1.数据解析
-使用response.xpath("xpath表达式")
-scrapy封装的xpath和etree中的xpath区别:
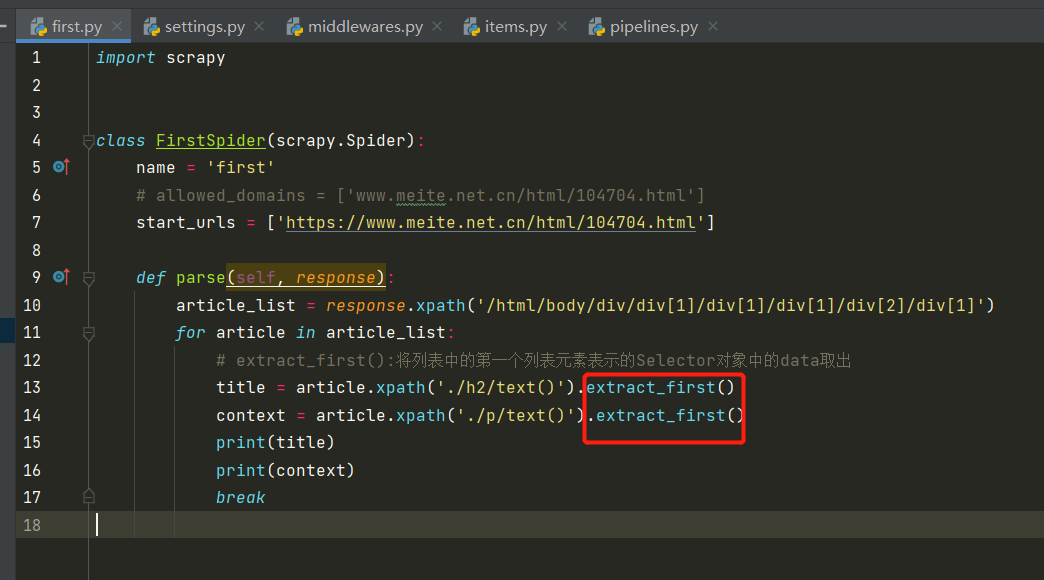
-scrapy中的xpath直接将定位到的标签中存储的值或者属性值取出,返回的Selector对象数据值是存储在Selector对象的data属性,需要调用extract、extract_first()取出
2.持久化存储
-基于终端指令的持久化存储
-要求:该种方式只可以将parse方法的返回值存储到本地指定后缀的文本文件中
-执行命令:scrapy crawl 爬虫文件名 -0 filePath
-基于管道的持久化存储
-在爬虫文件中进行解析(如上图所示)
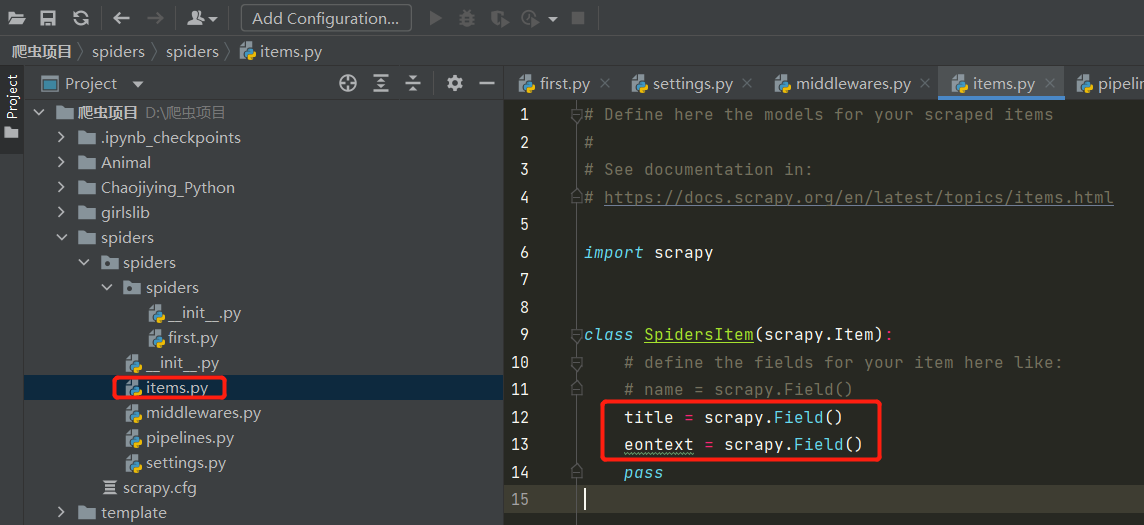
-在item.pyt中定义相关属性
-步骤1中解析了title和context字段数据,那就就定义这两个属性
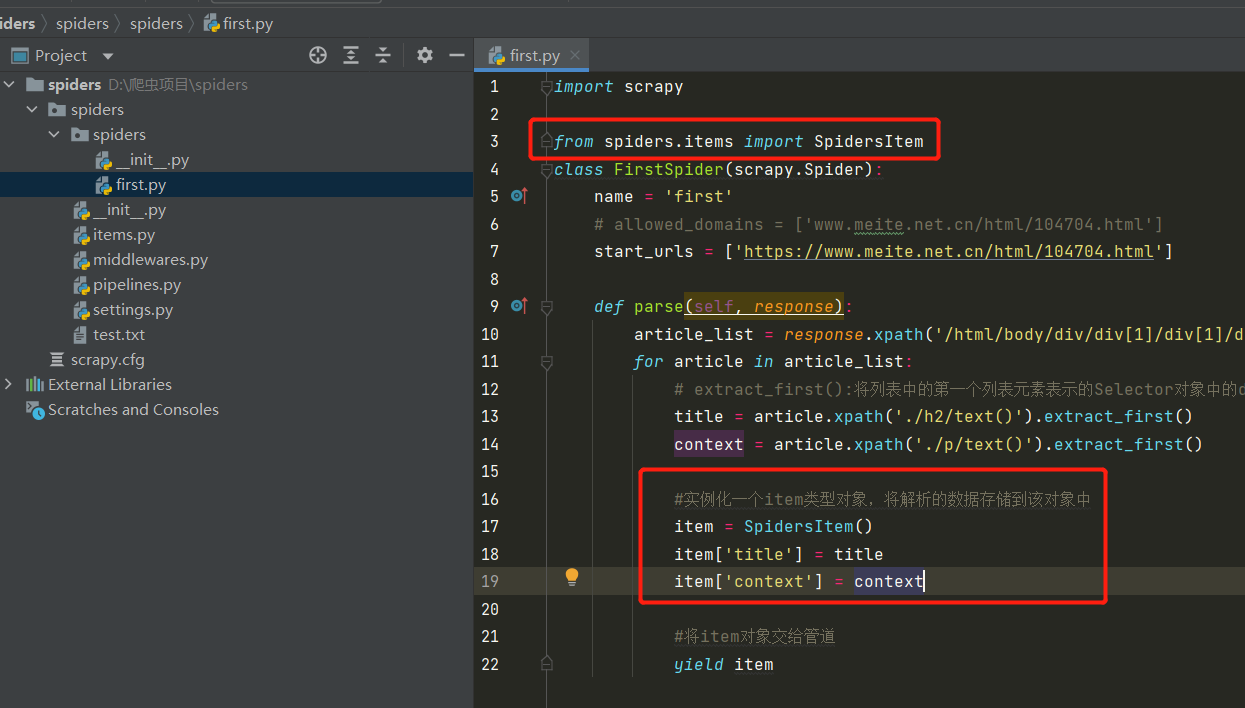
-在爬虫文件中将解析到的数据存储封装到Item类型的对象中
-将Item类型的对象提交给管道
-在管道文件(pipelines.py)中,接收爬虫文件提交过来的Item类型对象,且对其进行任意形式的持久化操作

-在配置文件中开启管道机制
300表示:管道嘞优先级,数值越小,优先级越高