池化技术:如何减少频繁创建数据库连接的性能损耗?
它的核心思想是空间换时间,期望使用预先创建好的对象来减少频繁创建对象的性能开销,同时还可以对对象进行统一的管理,降低了对象的使用的成本,总之是好处多多。需要注意的是最小连接数和最大连接数。
- 如果当前连接数小于最小连接数,则创建新的连接处理数据库请求;
- 如果连接池中有空闲连接则复用空闲连接;
- 如果空闲池中没有连接并且当前连接数小于最大连接数,则创建新的连接处理请求;
- 如果当前连接数已经大于等于最大连接数,则按照配置中设定的时间(C3P0 的连接池配置是 checkoutTimeout)等待旧的连接可用;
- 如果等待超过了这个设定时间则向用户抛出错误。
查询请求增加时,如何做主从分离?
在发微博的过程中会有些同步的操作,像是更新数据库的操作,也有一些异步的操作,比如说将微博的信息同步给审核系统,所以我们在更新完主库之后,会将微博的 ID 写入消息队列,再由队列处理机依据 ID 在从库中获取微博信息再发送给审核系统。此时如果主从数据库存在延迟,会导致在从库中获取不到微博信息,整个流程会出现异常。
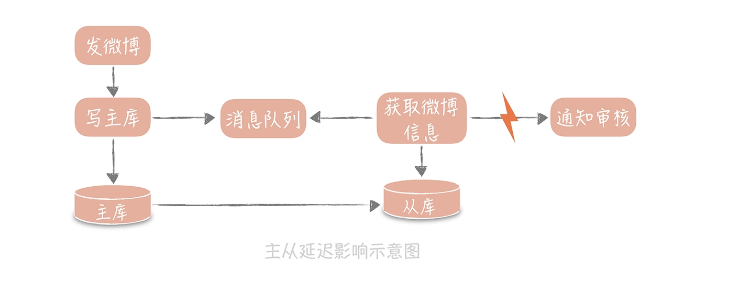
这个问题解决的思路有很多,核心思想就是尽量不去从库中查询信息,纯粹以上面的例子来说,我就有三种解决方案:
第一种方案是数据的冗余。你可以在发送消息队列时不仅仅发送微博 ID,而是发送队列处理机需要的所有微博信息,借此避免从数据库中重新查询数据。
第二种方案是使用缓存。我可以在同步写数据库的同时,也把微博的数据写入到 Memcached 缓存里面,这样队列处理机在获取微博信息的时候会优先查询缓存,这样也可以保证数据的一致性。
最后一种方案是查询主库。我可以在队列处理机中不查询从库而改为查询主库。不过,这种方式使用起来要慎重,要明确查询的量级不会很大,是在主库的可承受范围之内,否则会对主库造成比较大的压力。我会优先考虑第一种方案,因为这种方式足够简单,不过可能造成单条消息比较大,从而增加了消息发送的带宽和时间。
写入数据量增加时,如何实现分库分表?
数据库分库分表的方式有两种:一种是垂直拆分,另一种是水平拆分。