1、python里面下载相关依赖的包--jieba
实现中文分词和词频计算:
import csv
import jieba
with open('E:\Data\Code\pythonProject\hlm.txt',encoding='utf-8') as fp:
text = fp.read()
print(text)
ls = jieba.lcut(text) # 执行jieba分词操作
print(ls)
# 统计词频
counts={}
for i in ls:
if len(i)>1:
counts[i]=counts.get(i,0)+1
# 词频排序
ls1=sorted(counts.items(),key=lambda x:x[1],reverse=True)
print(ls1[:20])
# 将词频信息存储到csv文件中
f = open('rrr.csv','w',encoding='utf-8')
csv_writer=csv.writer(f)
csv_writer.writerow(['词语','词频'])
length = len(ls1)
for i in range(length):
csv_writer.writerow([ls1[i][0],ls1[i][1]])
2、使用代码生成词云
导入相关依赖:
numpy、pandas、wordcloud、matplotlib
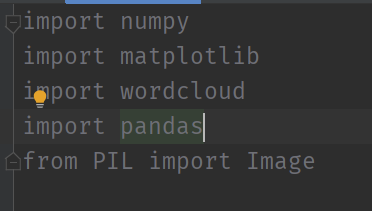
生成词云的话,依赖的库一直出现问题,我再看看~