一 选题背景:当今社会电影业发展迅速,各种电影层出不穷,人们很难从众多电影中找到适合自己看的好电影,该项目是给电影爱好者提供的,利用爬虫爬取豆瓣网上电影榜排名TOP250的电影,然后选取自己最喜欢的电影看,有电影名称,电影链接,导演,演员,以及有多少人观看并评分
一 选题背景:当今社会电影业发展迅速,各种电影层出不穷,人们很难从众多电影中找到适合自己看的好电影,该项目是给电影爱好者提供的,利用爬虫爬取豆瓣网上电影榜排名TOP250的电影,然后选取自己最喜欢的电影看,有电影名称,电影链接,导演,演员,以及有多少人观看并评分
二 机器学习设计案例设计方案:
1.主题式网络爬虫名称
《Python爬虫对豆瓣Top250电影网的数据爬取以及分析》
2.主题式网络爬虫爬取的内容与数据特征分析
爬取内容:豆瓣Top250
网址:豆瓣电影 (douban.com)
3.主题是网络爬虫设计方案概述
实现思路:在浏览器中通过F12访问网页源代码,,分析网站源代码,找到自己所需要的数据所在的位置,提取数据,对数据进行保存到相同路径csv文件中,读取改文件,进行数据清洗,数据模型分析,数据可视化处理,绘制分布图,直方图,散点图
三 数据分析步骤
1.数据的爬取与采集:
import requests
from bs4 import BeautifulSoup
import pandas as pd
from sklearn.linear_model import LinearRegression
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
from scipy.optimize import leastsq
def get_html(url):
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}#伪装爬虫
resp = requests.get(url, headers = headers)
return resp.text
url = 'https://movie.douban.com/top250'
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('div', class_='hd')
电影名
film_name = []
for i in a:
film_name.append(i.a.span.text)
评分
rating_score = soup.find_all('span', class_='rating_num')
lt = []
num = 20
for i in range(num):
lt.append([i+1,film_name[i], rating_score[i].string])
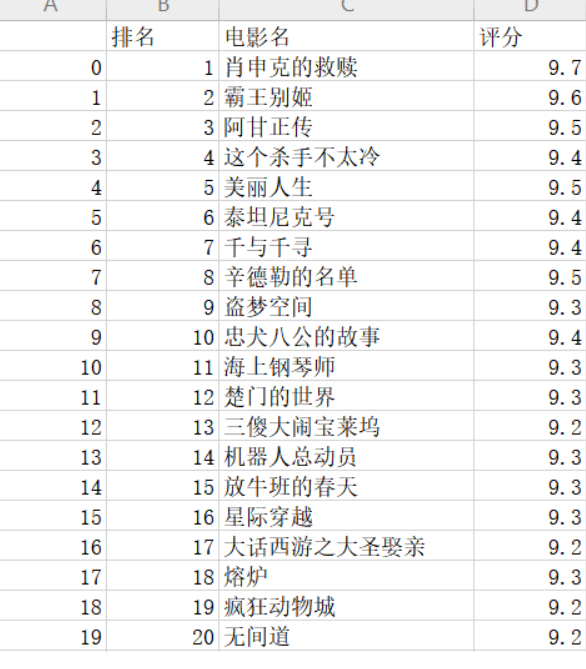
df = pd.DataFrame(lt,columns = ['排名', '电影名', '评分'])
df.to_csv('豆瓣电影数据.csv') #保存文件,数据持久化
2.对数据进行清洗和处理:
#读取csv文件
df = pd.DataFrame(pd.read_csv('豆瓣电影数据.csv'))
#print(df)
df.head()

检查是否有重复值
df.duplicated()

空值处理
df.isnull().sum()#返回0,表示没有空值
缺失值处理
df[df.isnull().values==True]#返回无缺失值

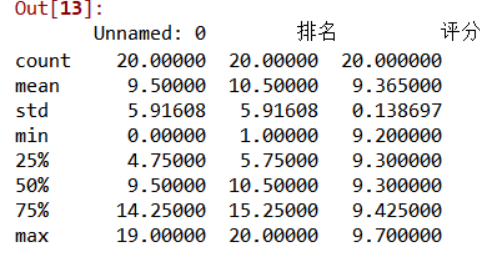
用describe()命令显示描述性统计指标
df.describe()
3.数据分析与可视化:
X = df.drop("电影名",axis=1)
predict_model = LinearRegression()
predict_model.fit(X,df['评分'])
print("回归系数为:",predict_model.coef_)
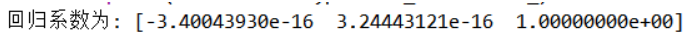
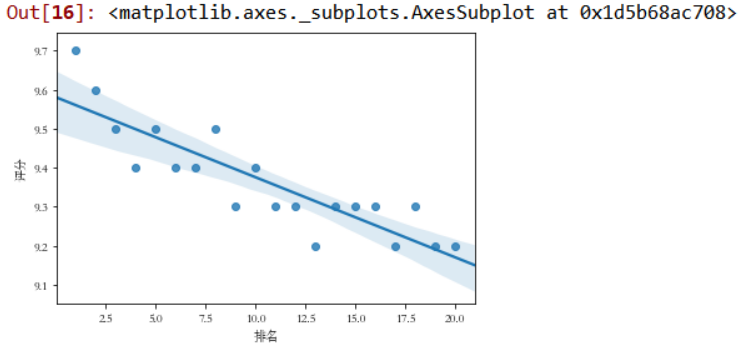
绘制排名与评分的回归图
plt.rcParams['font.sans-serif']=['STSong']#显示中文
sns.regplot(df.排名,df.评分)
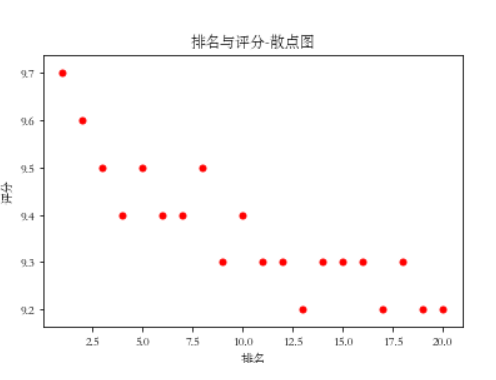
绘制散点图
def Scatter_point():
plt.scatter(df.排名, df.评分, color='red', s=25, marker="o")
plt.xlabel("排名")
plt.ylabel("评分")
plt.title("排名与评分-散点图")
plt.show()
Scatter_point()
绘制垂直柱状图
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.bar(df.排名, df.评分, label="排名与评分柱状图")
plt.show()
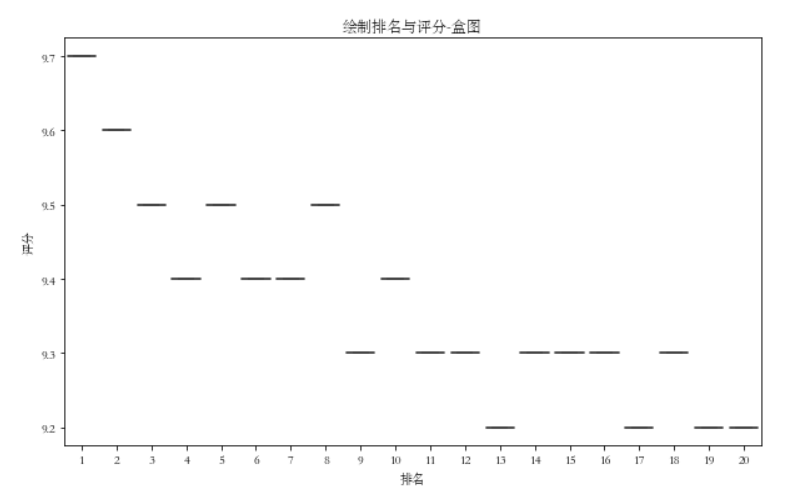
绘制排名与评分-盒图
def draw1():
plt.figure(figsize=(10, 6))
plt.title('绘制排名与评分-盒图')
sns.boxplot(x='排名',y='评分', data=df)
draw1()
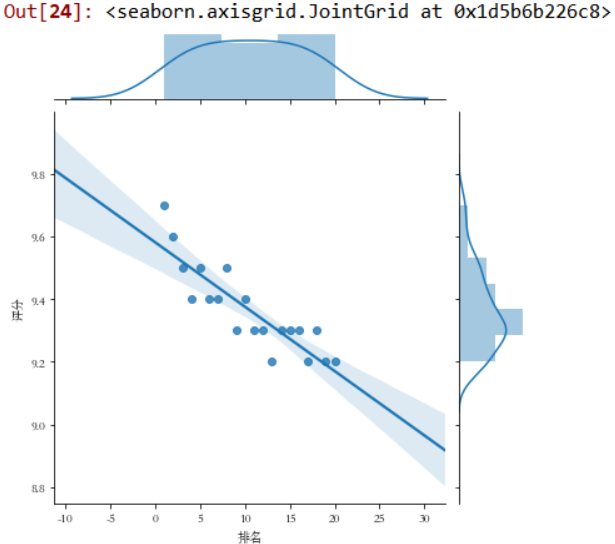
绘制部分分布图
sns.jointplot(x="排名",y='评分',data = df, kind='reg')
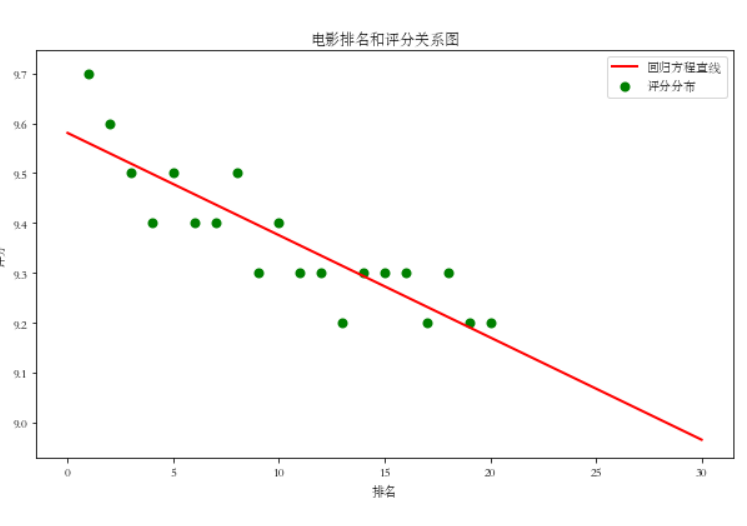
绘制一元一次回归方程
def main():
colnames = ["排名", "电影名", "评分"]
df = pd.read_csv('豆瓣电影数据.csv',skiprows=1,names=colnames)
X = df.排名
Y = df.评分
def func(p, x):
k, b = p
return k * x + b
def error_func(p, x, y):
return func(p,x)-y
p0 = [0,0]
Para = leastsq(error_func, p0, args = (X, Y))
k, b = Para[0]
print("k=",k,"b=",b)
plt.figure(figsize=(10,6))
plt.scatter(X,Y,color="green",label=u"评分分布",linewidth=2)
x=np.linspace(0,30,20)
y=k*x+b
plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2)
plt.title("电影排名和评分关系图")
plt.xlabel('排名')
plt.ylabel('评分')
plt.legend()
plt.show()
main()
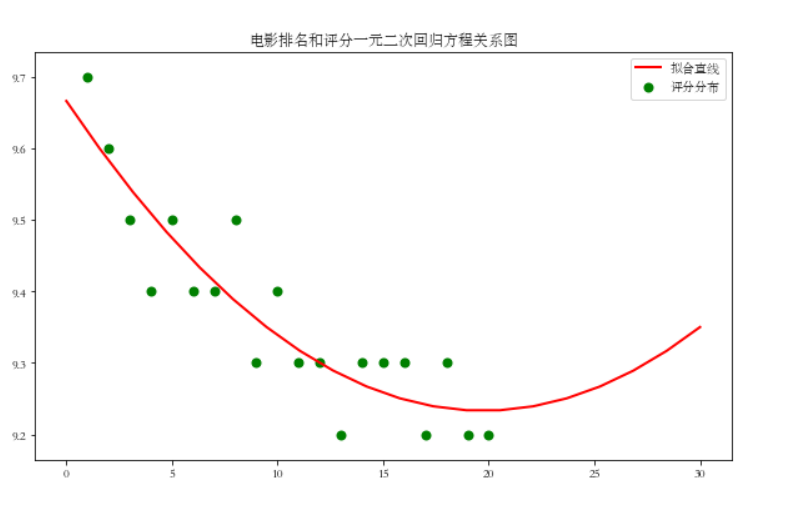
绘制一元二次回归方程
def one():
colnames = ["排名", "电影名", "评分"]
df = pd.read_csv('豆瓣电影数据.csv',skiprows=1,names=colnames)
X = df.排名
Y = df.评分
def func(p,x):
a,b,c=p
return a*x*x+b*x+c
def error_func(p,x,y):
return func(p,x)-y
p0=[0,0,0]
Para=leastsq(error_func,p0,args=(X,Y))
a,b,c=Para[0]
plt.figure(figsize=(10,6))
plt.scatter(X,Y,color="green",label=u"评分分布",linewidth=2)
x=np.linspace(0,30,20)
y=a*x*x+b*x+c
plt.plot(x,y,color="red",label=u"拟合直线",linewidth=2)
plt.title("电影排名和评分一元二次回归方程关系图")
plt.legend()
plt.show()
one()
完整代码
import requests
from bs4 import BeautifulSoup
import pandas as pd
from sklearn.linear_model import LinearRegression
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
from scipy.optimize import leastsq
def get_html(url):
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}#伪装爬虫
resp = requests.get(url, headers = headers)
return resp.text
url = 'https://movie.douban.com/top250'
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('div', class_='hd')
#电影名
film_name = []
for i in a:
film_name.append(i.a.span.text)
#评分
rating_score = soup.find_all('span', class_='rating_num')
lt = []
num = 20
for i in range(num):
lt.append([i+1,film_name[i], rating_score[i].string])
df = pd.DataFrame(lt,columns = ['排名', '电影名', '评分'])
df.to_csv('豆瓣电影数据.csv') #保存文件,数据持久化
#读取csv文件
df = pd.DataFrame(pd.read_csv('豆瓣电影数据.csv'))
#print(df)
df.head()
#检查是否有重复值
df.duplicated()
#空值处理
df.isnull().sum()#返回0,表示没有空值
#缺失值处理
df[df.isnull().values==True]#返回无缺失值
#用describe()命令显示描述性统计指标
df.describe()
#数据分析
X = df.drop("电影名",axis=1)
predict_model = LinearRegression()
predict_model.fit(X,df['评分'])
print("回归系数为:",predict_model.coef_)
#绘制排名与评分的回归图
plt.rcParams['font.sans-serif']=['STSong']#显示中文
sns.regplot(df.排名,df.评分)
# 绘制散点图
def Scatter_point():
plt.scatter(df.排名, df.评分, color='red', s=25, marker="o")
plt.xlabel("排名")
plt.ylabel("评分")
plt.title("排名与评分-散点图")
plt.show()
Scatter_point()
# 绘制垂直柱状图
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.bar(df.排名, df.评分, label="排名与评分柱状图")
plt.show()
#绘制排名与评分-盒图
def draw1():
plt.figure(figsize=(10, 6))
plt.title('绘制排名与评分-盒图')
sns.boxplot(x='排名',y='评分', data=df)
draw1()
#绘制分布图
sns.jointplot(x="排名",y='评分',data = df, kind='reg')
#绘制一元一次回归方程
def main():
colnames = ["排名", "电影名", "评分"]
df = pd.read_csv('豆瓣电影数据.csv',skiprows=1,names=colnames)
X = df.排名
Y = df.评分
def func(p, x):
k, b = p
return k * x + b
def error_func(p, x, y):
return func(p,x)-y
p0 = [0,0]
Para = leastsq(error_func, p0, args = (X, Y))
k, b = Para[0]
print("k=",k,"b=",b)
plt.figure(figsize=(10,6))
plt.scatter(X,Y,color="green",label=u"评分分布",linewidth=2)
x=np.linspace(0,30,20)
y=k*x+b
plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2)
plt.title("电影排名和评分关系图")
plt.xlabel('排名')
plt.ylabel('评分')
plt.legend()
plt.show()
main()
#绘制一元二次回归方程
def one():
colnames = ["排名", "电影名", "评分"]
df = pd.read_csv('豆瓣电影数据.csv',skiprows=1,names=colnames)
X = df.排名
Y = df.评分
def func(p,x):
a,b,c=p
return a*x*x+b*x+c
def error_func(p,x,y):
return func(p,x)-y
p0=[0,0,0]
Para=leastsq(error_func,p0,args=(X,Y))
a,b,c=Para[0]
plt.figure(figsize=(10,6))
plt.scatter(X,Y,color="green",label=u"评分分布",linewidth=2)
x=np.linspace(0,30,20)
y=a*x*x+b*x+c
plt.plot(x,y,color="red",label=u"拟合直线",linewidth=2)
plt.title("电影排名和评分一元二次回归方程关系图")
plt.legend()
plt.show()
one()
总结
1.经过对爬取的豆瓣电影数据分析,电影的评分和评价人数没有直接的关系,但是又间接的关系。
大多数口碑比较好的电影评价的人数就很多。所以,看电影的时候可以先看一下评分,再看一下评价人数的多少,来判断电影的好坏。
2.写完这个之后才发现,在即在爬虫上的不足,对于网页标签的摘取,和最后数据的处理都有一定的不足,每次遇到不会的还要去网上翻阅资料。有时候程序出现错误,自己知道错误在哪,但不知道如何更改以达到自己想要的目的。
这次爬虫花费了很大的时间和经历,是我觉得自学习刚接触编程语言以来做过最令我高兴的事情。