准确率(Precision),也叫正确预测率(positive predictive value),在模式识别、信息检索、机器学习等研究应用领域,准确率用来衡量模型预测的结果中相关或者正确的比例。而召回率(recall),也叫敏感度(sensitivity),即模型预测的结果中相关或正确的数量占样本中实际相关或正确的数量的比例。一般在计算机视觉领域物体分类检测任务中,检测出的物体轮廓框如果类别和ground truth的类别相同,并且两者之间IoU大于一个阈值(一般为0.5),那么该预测值是正确的。如果模型预测出数据集中有N个horse这一类的物体,并给出其轮廓框,而实际场景中有T个horse标签的ground truth。在2000个预测值中,有些是错误的,即和ground truth的IoU小于阈值,又或者IoU大于阈值,但是该ground truth已经有和其相关的预测值了,此时该预测值均为假正例(false positive,FP),有些和ground truth的IoU大于阈值,并且为唯一和ground truth相关的预测值,那么该预测值为真正例(true positive, TP)。那么此时准确率的计算为precision=TP/(TP+FP)。而召回率的计算则为recall=TP/T.
准确率和召回率是一对矛盾的度量尺度,一般来说,准确率高时,召回率往往很低,而召回率高时,准确率往往偏低。例如在物体分类检测任务中,一组预测轮廓框有两个指标,一个是分类的score,一组是轮廓框的坐标位置。若希望将找出更多的该类的预测轮廓框,则需要将分类score的阈值降低,输出更多的结果,此时必然会有些预测值为假,造成准确率下降,但是召回率会得以提高。但是如果想准确率高,则需要提高分类score,将分类得分很低的预测值丢弃,那么可能会漏掉很多和ground truth的IoU大于阈值的预测结果,造成召回率降低。
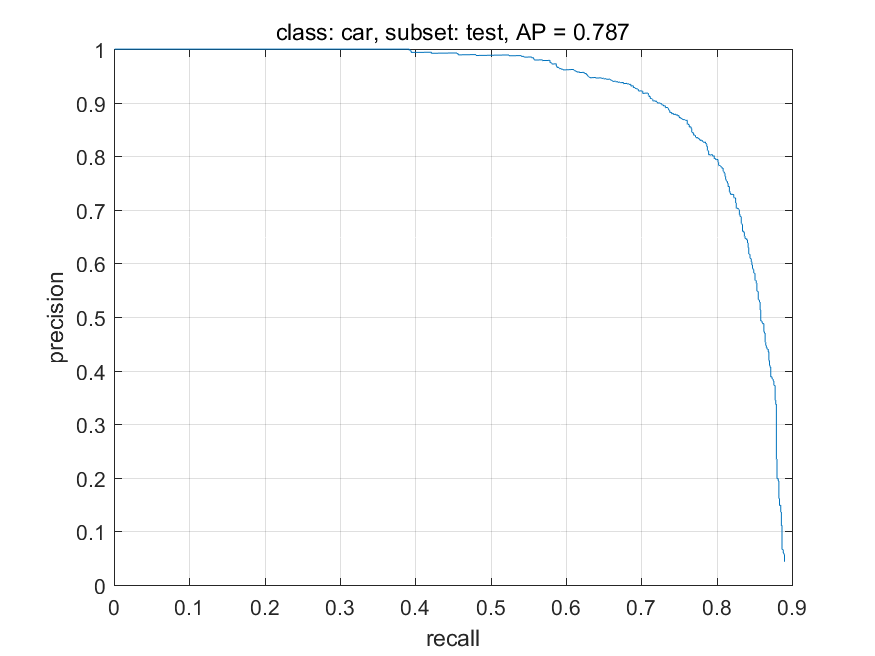
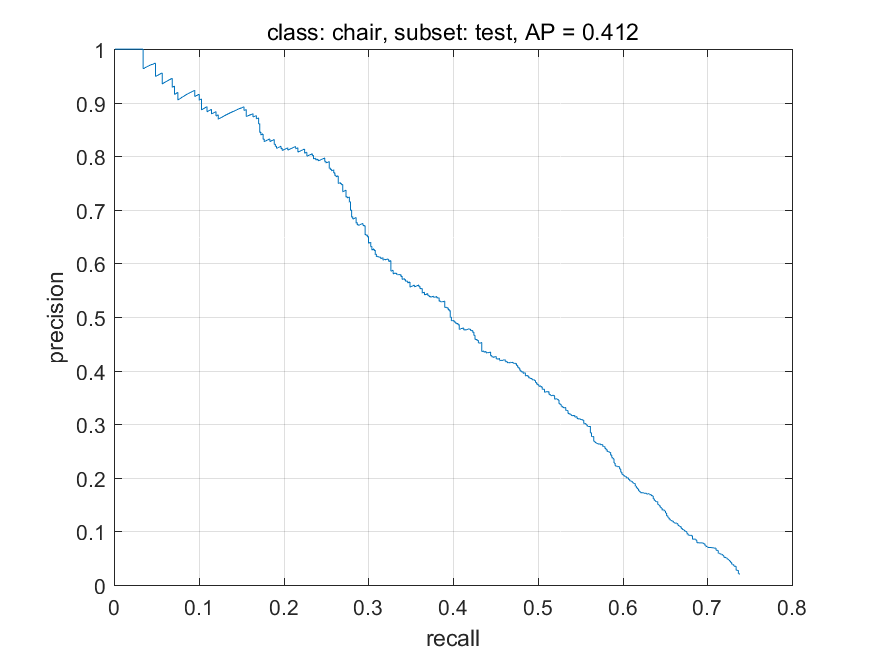
在很多情况中,需要对模型的预测结果进行排序,在物体分类检测中,一般是按照分类score进行排序,排在前面的预测结果一般被认为“最可能”为真正例的预测结果,排在后面的则是模型认为“可能性低”的真正例。按照此顺序逐个把预测结果进行分析,每个预测值均可以得到一个准确率和召回率,以召回率为横轴,准确率为纵轴作图,就得到了准确率-召回率曲线,一般称为precision-recall曲线。Precision-recall曲线图直观地显示了模型在数据集上的准确率、召回率详细分布情况。在进行模型选择时,直观上可以看到,如果模型A的precision-recall曲线将模型B的precision-recall曲线完全包住,则模型A的性能优于B。而若模型A的precision-recall曲线和模型C的precision-recall曲线有交点,则此时无法直观上判定模型的优劣,此时一般用precision-recall曲线下面积的大小来进行比较,这个面积在物体分类检测任务中是另外一项衡量模型优劣的指标ap(average precision)值。而如果数据集有多类,那么每个类计算得到ap后再平均所有类的ap即使mAP. mAP是评估模型在数据集上各个类上的整体表现性能,也是以各个数据集为基础举办各种物体检测竞赛的主要评估指标。
计算AP和mAP的代码,来自PASCAL VOC物体检测竞赛的devkit,是和数据集一起公开的测试评估代码,供参赛者提交代码前进行初步的模型性能评估。可以看到代码先计算了预测值和ground truth的IoU,再而计算tp, fp, precision和recall.而后根据precision和recall计算precision-recall曲线下的面积,即AP,并将每类的precision-recall曲线绘制。下图给出根据precision-recall曲线计算ap的结果。图中给出PASCAL VOC 2007数据检测结果其中两类的precision-recall曲线,从图中可以看出,car这类的曲线弧度比较大,因此ap值比较大。而chair这类的曲线则是直线下降的,因此ap值比较小。