参考:
transform的paper出处:https://blog.csdn.net/qq_40585800/article/details/112427990
发展
Transformer是由谷歌于2017年提出的具有里程碑意义的模型,同时也是语言AI革命的关键技术。在此之前的SOTA模型都是以循环神经网络为基础(RNN, LSTM等)。从本质上来讲,RNN是以串行的方式来处理数据,对应到NLP任务上,即按照句中词语的先后顺序,每一个时间步处理一个词语。
相较于这种串行模式,Transformer的巨大创新便在于并行化的语言处理:文本中的所有词语都可以在同一时间进行分析,而不是按照序列先后顺序。为了支持这种并行化的处理方式,Transformer依赖于注意力机制。注意力机制可以让模型考虑任意两个词语之间的相互关系,且不受它们在文本序列中位置的影响。通过分析词语之间的两两相互关系,来决定应该对哪些词或短语赋予更多的注意力。
什么是 Transformer?
Transformer 是 Google 的研究者于 2017 年在《Attention Is All You Need》一文中提出的一种用于 seq2seq 任务的模型,它没有 RNN 的循环结构或 CNN 的卷积结构,在机器翻译等任务中取得了一定提升。
transformer的优势
1.Transformer能够利用分布式GPU进行并行训练,提升模型训练效率
2.Transformer能够分析预测较长的序列,捕获较长的语义信息
3.自注意力可以产生更具可解释性的模型。我们可以从模型中检查注意力分布。
Transformer架构
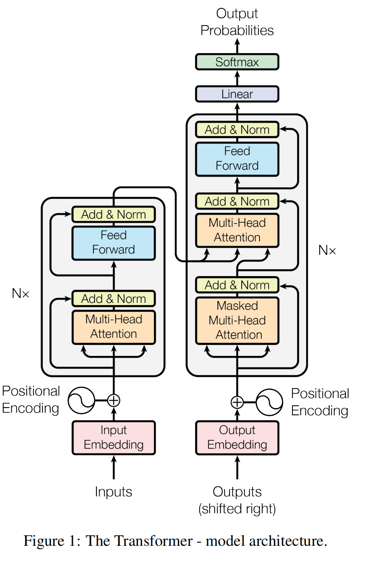
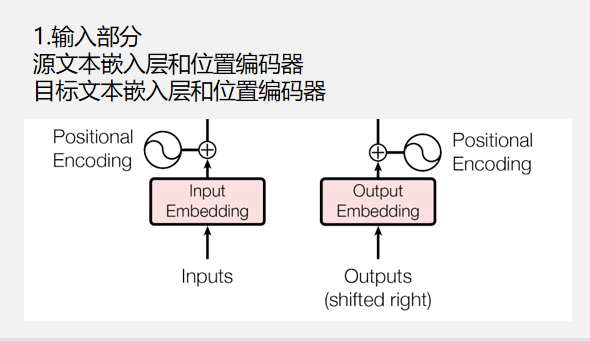
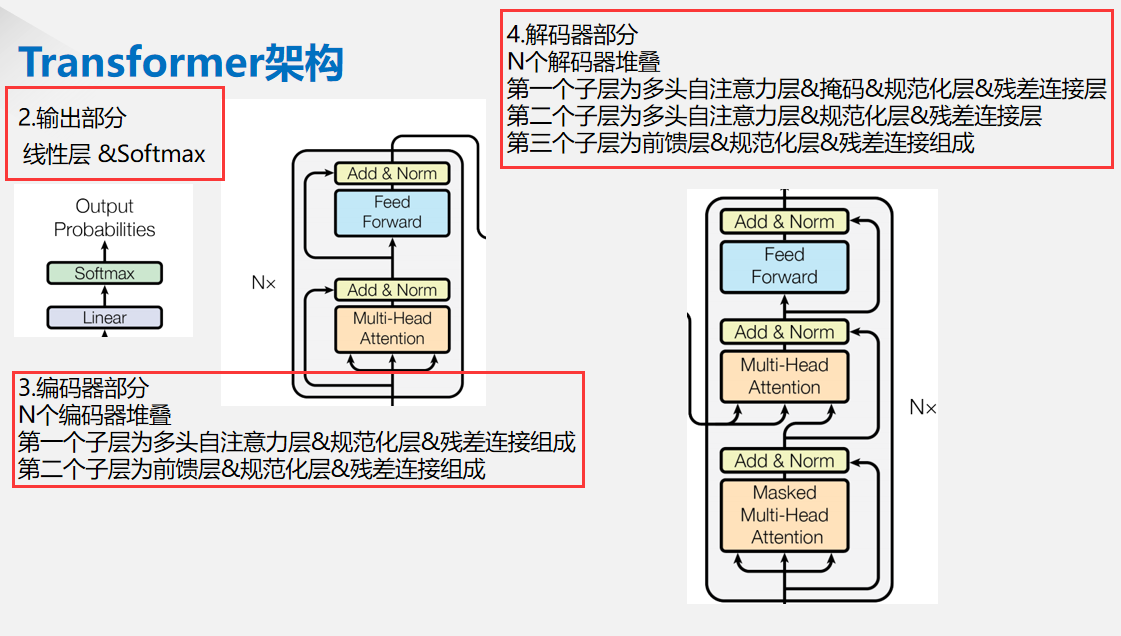
小细节
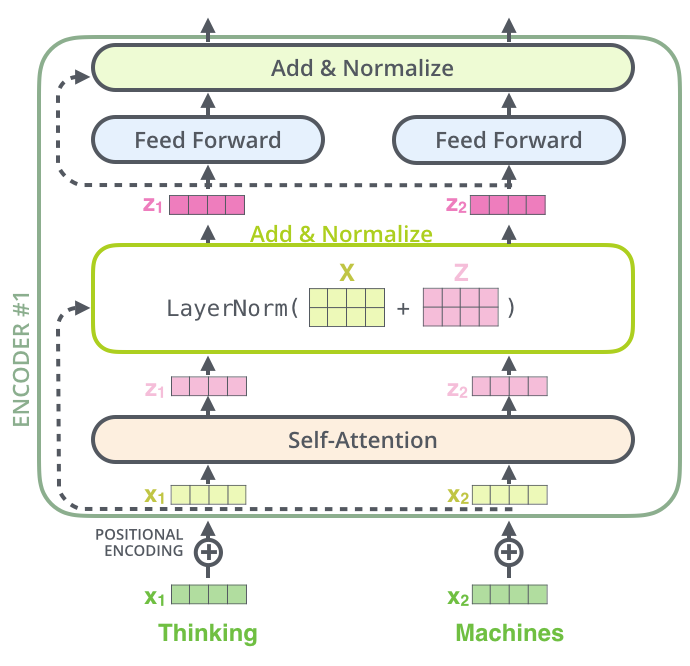
Layer normalization
在transformer中,每一个子层(自注意力层,全连接层)后都会有一个Layer normalization层,如下图所示:
Normalize层的目的就是对输入数据进行归一化,将其转化成均值为0方差为1的数据。
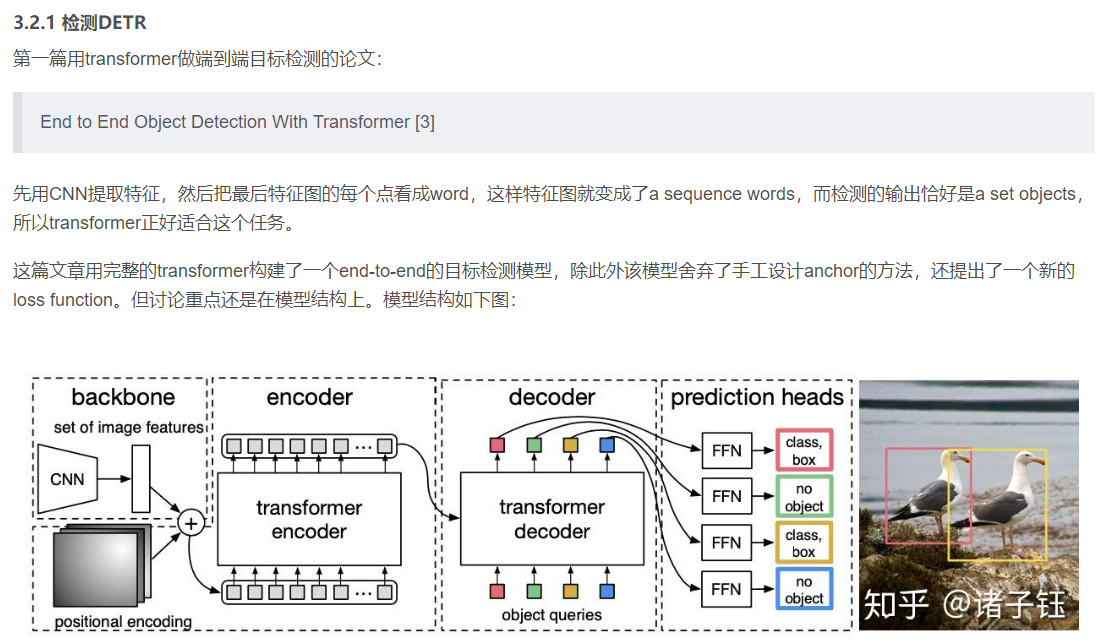
CV领域论文
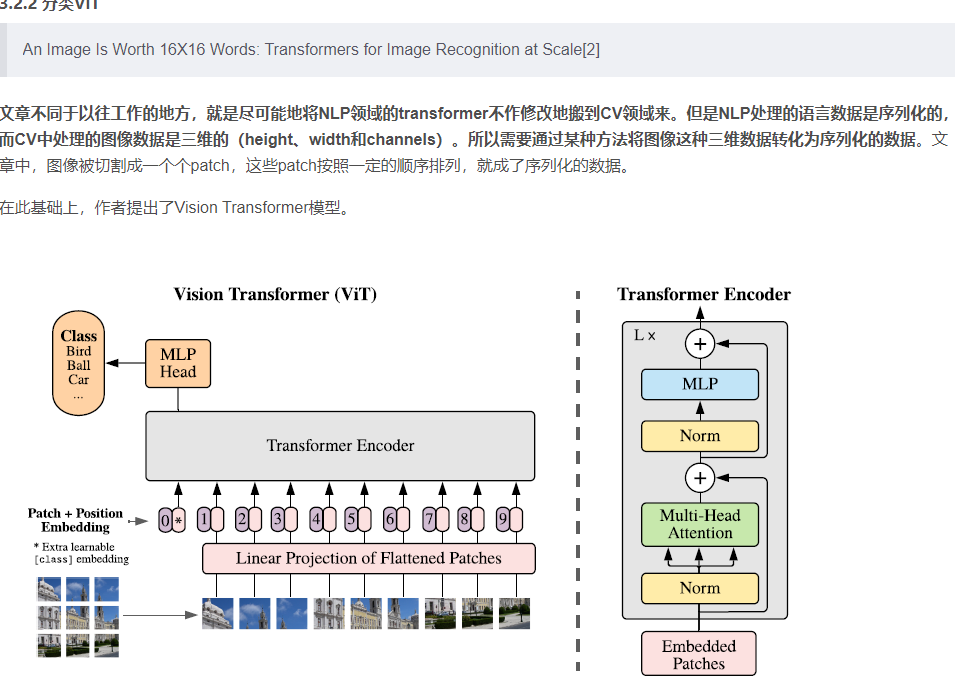
这篇文章首先尝试在几乎不做改动的情况下将Transformer模型应用到图像分类任务中,在 ImageNet 得到的结果相较于 ResNet 较差,这是因为Transformer模型缺乏归纳偏置能力,例如并不具备CNN那样的平移不变性和局部性,因此在数据不足时不能很好的泛化到该任务上。
然而,当训练数据量得到提升时,归纳偏置的问题便能得到缓解,即如果在足够大的数据集上进行与训练,便能很好地迁移到小规模数据集上。
在实验中,作者发现,在中等规模的数据集上(例如ImageNet),transformer模型的表现不如ResNets;而当数据集的规模扩大,transformer模型的效果接近或者超过了目前的一些SOTA结果。作者认为是大规模的训练可以鼓励transformer学到CNN结构所拥有的translation equivariance 和locality.
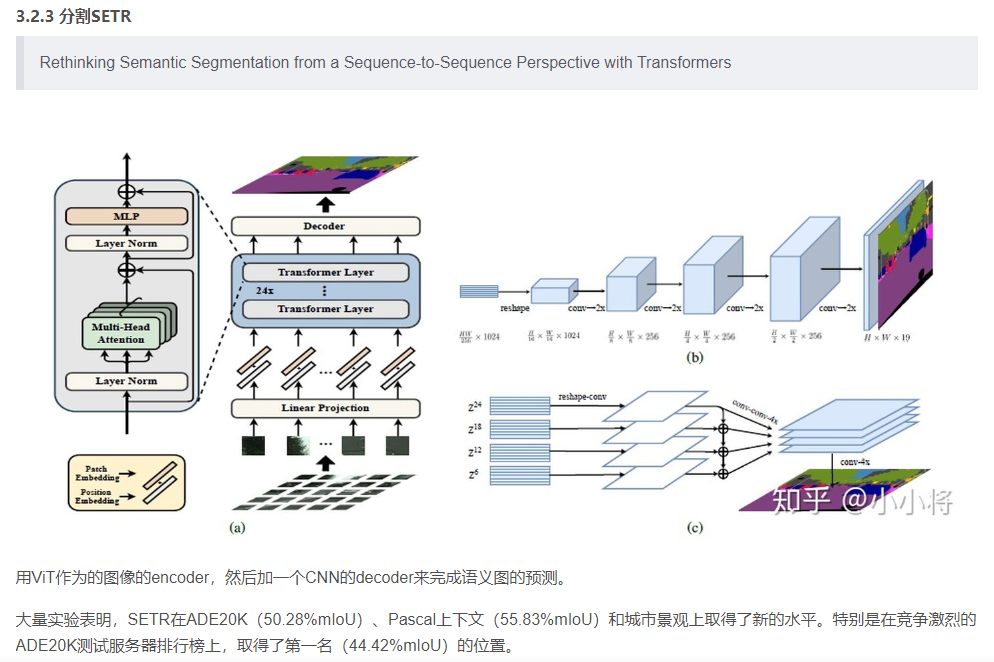
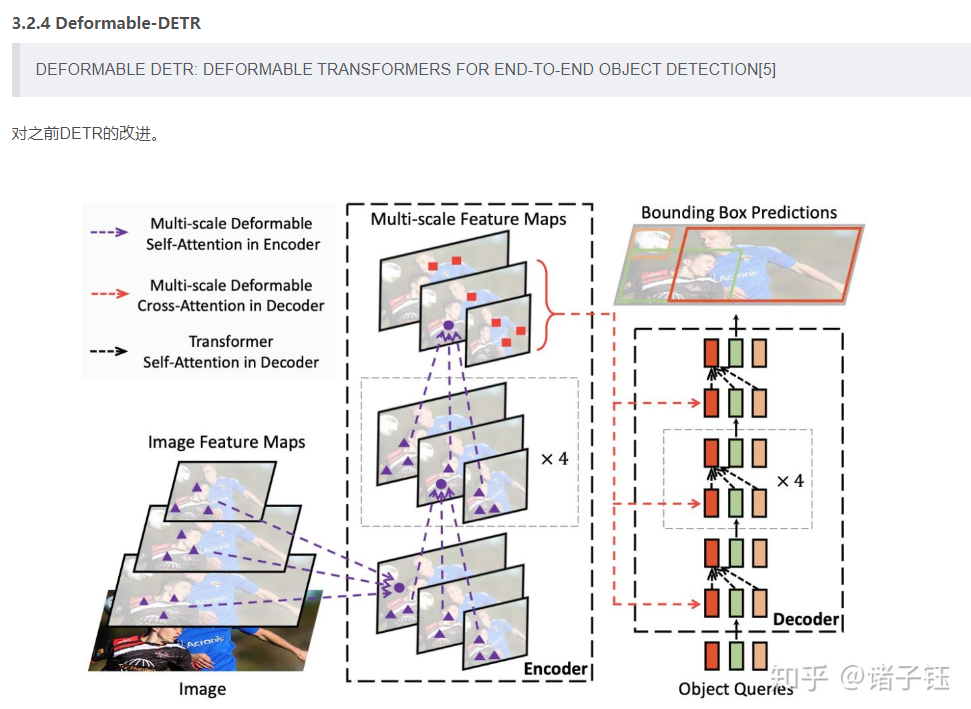
3.2.4 Deformable-DETR
Xizhou Zhu, Weijie Su2, Lewei Lu, Bin Li , Xiaogang Wang, Jifeng Dai. DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION. SenseTime Research, University of Science and Technology of China, The Chinese University of Hong Kong