导读
重磅模型transformer,在2017年发布,但就今天来说产生的影响在各个领域包括NLP、CV这些都是巨大的!
Paper《Attention Is All You Need》,作者是在机器翻译这个领域进行的实验,当然我们今天知道它被应用到了很多地方,作者也在结论部分说它将被应用到图像、音频、视频等任务中,本文以机器翻译任务来解释transformer网络结构,之后还会在cv任务中进行介绍。

论文首先指出当前LSTM、GRU这些RNN系列网络和CNN存在的问题:
1) RNN使用隐藏层存储并传递前面时刻的信息,只能从左到右依次计算或从右至左依次计算,这限制了模型的并行能力;
2) RNN在序列过长会导致梯度爆炸或者梯度消失,这种顺序计算的过程中会有信息的丢失;
3) CNN使用卷积每次看比较小的窗口,对于距离较远的像素,需要用多层卷积一层层扩大感受野才能把两个像素建立关系;
而transformer能同时提取所有上下文信息,具有更好的并行性,符合GPU框架,并且将序列中的任意两个位置之间的距离都缩小为1,解决了长序列的依赖问题。
网络模型
Transformer的结构如下,它是一种encoder-decoder结构,现在来一个个解读其结构:
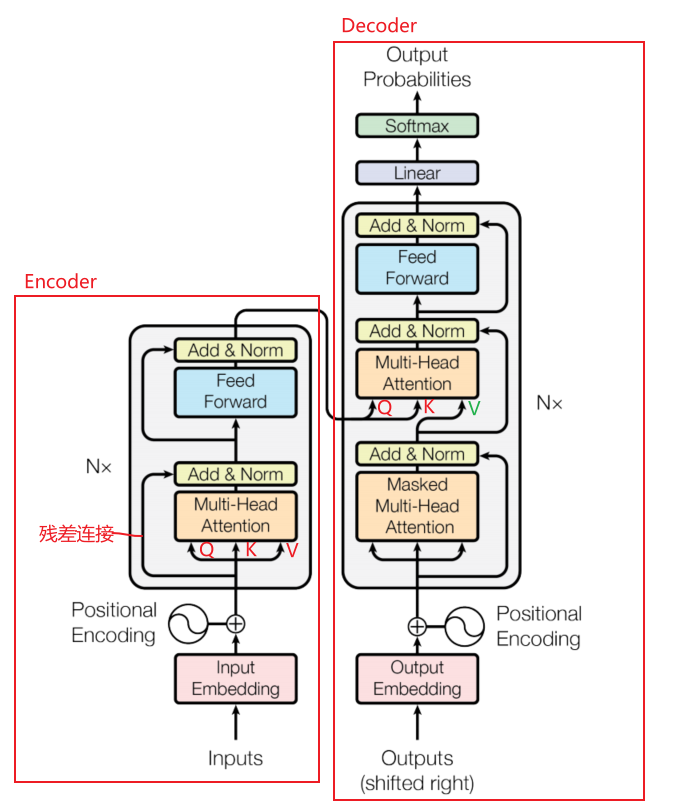
Encoder
- Embedding: 这里可理解为将我们喂进去数据集的语料(词)转化成特征向量,论文中使用的词嵌入向量的维度为512;
- Self-attention:这是Transformer的核心,在encoder中进入Multi-Head Attention(多个self-attention集成)的线有一条变成三条,这里表示每个词向量复制成3个向量,它们分别是Query向量(Q)、Key向量(K)和Value向量(V),由于它们三都是自己复制过来的,因此称为自注意力机制,他们的计算公式如下:
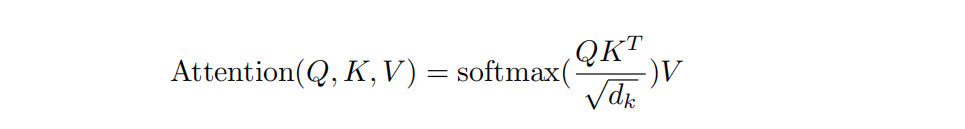
这里为什么要有Q,K,V呢,结合公式看下面示意图:
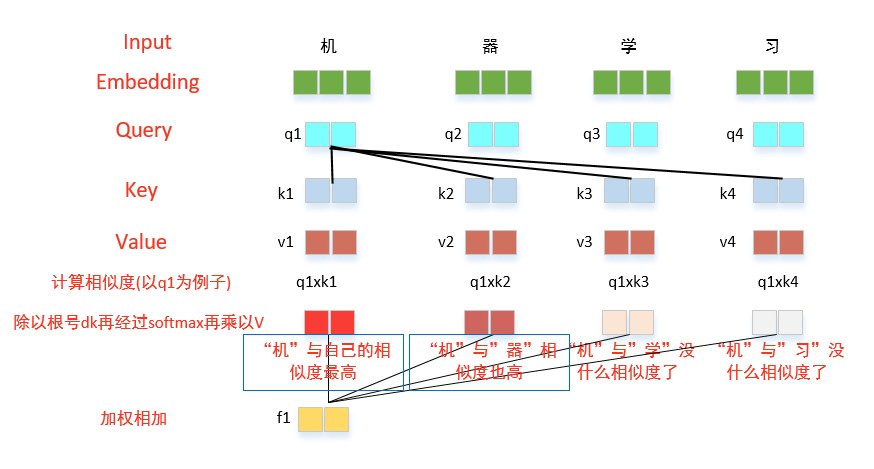
上述示意图展示了self-attention的计算过程,首先将输入转为嵌入向量,根据嵌入向量得到q,k,v三个向量,为每一个计算一个相似度q*k,为了梯度稳定,除以了根号dk,再经过softmax层就会得到一个非负、加起来和为1的权重分布,再与v相乘,之后加权得到输出的结果。
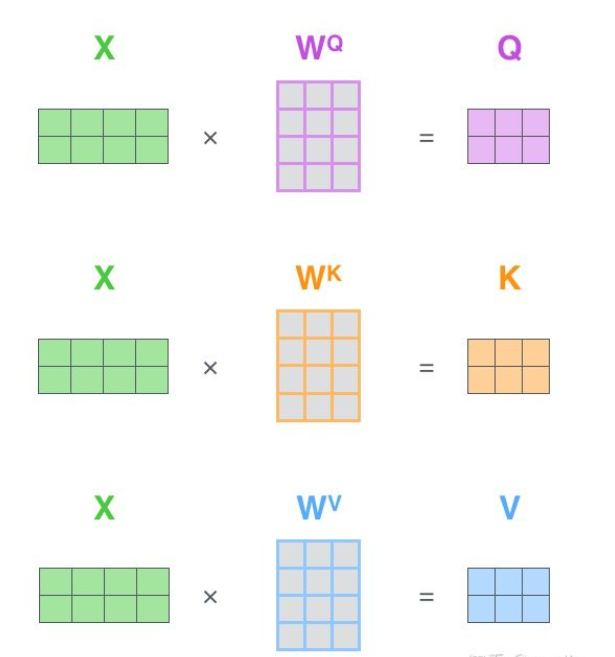
根据嵌入向量怎么得到q、k、v的呢? 看示意图,基于矩阵的方式得到:
- Multi-Head Attention:
Multi-Head Attention可以看成h个不同的self-attention的集成,论文中h设为了8,那为什么要有multi-head attention模块呢?一个解释是,我们希望它能像卷积里的多通道一样,不同的self-attention我们希望它看到不一样的东西,这种结构能将输入向量映射到不同的空间维度,提高transformer的抽取语义信息的能力,它的示意图如下:
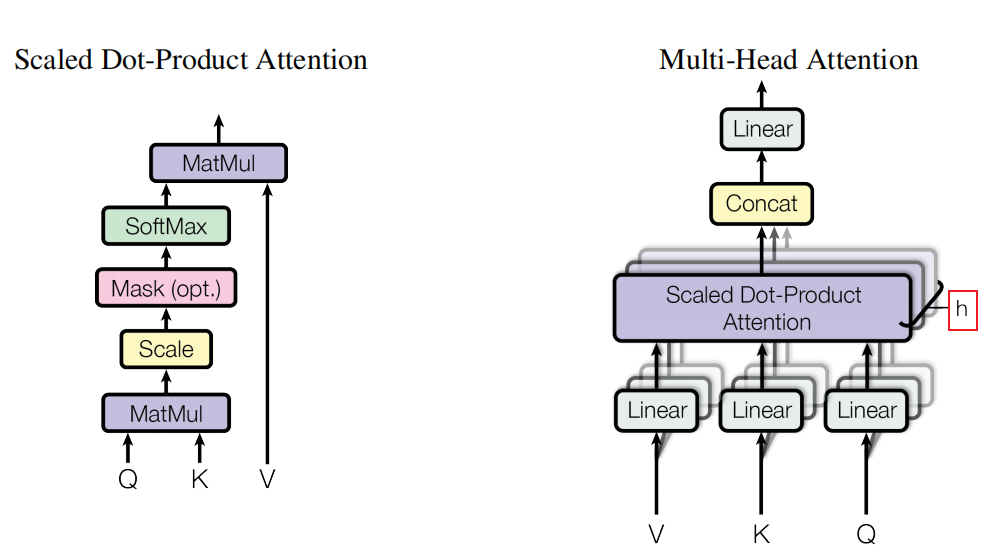
上图左侧示意图就是上述我们讲过的self-attention的计算过程,不过其中有个Mask的红色模块,这个我们放到后面介绍。右侧就是Multi-Head Attention模块,它先将Q、k、V输入,通过不同的线性层映射到不同的空间(每个空间是一个头),再分别在这些空间中进行左侧示意图的计算,最后将得到的结果进行拼接,再经过一个额外的映射层映射到原来的空间,这是计算公式:

- Add & Norm:
这是残差连接及归一化层,缓解网络随着深度的增加退化问题,能使模型训练得更深,归一化层用的是Layer Normalization(LN),它在有循环机制的网络和batchsize较小的时候效果好,它和Batch Normalization(BN)的区别在于归一化的维度是相互垂直的,其示意图如下:
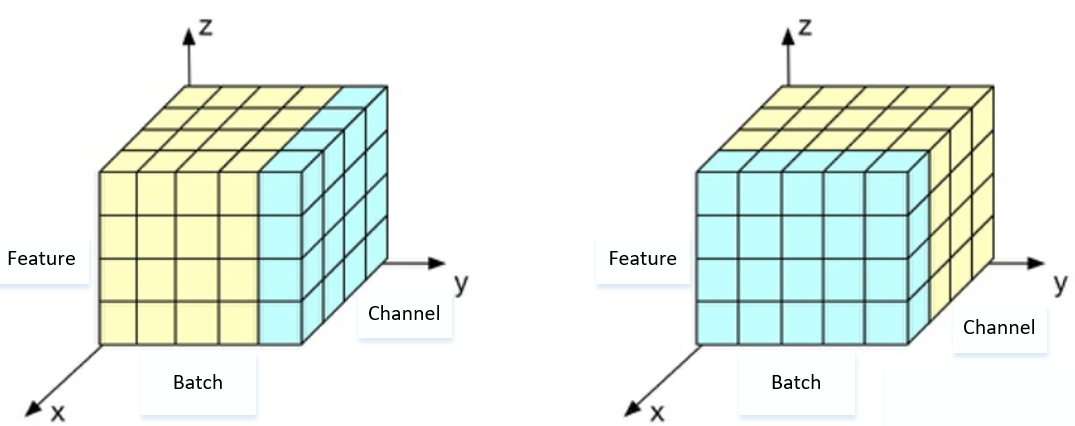
左侧是LN,它取的是同一个样本的不同通道做归一化;右侧是BN,它是取不同样本的同一通道的特征做归一化;那这里实际用起来有什么不一样呢?为什么transformer里是用的LN呢?首先第一个问题,我们可以从示意图中看到BN是按照样本计算归一化统计量的,我们知道,在NLP任务中,样本尺度不一,这种情况下算出的单个batch样本的均值和方差不能反映全局的统计分布信息,当测试时我们遇到大度大于任何一个训练样本的测试样本时,无法找到保持的归一化统计量。而LN与样本数多少无关,它根据样本的特征数做归一化,更符合NLP的规律。举个简单例子,如果把一批文本组成一个batch,BN就是对 batch 中每句话的同一位置的词进行操作,而 LN是对每一句 句子中的所有词 进行操作,这样的LN是不是更符合NLP了。
- Feed Forward:
论文中称此层为Position-wise Feed-Forward Network,它是由两个线性层和中间的一个由Relu组成的激活层构成。可以看做是kernel size 为1的卷积。输入的维度是512,中间层的维度是2048。
Decoder
- Masked Multi-Head Attention
我们知道作为decoder在预测当前步的时候,是不能让模型知道后面的内容的,而attention的计算方式是能够得到全局的信息,因此设计了这个模块,它具体的实现方法是:当预测第t步时,将t后面的变成很大的负数,这样经过softmax后这些负数就变成0了。
- Decoder流程解读
可以看到decoder也是有N层堆叠起来,对于其中的每一层,上半部分是与encoder结构一样,下半部分是由上面介绍的Masked Multi-Head Attention接上残差连接和LN层组成,我们注意到上半部分的输入来自两个部分,K、V来自Encoder的输出,而Q来自与解码器的上一个下半部分的输出,其计算方式就是我们上述介绍过的Attention的计算方法。之后经线性层、softmax得到反映每个单词概率的输出向量。
- Position Embedding:
我们从Transformer的模型结构中看到无论时encoder还是decoder都有一个Position模块,这是因为到目前为止我们介绍的transformer模型并没有捕捉顺序序列的能力,也就是说无论句子的结构怎么打乱,Transformer都会得到类似的结果,不像RNN,它从左至右计算,天生就有序列顺序能力。
因此论文中在编码词向量时引入了位置编码(Position Embedding)的特征,位置编码会在词向量中加入了单词的位置信息,这样Transformer就能区分不同位置的单词了。编码公式如下:
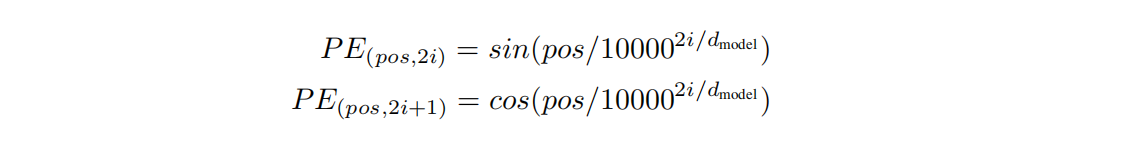
其中pos表示单词的位置,i表示emdedding向量中的位置,即512维中的每一维;
对于每个位置pos进行编码,然后与相应位置的word embedding进行相加,构成当前位置的新word embedding。
论文总结
1)Transformer不同与RNN需要从左至右计算,可以直接捕捉全文信息,算法的并行性非常好,且其设计最大的带来性能提升的关键是将任意两个单词的距离是1,这对解决NLP中棘手的长期依赖问题是非常有效的。
2)Embeddings and Softmax: 论文中将embedding层的参数与最后的Softmax层之前的线性变换层参数进行了共享,并且在embedding层,将嵌入的结果乘上维度的根号,这是为了缩小他们的间距。
3) 训练细节:初始化:PyTorch里面实现的是nn.xavier_uniform,优化器是以β1=0.9,β2=0.98和ϵ=10的负9次方的Adam为基础;正则化采用了两种,第一种是dropout,作用在Position-wise Feed-Forward Networks层的一个sub-layer的输出在加上下一个sublayer的输入做nomalized之前应用dropout,同时在embeddings和positional encodings求和时应用droput,论文种dropout设为0.1;第二种是Label Smoothing,这里论文取的ϵ=0.1,他们发现会损失困惑度,但能提升准确率和BLEU值,今天来看,label smoothing为什么能提点?它能合均匀分布,用更新的标签向量来代替传统的独热编码,这样label smoothing后的分布就相当于往真实分布中加入噪声,避免模型对于正确标签over confidences,使得预测正负样本的输出值差别不那么大,从而避免过拟合,提高模型的泛化能力。
4)transformer架构成为超大型自然语言文本预训练微调范式的奠基石,后来的Bert,GPT2这些都有其贡献,当然我们今天知道在图像这些任务上也大放异彩,其让文本、图像等多模态可集成在同一框架内。
实战训练
我提供了两种基于transformer的demo项目演示,分别在NLP任务的文本分类和CV任务
NLP
这里搭建了一个基于transformer的结构来进行文本分类任务的demo,你可以在github上访问。
CV
这里搭建了一个基于transformer的网络结构来进行detection任务的demo,你可以在github上访问。