Overview
文件系统的设计目标就是组织和存储数据,文件系统一个比较重要功能是持久化,即重启之后,数据不会丢失。xv6 通过把数据存储在 virtio disk 上来实现持久化。
文件系统设计的几大挑战:
- The file system needs on-disk data structures to represent the tree of named directories and files, to record the identities of the blocks that hold each file’s content, and to record which areas of the disk are free.
- 由于文件系统需要实现持久化,因此必须要实现 crash recovery,即如果发生意外的 crash(例如断电),文件系统在计算机重启之后要能依旧正常工作;
- 可能有多个进程同时操作文件系统;
- 由于访问磁盘比访问内存要慢得多得多,因此文件系统需要能支持将部分 popluar 的 blocks 缓存在内存中;
xv6 的文件系统可以说组织为七层,如下图所示:

disk layer 负责读写 virtio hard drive 上的 blocks,buffer cache layer 是 blocks 的 cache,并且保证同一时间,只有一个内核进程可以修改存储在特定块上的数据;logging layer 将对几个特定 block 的更新打包为一次 transaction(就是数据库常说的事务?),从而确保这些 blocks 都是被原子化地更新,即要么一次都更新,要么一次都不更新;inode layer 则是用来表示单独的文件,每个文件都是以具有不重复的 index 的 inode 和保存了这个文件的数据的一些 blocks 来表示;而在 directory layer,每个 directory 都是一种特殊的 inode,包含一系列 direcotry entry,directory entry 则是包含了文件名和 index(对应 indode layer 所说的 index);pathname layer 提供了层级化的路径名,利用递归查找来解析它们;
disk hardware 一般将磁盘划分为 $512$ bytes 的 block 的序列(这个 $512$ bytes 的 block 又称为 sector(扇区))。xv6 使用的 block 的大小一般是 sector 大小的整数倍。

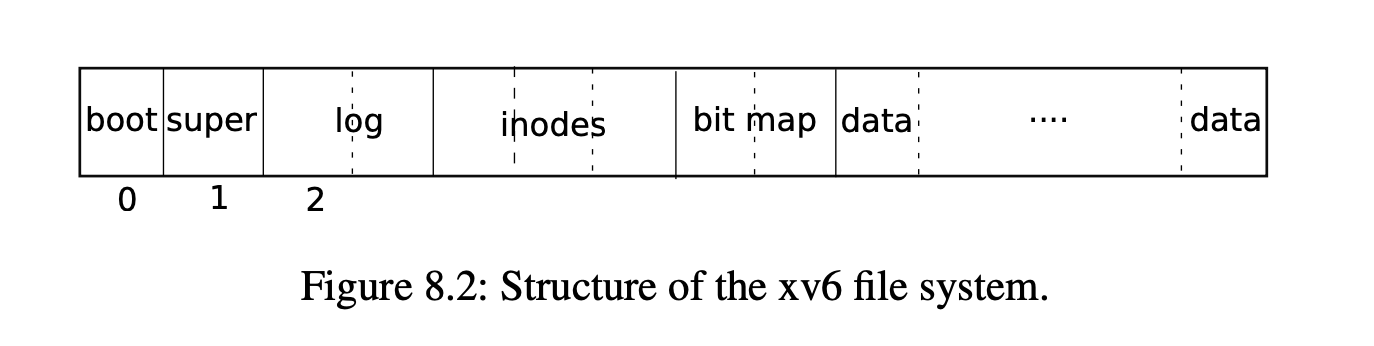
xv6 将磁盘划分为几个功能部分,如下图所示:
Buffer cache layer
buffer cache 的实现代码在 kernel/bio.c, 它主要有两个任务:
- 同步进程对磁盘的访问,内存中只有一份磁盘的 block 的拷贝,并且同一时间内只有一个进程可以使用这份拷贝(同时读呢,是否可行?);
- 缓存 popluar blocks 到内存中,从而可以直接从内存访问磁盘的 popular blocks,避免再从速度极其慢的磁盘中读取;
这里记
struct buf的一个实例为 buffer
buffer cache 的主要接口是 bread 和 bwrite, bread 返回一个存储于内存中的 buffer(会被加锁),我们可以读取或者修改这个 buffer,bwrite 负责将一个修改过的 buffer 写回到磁盘中合适的 block 去,当完成 bwrite 时,内核线程需要调用 brelse 来释放 buffer 的锁(是一个 sleep-lock,可以理解为与自旋锁相对?)
bread会返回带锁的buf,因为bread调用bget,而bget会加锁,加的是 sleep-lock,相当于 pthread 中的互斥锁(与自旋锁 spin-lock 相对); 使用 sleep-lock 是因为磁盘相关的操作,可能会消耗比较长的时间;
那些 poplular 的 blocks 其实被缓存在一个 buffer 的双向链表里面(这个双向链表是首尾相接的),双向链表的长度是有限的,这就意味着需要有缓存淘汰机制,xv6 中,这里使用了 LRU,head->prev 应该是 least recently used,而 head->next 则是 most recently。这里的头结点 head 应该是虚拟头结点?TODO(zwyyy)
Code: Buffer cache
buffer cache 实际上是 buffer 的双向链表,kernel/main.c 的 main 函数调用 binit,使用静态数组 buf 中的 NBUF 个 struct buf 来初始化这个链表,数组只用来初始化,之后访问 buffer 都是通过双向链表都是通过 bcache.head,也就是说这个数组只用来初始化链表!
buffer 中含有两个状态字段,valid 说明这个 buffer 含有磁盘的 block 的拷贝,因此是有效的,disk 字段为 $1$ 说明 buffer 已经写回了 disk。
bread 可以读取指定 block 对应的 buffer,如果返回的 buffer 的 valid 字段为 $0$,说明 get 是利用 lru 机制选择了一个 victim buffer,因此我们需要调用 virtio_disk_rw(b, 0) 将磁盘的对应 block 读入这个 buffer。
bget 遍历 buffer 链表寻找与 dev 和 blockno 对应的 buffer,并为这个 buffer 申请 sleep-lock,返回未解锁的 buffer;如果找不到对应的 buffer,bget 会从 head 开始,反向遍历双向链表,找一个 refcnt 为 $0$ 的 buffer,将这个 buffer 的 valid 字段标记为 $0$,即说明我们要重新从磁盘对应的 sector 读取数据到 buffer。
bget 持有 bache.lock 保证了“寻找对应的 buffer 以及如果不存在,为 block 分配对应的 buffer” 这个过程是原子的。
b->refcnt = 1 保证了这个 buffer 不会被其他进程拿来作为 victim buffer 去存放其他 block 的数据,因此可以先释放 bcache.lock 再申请 b->lock。
The sleep-lock protects reads and writes of the block’s buffered content, while the bcache.lock protects information about which blocks are cached.
如果 bread 的调用者通过 bread 拿到了这个 buffer,那么通过 b->lock,它享有了对这个 buffer 的独占权,如果它修改了这个 buffer 的内容,那么再释放 b->lock 之前,它必须调用 bwrite 将 buffer 的被修改的内容写回到 disk。
调用者完成对 buffer 的处理之后,必须调用 brelse 将 b->lock 释放。
Logging layer
file system 设计的一大重要问题就是 crash recovery。这是因为文件系统操作往往涉及向磁盘多次写入,而几次写入之后的 crash 可能导致磁盘上的文件系统处于一个不一致的状态。
For example, suppose a crash occurs during file truncation (setting the length of a file to zero and freeing its content blocks). Depending on the order of the disk writes, the crash may either leave an inode with a reference to a content block that is marked free, or it may leave an allocated but unreferenced content block.
前者当系统重启之后,可能导致一个磁盘 block 被两个文件所对应,这是一个很严重的问题。
xv6 的解决方法是使用 logging(日志)。xv6 的系统调用不会直接向 on-disk file system data structure(例如 buffer 以及磁盘 block?)写入,而是将它所有希望执行的磁盘写入的描述放在磁盘的某个 log 中,once the system call has logged all of its writes, it writes a special commit record to the disk indicating that the log contains a complete operation(这里不知道怎么翻译好了)。此时,系统调用才将 disk write 应用到 on-disk file system data structure。当所有的写入操作完成后,系统调用会清除磁盘上的 log。
如果系统崩溃重启,那么 file-system 代码会在运行进程之前,先检查磁盘上的 log。如果 log 被标记为包含完整的操作,那么 file-system recovery code 会将 log 中的写操作应用到对应的 on-disk file system;否则 file-system recovery code 会直接清除 log,不执行写入操作。
如果 file system 恢复时看到 log 被标记为不包含完整操作,那么说明 log 中的写入操作都还没有应用到磁盘上,即磁盘没有发生真正的写入,因此直接清除 log 即可,不需要执行任何写入操作。
log 使得这些写入操作对 crash 来说是原子的,要么都没写入,要么全都写入到磁盘了。
Log design
log 存在于磁盘的 superblock 中,它由一个 header block 和后面的一系列 updated block copies(更新块的副本,又称 logged blocks) 组成。header block 包含一个扇区号(sector index)的数组,每个 sector index 对应一个 logged block,还包含着 log blocks 的数量。header block 中的计数要么为 $0$,说明 log 中不存在 transaction,要么不为 $0$,说明 log 包含一个完整的已、已提交的 transaction,并包含指定数量的 logged blocks。
xv6 在 transaction 提交时,向 header block 写入数据,在将 logged blocks 复制到 file system 之后,将 header block 的计数置为 $0$。
为了允许 file system 的操作被不同进程并发执行,日志系统(logging system)会将多个系统调用的写操作合并成一个 transaction。因此,单次的 commit 可能涉及多个完整的系统调用的写操作,为了避免一次系统调用被划分成两次 transaction,日志系统只会在没有 file-system 系统调用的时候进行 commit。
一次一起 commit 多个 transaction 的方法被称为 group commit,group commit 能通过平摊一次提交的开销到多次操作上来降低所需的磁盘操作数。
xv6 在磁盘上标识出了一段固定大小的空间用来存放 log。因此,系统调用要写入的 blocks 必须能被这块空间容纳。对 write 和 unlink 系统调用来说,这个限制可能会导致两个问题:
- 假设
write要写一个大文件,那么可能要写入许多 data blocks、bitmap blocks 和 inode blocks,unlink一个大文件可能要写入许多 bitmap blocks 和 inode blocks。为了解决这一问题,xv6 的write会将一次大的写入划分成多个更小的适合 log 的写入操作,由于 xv6 只使用一个 bitmap lock,因此unlink不会造成问题; - 除非能确定系统调用的写入能容纳于 log 的剩余空间中,否则系统不会允许系统调用执行;
Code: logging
系统调用中的 log 的使用一般如下图所示:

begin_op wait until the logging system is not currently commiting, and until there is enough unreserved log space to hold the writes from this call. log.outstanding 会统计预订了 log space 的系统调用的数量,被预订的总空间就是 log.outstanding 乘上 MAXOPBLOCKS。递增 log.outstanding 会预订 log space,并且防止在此系统调用期间发生 commit。 xv6 保守地预计每个系统调用都会写入 MAXOPBLOCKS 个不同的 block。
log_write 表现得就像是 bwrite 的代理那样。它将 block 的 sector number 记录在内存中,在 disk 的 log 部分给这个 block 预留的了一个槽位,并调用了 bpin(b) 来保证 buffer b 一定不会被 evict。
调用
bpin(b)之后,哪怕 buffer 缓存不足时,buffer b 也不会被换出,它修改了 buffer b 的refcnt,之所以要这样设置,是因为假设 buffer b 中途被换出到磁盘,就违背了“必须 commit 之后再将写入应用到磁盘”的设定了,也就破坏了磁盘写入相对于 crash 的原子性。
void log_write(struct buf *b) {
int i;
acquire(&log.lock);
if (log.lh.n >= LOGSIZE || log.lh.n >= log.size - 1)
panic("too big a transaction");
if (log.outstanding < 1)
panic("log_write outside of trans");
for (i = 0; i < log.lh.n; i++) {
if (log.lh.block[i] == b->blockno) // log absorption
break;
}
log.lh.block[i] = b->blockno;
if (i == log.lh.n) { // Add new block to log?
bpin(b);
log.lh.n++;
}
release(&log.lock);
}
在 commit 之前,block 必须要缓存在 buffer 上, 这是因为 buffer 唯一地记录着我们对这个 block 的修改;只有在 commit 之后,才可以将 buffer 写入磁盘上的位置;同一 transaction 的假设要读取这个 block,那么它必须能看到对这个 buffer 的修改。log_write 会注意到一个 transaction 中,多次写入同一个 block 的情况,如果是写入同一个 block,那么就不会添加新 block 到 log 中,而是在 log 中为该 block 分配相同的槽位。这种优化通常被称为 absorption(合并),这样的话,从 buffer 写入到 log 的槽位只会发生一次,即使写入 buffer 发生了很多次。
end_op 首先会减少未完成的系统调用的计数(说明有系统调用完成了),如果计数被递减到了 $0$,它就会通过调用 commit() 来提交当前的 transaction。这个过程分为四个阶段:
write_log将每个在 transaction 被修改的 block 的 buffer 复制到 log 对应的槽位中(应该是复制到了 log 的 buffer 的对应的槽位中)write_head将 header block 从 buffer 写到磁盘中,而这就是 commit 的关键节点:- 当完成 header block 的从 buffer 写入到磁盘后,如果发生了 crash,那么恢复程序会从 log 中执行该次事务的写操作,将数据从 log 的 buffer 写入到磁盘;
install_trans会从 log 中读取每个 block,然后写入到文件系统(磁盘);end_op将 log header 的计数重置为 $0$(说明 log 中不存在 transaction),这会在下一个 transaction 要写入 logged blocks 之前完成,这保证了 crash 恢复时,不会将前一个 transaction 的 header 与下一个 transaction 的 logged blocks 混在一起恢复,即保证了一次恢复不会涉及两个 transaction。