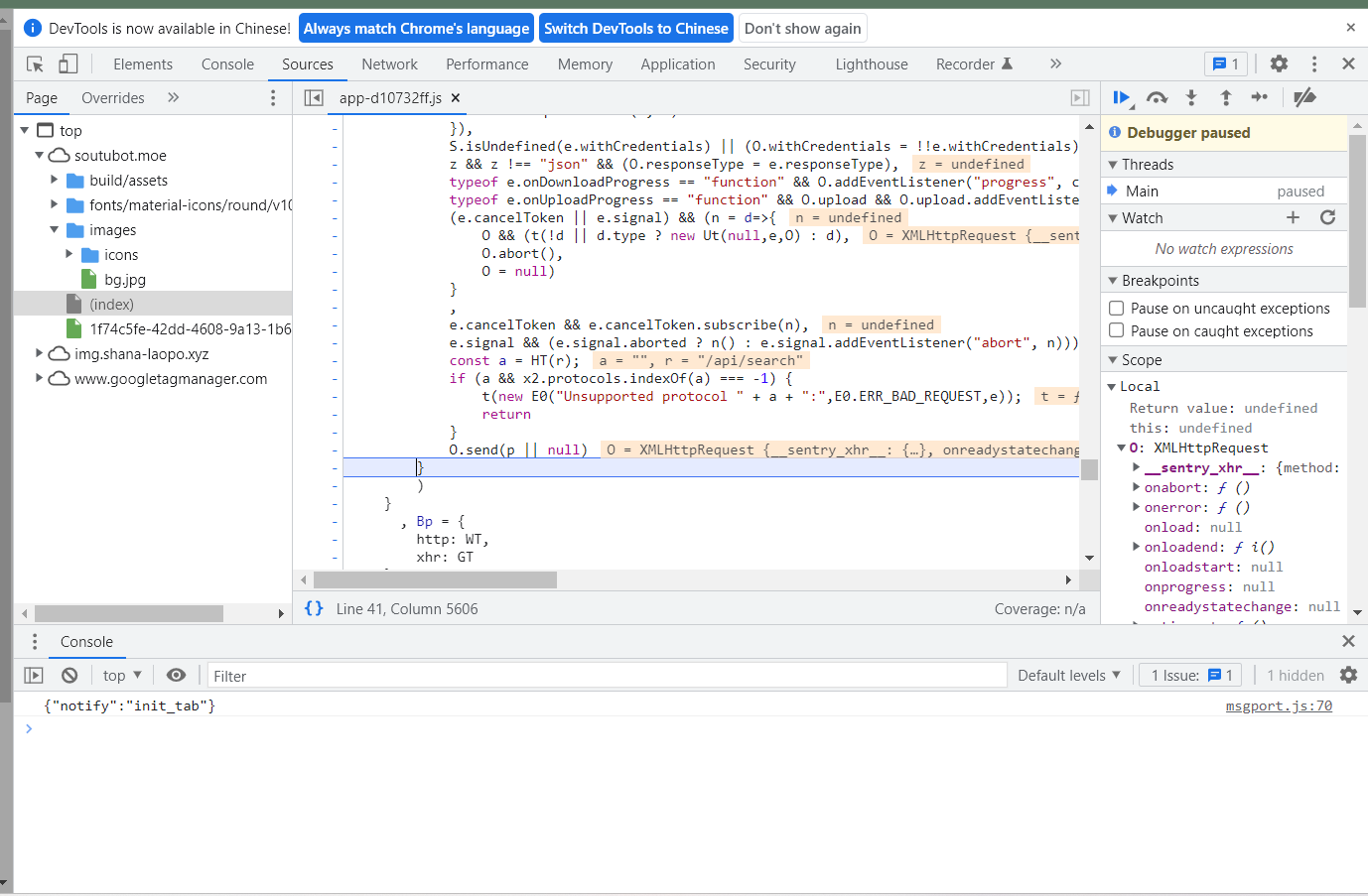
在这个函数最上方设置断点
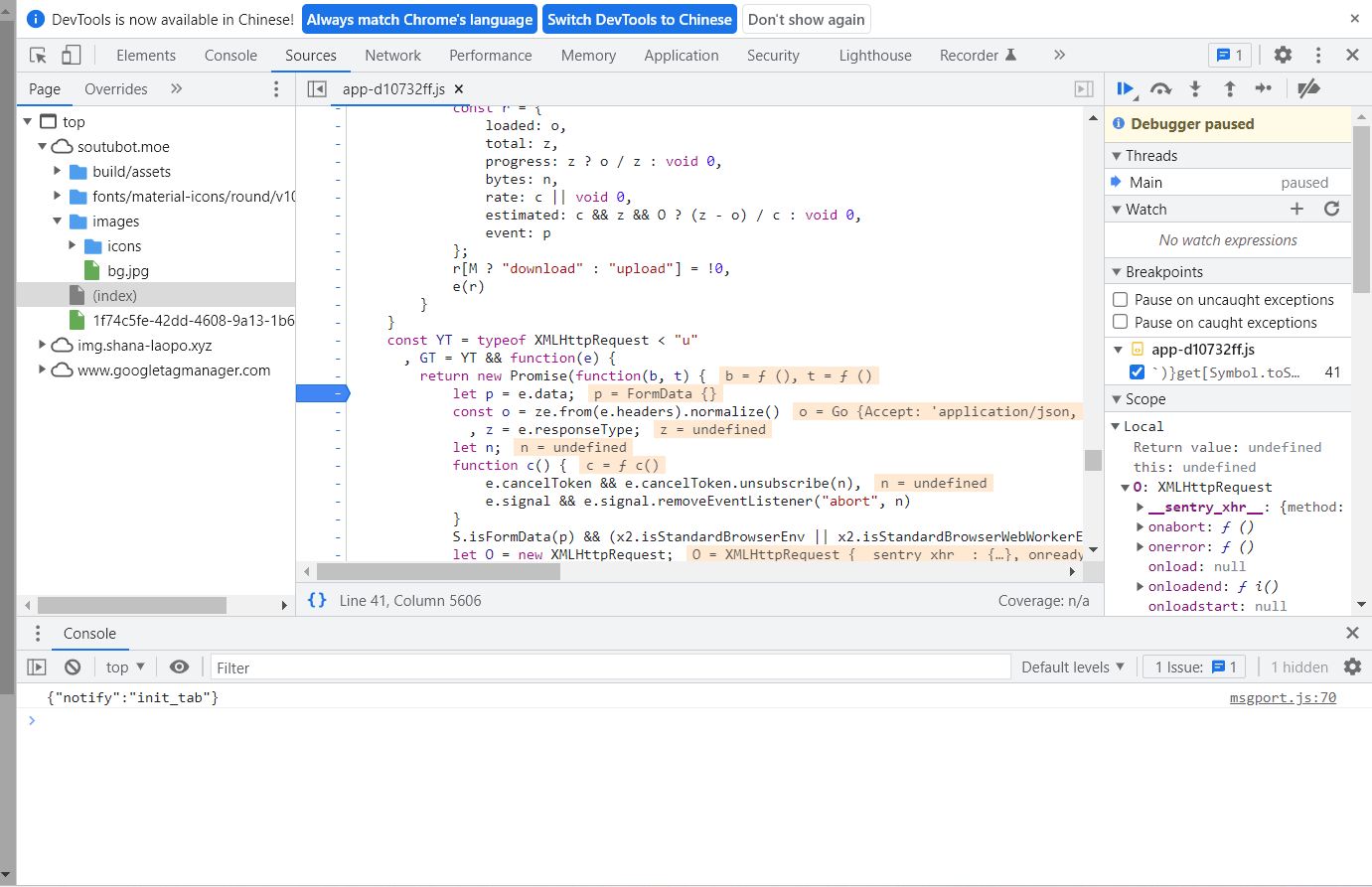
发现已经被赋值
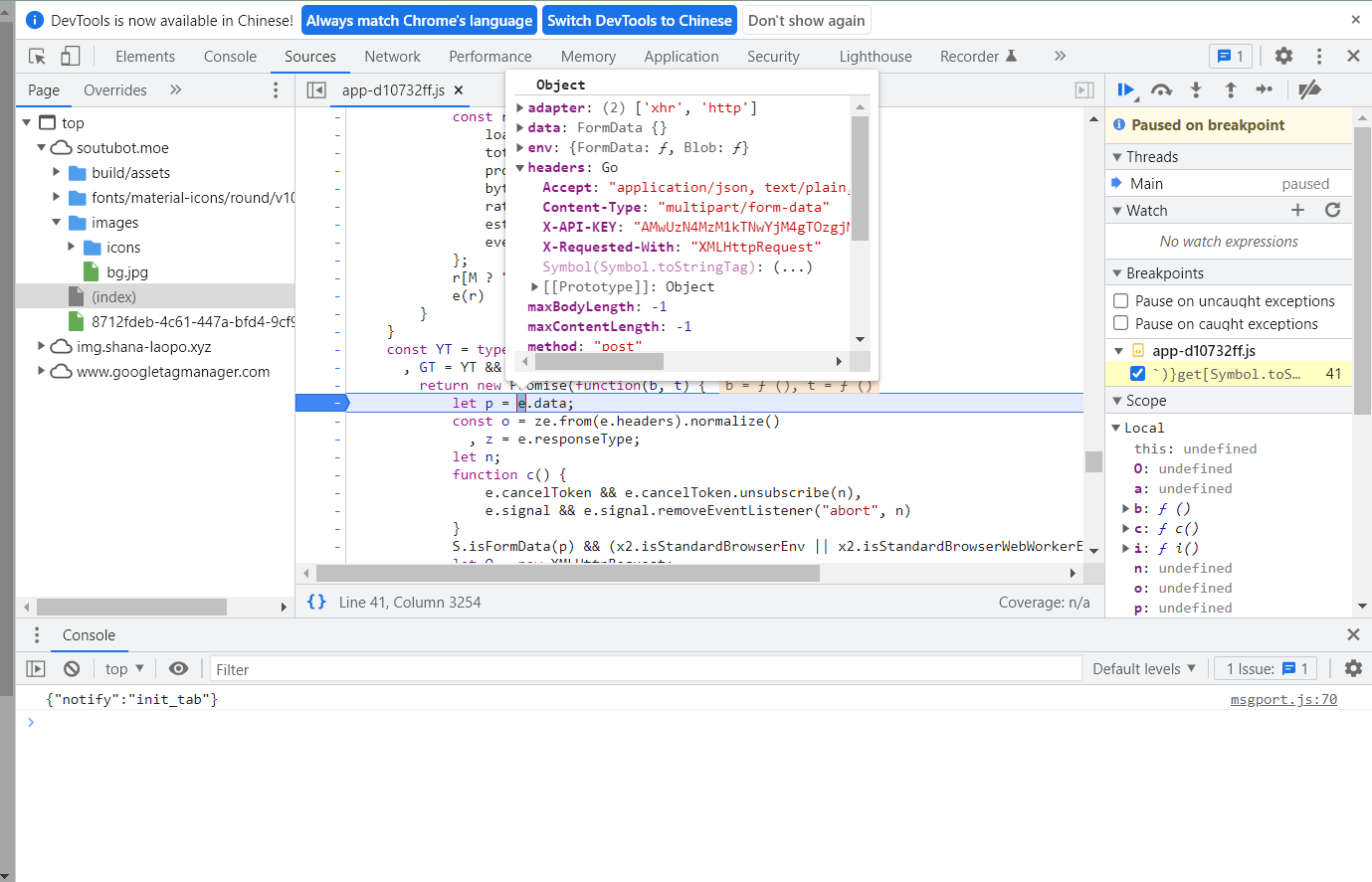
找到调用源,紧上面有调用

然而不是,干脆随便找个看着顺眼的找到哪里调用e得了,然后看里面变量
找看起来可能有意义的函数
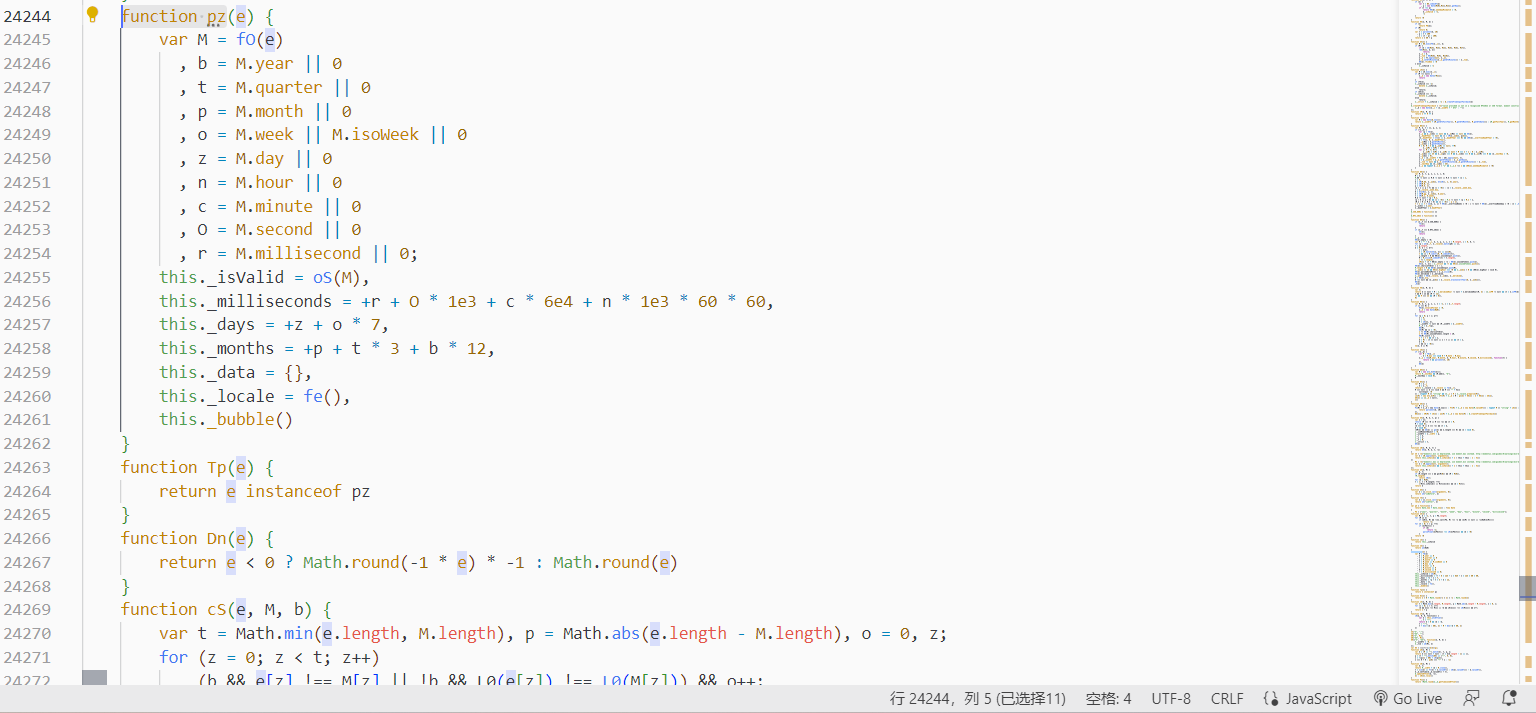
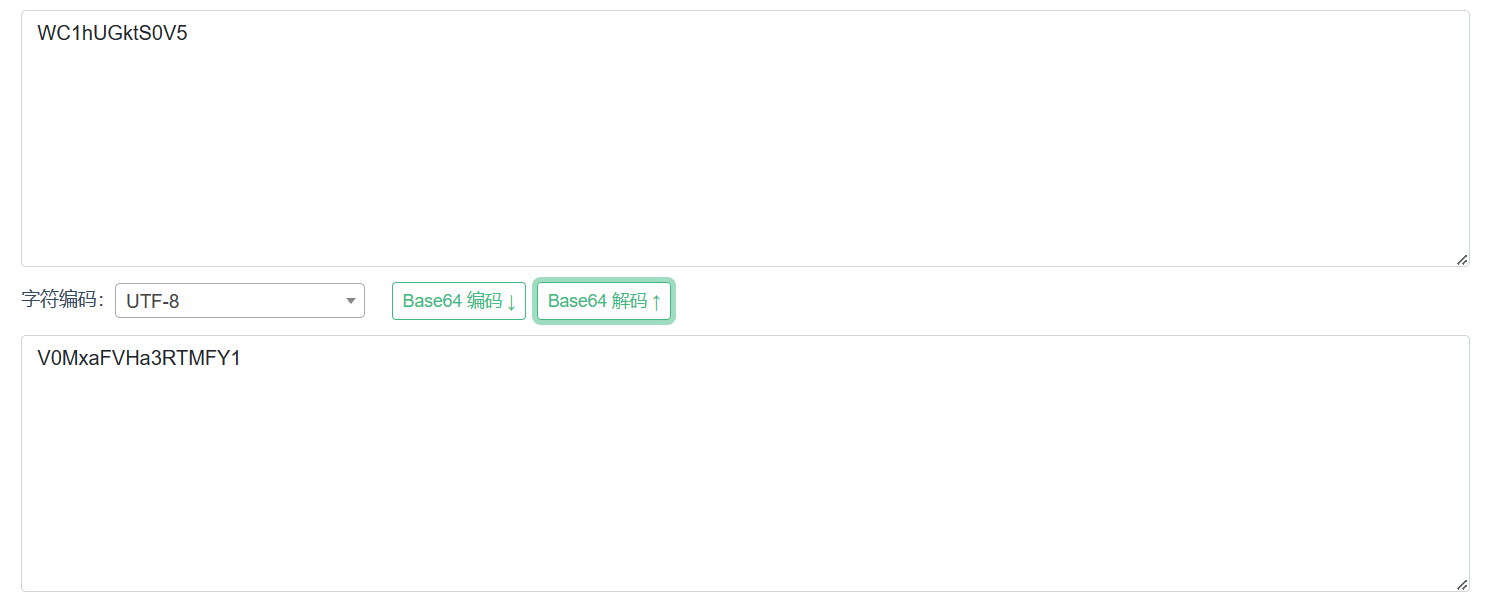
单步运行到有个看起来很不错的字符串
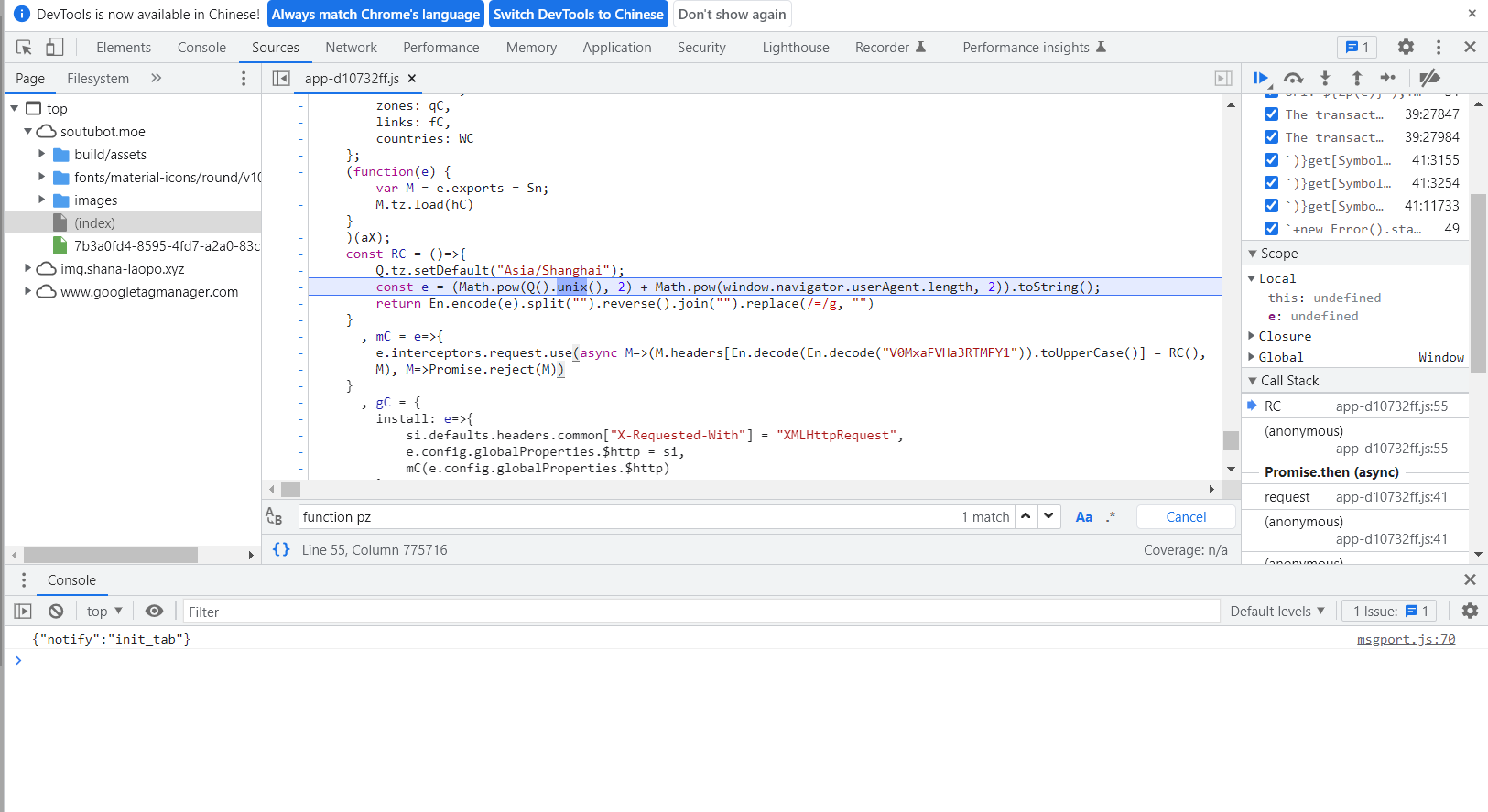
V0MxaFVHa3RTMFY1
很酷
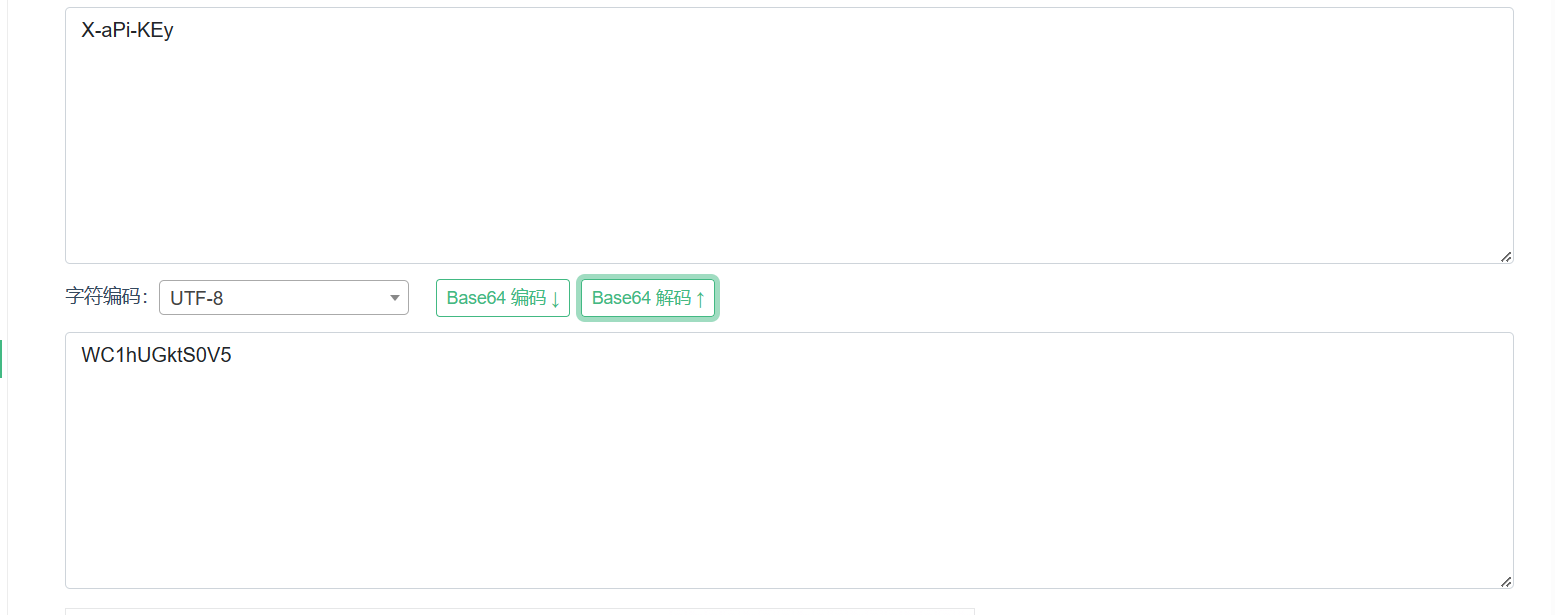
然后就是X-api-KEy了
看看怎么实现
const RC = ()=>{
Q.tz.setDefault("Asia/Shanghai");
const e = (Math.pow(Q().unix(), 2) + Math.pow(window.navigator.userAgent.length, 2)).toString();
return En.encode(e).split("").reverse().join("").replace(/=/g, "")
}
当前时间平方,+userAgent长度平方求base64,base64取反去掉等号
这一步计算出来的x-api-key
因此爬虫只需要现算然后求值就可以了,
封装了一个api在github上