MyBatis-Plus官网:https://baomidou.com/
一、简介
1. 概述
MyBatis-Plus(简称 MP,是由baomidou(苞米豆)组织开源的)是一个基于 MyBatis 的增强工具,它对 Mybatis 的基础功能进行了增强,但未做任何改变。
使得我们可以在 Mybatis 开发的项目上直接进行升级为 Mybatis-plus,正如它对自己的定位,它能够帮助我们进一步简化开发过程,提高开发效率。
Mybatis-Plus 其实可以看作是对 Mybatis 的再一次封装,升级之后,对于单表的 CRUD 操作,调用 Mybatis-Plus 所提供的 API 就能够轻松实现,
此外还提供了各种查询方式、分页等行为。最最重要的,开发人员还不用去编写 XML,这就大大降低了开发难度。
2. 特性
-
-
损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作。
-
强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求。
-
支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错。
-
支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer2005、SQLServer 等多种数据库。
-
支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题。
-
支持 XML 热加载:Mapper 对应的 XML 支持热加载,对于简单的 CRUD 操作,甚至可以无 XML 启动。
-
支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作。
-
支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )。
-
支持关键词自动转义:支持数据库关键词(order、key......)自动转义,还可自定义关键词。
-
内置代码生成器:采用代码或者Maven 插件可快速生成 Mapper 、Model 、Service 、Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用。
-
内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询。
-
内置性能分析插件:可输出 Sql 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询。
-
内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作。
-
内置 Sql 注入剥离器
二、快速使用
1. 引入依赖
<dependencies> <!-- mybatis-plus框架 --> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.5.2</version> </dependency> <!--mysql数据库--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.26</version> </dependency> </dependencies>
2. 配置数据源
在application.yml/properties中配置数据源,此处省略
3. 创建实体类
4. 创建映射接口
需要继承BaseMapper<实体类名>,然后就可以直接使用了。
三、通用CRUD
1. 配置日志
使用SpringBoot默认的logback日志或MyBatis-plus集成的日志
MyBatis-Plus集成的日志:
mybatis-plus:
configuration:
#mybatis-plus日志控制台输出
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
#关闭banner
banner: false
2. 插入操作
/** * 插入一条记录 * * @param entity 实体对象. */ int insert(T entity);
2.1 @TableId
| 名称 | @TableId |
|---|---|
| 类型 | 属性注解 |
| 位置 | 模型类中用于表示主键的属性定义上方 |
| 作用 | 设置当前类中主键属性的生成策略 |
| 相关属性 | value(默认):设置数据库表主键名称,字段名和属性名相同可以省略 type:设置主键属性的生成策略,值查照IdType的枚举值 |


/** * 生成ID类型枚举类 */ @Getter public enum IdType { /** * 数据库ID自增 * <p>该类型请确保数据库设置了 ID自增 否则无效</p> */ AUTO(0), /** * 该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT) * 注解中指定为NONE使用全局的生成策略,默认使用雪花算法 */ NONE(1), /** * 用户输入ID * <p>该类型可以通过自己注册自动填充插件进行填充</p> */ INPUT(2), /* 以下2种类型、只有当插入对象ID 为空,才自动填充。 */ /** * 分配ID (主键类型为number或string) * 雪花算法生成id */ ASSIGN_ID(3), /** * 分配UUID (主键类型为 string) */ ASSIGN_UUID(4); }
-
AUTO:数据库ID自增,这种策略适合在数据库服务器只有1台的情况下使用,不可作为分布式ID使用。
-
NONE(默认): 跟随全局的设置(默认使用雪花算法)。
-
INPUT:手动输入或使用插件生成id。
-
ASSIGN_ID:可以在分布式的情况下使用,生成的是Long类型的数字,可以排序性能也高,但是生成的策略和服务器时间有关,如果修改了系统时间就有可能导致出现重复主键。
-
ASSIGN_UUID:可以在分布式的情况下使用,而且能够保证唯一,但是生成的主键是32位的字符串,长度过长占用空间而且还不能排序,查询性能也慢。
-
综上所述,每一种主键策略都有自己的优缺点,根据自己项目业务的实际情况来选择使用才是最明智的选择。
-
雪花算法(SnowFlake),是Twitter官方给出的算法实现 是用Scala写的。其生成的结果是一个64bit大小整数,它的结构如下图:
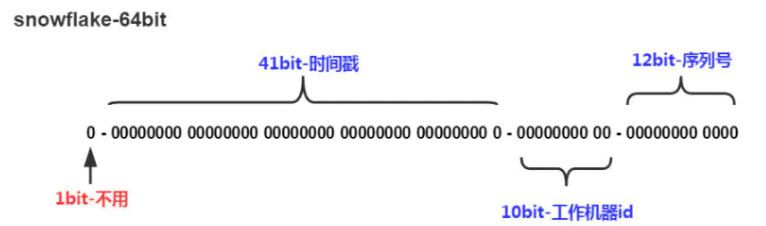
-
1bit,不用,因为二进制中最高位是符号位,1表示负数,0表示正数。生成的id一般都是用整数,所以最高位固定为0。
-
41bit-时间戳,用来记录时间戳,毫秒级。
-
10bit-工作机器id,用来记录工作机器id,其中高位5bit是数据中心ID其取值范围0-31,低位5bit是工作节点ID其取值范围0-31,两个组合起来最多可以容纳1024个节点。
-
序列号占用12bit,每个节点每毫秒0开始不断累加,最多可以累加到4095,一共可以产生4096个ID。
2.2 修改id生成策略
1. 局部配置
@TableId(type = IdType.AUTO) id自增策略
用在实体类的属性上
2. 全局配置
配置文件中配置:
mybatis-plus:
global-config:
db-config:
id-type: auto
注意:使用自增策略要求数据库中开启自动递增
2.3 映射匹配设置
1. @TableFiled
| @TableField | |
|---|---|
| 类型 | 属性注解 |
| 位置 | 模型类属性定义上方 |
| 作用 | 设置当前属性对应的数据库表中的字段关系 |
| 相关属性 | value(默认):设置数据库表字段名称 exist:设置属性在数据库表字段中是否存在,默认为true,此属性不能与value合并使用 |
2. @TableName
实体类与表名不一致可以手动指定表名。
| 名称 | @TableName |
|---|---|
| 类型 | 类注解 |
| 位置 | 模型类定义上方 |
| 作用 | 设置当前类对应于数据库表关系 |
| 相关属性 | value(默认):设置数据库表名称 |
也可以全局配置给实体类加上前缀:
mybatis-plus:
global-config:
db-config:
table-prefix: tbl_
3. 更新操作
在MP中有两种更新:根据Id更新,根据指定条件更新
3.1 根据Id更新
/** * 根据 ID 修改 * * @param entity 实体对象 */ int updateById(@Param(Constants.ENTITY) T entity);
直接传入实体类,根据尸体了的Id进行修改:
对于赋值了的属性进行修改,没有赋值的不进行修改。
3.2 根据条件更新
/** * 根据 whereEntity 条件,更新记录 * * @param entity 实体对象 (set 条件值,可以为 null) * @param updateWrapper 实体对象封装操作类(可以为 null,里面的 entity 用于生成 where 语句) */ int update(@Param(Constants.ENTITY) T entity, @Param(Constants.WRAPPER) Wrapper<T> updateWrapper)
wrapper是条件的包装类
在wrapper中设置好条件后作为参数直接传入方法即可。
例如:
@Test void contextLoads() { User user = new User(); //设置更新的字段 user.setEmail("Arvin@123.com"); UpdateWrapper<User> updateWrapper = new UpdateWrapper<>(); //设置更新的条件 updateWrapper.eq("uid", 6L); int i = userMapper.update(user, updateWrapper); }
结果:

也可以用updateWrapper.set()设置更新的字段
//设置更新的字段 updateWrapper.set("age", 28);
4. 删除操作
4.1 根据Id删除
/** * 根据 ID 删除 * * @param id 主键ID */ int deleteById(Serializable id); /** * 根据实体(ID)删除 * * @param entity 实体对象 * @since 3.4.4 */ int deleteById(T entity);
//方式一
userMapper.deleteById(1);
//方式二
User user=new User();
user.setId=2;
userMapper.deleteById(user);
4.2 根据条指定字段删除
/** * 根据 columnMap 条件,删除记录 * * @param columnMap 表字段 map 对象 */ int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
例:
@Test void contextLoads() { Map<String, Object> columnMap = new HashMap<>(); columnMap.put("uname","Jack"); columnMap.put("age",20); //将columnMap中的键值对设置为删除的条件,多个之间为and关系 int i = this.userMapper.deleteByMap(columnMap); }
结果:

4.3 根据指定条件(wrapper)删除
/** * 根据 entity 条件,删除记录 * * @param queryWrapper 实体对象封装操作类(可以为 null,里面的 entity 用于生成 where 语句) */ int delete(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
例:
@Test void contextLoads() { QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper.eq("uname", "Tom"); queryWrapper.eq("age", "28"); int i = userMapper.delete(queryWrapper); }
结果:

默认使用 AND 连接条件,如果用OR,调用 queryWrapper.or()即可。
4.4 根据id批量删除
/** * 删除(根据ID或实体 批量删除) * * @param idList 主键ID列表或实体列表(不能为 null 以及 empty) */ int deleteBatchIds(@Param(Constants.COLL) Collection<?> idList);
5. 查询操作