LEARNING
LizRice--Learning EBPF
> 主要参考Liz Rice主讲的youtube视频:https://www.youtube.com/watch?v=TJgxjVTZtfw > 这里做lab记录,持续更新ing > 线上实验环境:https://play.instruqt.com/isovalent/invite/miht6dgd ......
FastReport 在C#中的应用-Learning_1
#### 1.报表模板设计 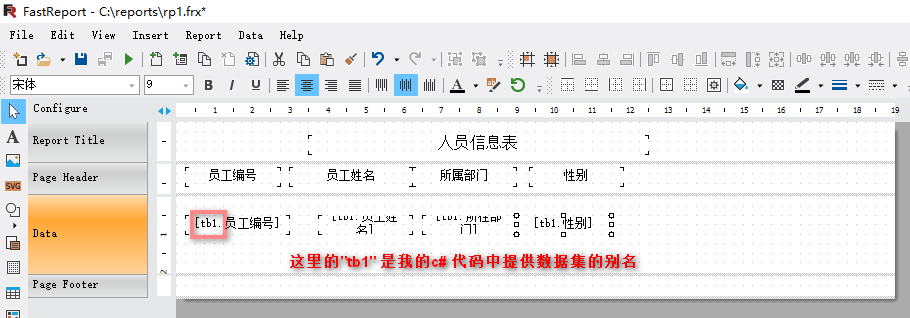 #### 2.c# 代码 ``` csharp using FastRepor ......
2023-7-learning-note
- [任务1.学习Apex,Trigger,以及对象字段的简单使用](#任务1学习apextrigger以及对象字段的简单使用) - [Trigger](#trigger) - [任务2.学习Visualforce 页面的开发,能够做出与后台交互的Visualforce页面](#任务2学习visua ......
Exploiting Noise as a Resource for Computation and Learning in Spiking Neural Networks
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! https://arxiv.org/abs/2305.16044 Summary Keywords Introduction Results Noisy spiking neural network and noise-driven le ......
The Deep Learning Compiler: A Comprehensive Survey
The Deep Learning Compiler: A Comprehensive Survey - [AI编译器综述](#ai编译器综述) - [摘要](#摘要) - [介绍](#介绍) - [背景](#背景) - [深度学习框架](#深度学习框架) - [深度学习硬件](#深度学习硬件) - ......
[ICDE 2022]How Learning Can Help Complex Cyclic Join Decomposition
# [ICDE 2022]How Learning Can Help Complex Cyclic Join Decomposition ## 总结 主要贡献是把子图匹配策略的cost的判断改为了GNN实现的预测(写得挺模棱两可的) ## 动机 解决子图匹配的一个重要问题是解决复杂循环连接查询。文章 ......
Regret Minimization Experience Replay in Off-Policy Reinforcement Learning
**发表时间:**2021 (NeurIPS 2021) **文章要点:**理论表明,更高的hindsight TD error,更加on policy,以及更准的target Q value的样本应该有更高的采样权重(The theory suggests that data with highe ......
2023-7-learning-note
- [任务1](#任务1) - [任务2](#任务2) - [apex:pageBlockButtons 样式调整,修改前:](#apexpageblockbuttons-样式调整修改前) - [修改后](#修改后) - [代码](#代码) - [官网解释:](#官网解释) - [任务3](#任务3 ......
non-deep Machine Learning Notes
# Table of Content ## Supervised Learning ### 1. Linear Model Linear Regression Logistic Regression ### 2. Support Vector Machine, SVM ### 3. Generati ......
4.5 Unsupervised Learning: Word Embedding
# 1. Introduction(引入) 词嵌入(word embedding)是降维算法(Dimension Reduction)的典型应用. 最经典的做法就是1-of-N Encoding,它指的就是每一个字都是以向量来表示,只有在自己所属的那个字词索引上为1,其余为0,因此如果世界上的英文字 ......
Multi-Modal Attention Network Learning for Semantic Source Code Retrieval 解读
# Multi-Modal Attention Network Learning for Semantic Source Code Retrieva Multi-Modal Attention Network Learning for Semantic Source Code Retrieval,题 ......
Effective Diversity in Population-Based Reinforcement Learning
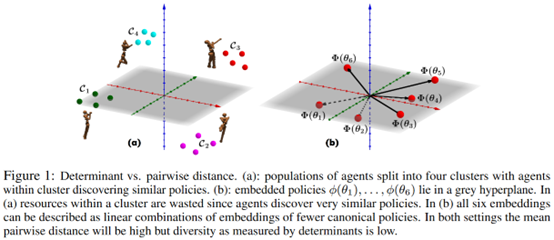 **发表时间:**2020 (NeurIPS 2020) **文章要点:**这篇文章提出了Diversity v ......
FOSTER:Feature Boosting and Compression for Class-Incremental Learning论文阅读笔记
## 摘要 先前的类增量学习方法要么难以在稳定性-可塑性之间取得较好的平衡,要么会带来较大的计算/存储开销。受gradient boosting的启发,作者提出了一种新型的两阶段学习范式FOSTER,以逐步适应目标模型和先前的集合模型之间的残差,使得该模型能够自适应地学习新的类别。具体来说,作者首先 ......
Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning---reading
# Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning reading - 攻击目标 - 安全破坏 - 完整性破坏: 逃避检测,而不影响正常的系统运行 - 可用性破坏: 使得合法用户不能正常使用系统 - 隐私 ......
Spectrum Random Masking for Generalization in Image-based Reinforcement Learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! ......
COMP9444 Neural Networks and Deep Learning
COMP9444 Neural Networks and Deep LearningTerm 2, 2023Project 1 - Characters and Hidden UnitDynamicsDue: Wednesday 5 July, 23:59 pmMarks: 20% of final ......
Faster sorting algorithms discovered using deep reinforcement learning
## 摘要: - `AlphaDev`模型优化排序算法,将排序算法提速70%。通过强化学习,AlphaDev发现了更加有效的算法,直接超越了科学家和工程师们几十年来的精心打磨。现在,新的算法已经成为两个标准C++编码库的一部分,每天都会被全球的程序员使用数万亿次。 ## 介绍 - 优化目标为排序算法 ......
LEARNING TO SAMPLE WITH LOCAL AND GLOBAL CONTEXTS FROM EXPERIENCE REPLAY BUFFERS
 **发表时间:**2021(ICLR 2021) **文章要点:**这篇文章想说,之前的experience r ......
How about learning medical treatment model
> Learning medical treatment models can be a great way to gain a deeper understanding of how diseases are diagnosed and treated. There are many differ ......
Reinforcement learning
如图1所示,强化学习中,state是环境的状态,就是observation。 图1 强化学习 一、Policy based approach learning an actor The policy based approach is to learn an actor (agent or poli ......
Self-attention with Functional Time Representation Learning
[TOC] > [Xu D., Ruan C., Kumar S., Korpeoglu E. and Achan K. Self-attention with functional time representation learning. NIPS, 2019.](http://arxiv.or ......
论文阅读 | Soteria: Provable Defense against Privacy Leakage in Federated Learning from Representation Perspective
Soteria:基于表示的联邦学习中可证明的隐私泄露防御https://ieeexplore.ieee.org/document/9578192 # 3 FL隐私泄露的根本原因 ## 3.1 FL中的表示层信息泄露 **问题设置** 在FL中,有多个设备和一个中央服务器。服务器协调FL进程,其中每个 ......
EulerNet Adaptive Feature Interaction Learning via Euler’s Formula for CTR Prediction
[TOC] > [Tian Z., Bai T., Zhao W., Wen J. and Cao Z. Eulernet: Adaptive feature interaction learning via euler’s formula for ctr prediction. SIGIR, 20 ......
《深度学习(deep learning)》pdf电子书免费下载
《深度学习》由全球知名的三位专家Ian Goodfellow、Yoshua Bengio 和Aaron Courville撰写,是深度学习领域奠基性的经典教材。全书的内容包括3个部分:第 1部分介绍基本的数学工具和机器学习的概念,它们是深度学习的预备知识;第 2部分系统深入地讲解现今已成熟的深度学习 ......
COMP9417 - Machine Learning
COMP9417 - Machine LearningHomework 1: Regularized Regression & NumericalOptimizationIntroduction In this homework we will explore some algorithms for ......
选修-4-Optimization for Deep Learning
# 1. Some Nitations 在本小节开始之前,需要知道的符号含义. 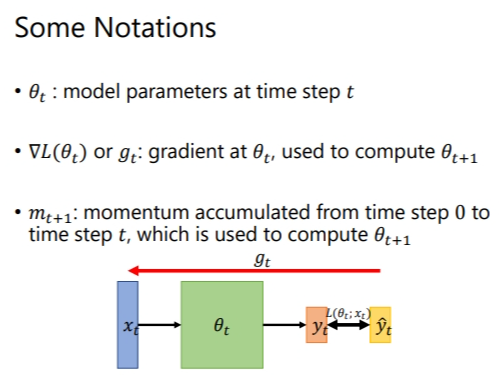 # 2. What is ......
【笔记】learning git branching
git图是由子节点指向父节点(可能有多个父节点) ### git commit  ### git branch ![ ......
了解基于模型的元学习:Learning to Learn优化策略和Meta-Learner LSTM
摘要:本文主要为大家讲解基于模型的元学习中的Learning to Learn优化策略和Meta-Learner LSTM。 本文分享自华为云社区《深度学习应用篇-元学习[16]:基于模型的元学习-Learning to Learn优化策略、Meta-Learner LSTM》,作者:汀丶 。 1. ......
深度学习应用篇-元学习[16]:基于模型的元学习-Learning to Learn优化策略、Meta-Learner LSTM
# 深度学习应用篇-元学习[16]:基于模型的元学习-Learning to Learn优化策略、Meta-Learner LSTM # 1.Learning to Learn Learning to Learn by Gradient Descent by Gradient Descent 提出了 ......
[Fullstack] Learning note for Fullstack developer - FrontendMaster
Command Line 1. Navigate to your home directory cd ~ 2. Make a directory call "temp" mkdir temp 3. Move into temp cd temp 4. List the idrectory conten ......