slug: IoU总结
title: IoU总结
author: Runqi Zhao
author_title: Backend Developer
author_url: https://github.com/runqi-zhao
author_image_url: https://github.com/runqi-zhao.png
tags: [机器学习]
每次组会前的内容,都将进行再一次的总结,这次总结IoU,到最新的KFIoU,同时说明高斯分布与高斯分类
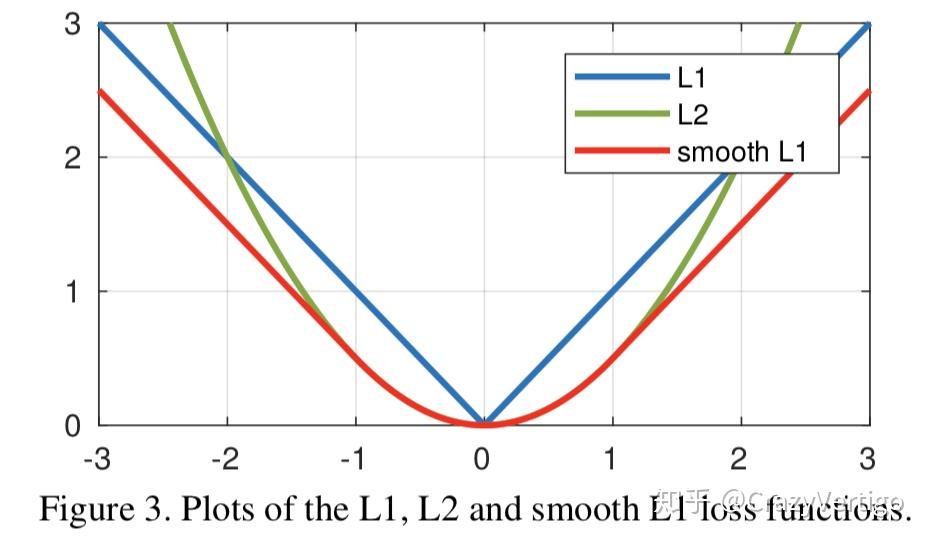
Smooth L1 Loss
假设x为预测框和真实框之间的数值差异(里面差异是灰度值的差异),常用的L1和L2 Loss定义为:
$$
L_1=|x|\frac{dL_2(x)}{x} = 2x \
L_2 = x^2 \
smooth_{L_1}(x) = \begin{cases}
0.5 x^2 &&if|x| < 1
\ |x| -0.5 &&otherwise,
\end{cases}
$$
上述的3个损失函数对x的导数分别为:
$$
\frac{dL_1(x)}{x} =\begin{cases}
1 &&ifx \geqslant 0
\ -1 &&otherwise,
\end{cases}
\
\frac{dL_2(x)}{x} = 2x
\
\frac{dsmoothL_1(x)}{x} = \begin{cases}
x &&if|x| < 1
\ \pm 1 &&otherwise,
\end{cases}
$$
从损失函数对x的导数可知: $L_1$损失函数对x的导数为常数,在训练后期,x很小时,如果learning rate 不变,损失函数会在稳定值附近波动,很难收敛到更高的精度。 $L_2$损失函数对x的导数在x值很大时,其导数也非常大,在训练初期不稳定。$smooth_{L_1}(x)$ 完美的避开了 $L_1$和 $L_2$损失的缺点。
实际目标检测框回归任务中的损失loss为
$$
L_{loc} = \sum{i\in{x,y,w,h}smooth_{L_1}(t^u_i - v_i)}
$$
其中$v= (v_x, v_y, v_w, v_h)$表示 GT 的框坐标,$t^{u} = \left( t_{x}^{u} ,t_{y}^{u} ,t_{w}^{u} ,t_{h}^{u} \right)$表示预测的框坐标,即分别求 4 个点的 loss,然后相加作为 Bounding Box Regression Loss。
在旋转物体检测中,通常使用IoU(Intersection over Union)作为损失函数的一部分来评估预测边界框与真实边界框之间的重叠程度,以及使用Smooth-L1损失函数来度量预测边界框与真实边界框之间的距离。
简介
IoU又名交并比,是一种计算不同图像相互重叠比例的算法,时常被用于深度学习领域的目标检测或语义分割任务中。
IoU在目标检测中的应用
在目标检测任务中,我们时常会让模型一次性生成大量的候选框(candidate bound),然后再根据每一个框的置信度对框进行排序,进而依次计算框与框之间的IoU,以非极大值抑制的方式,来判断到底哪一个是我们真正要找的物体,哪几个又该删除。例如在做人脸检测时,模型输出的可能是左图,而最终我们得到的是右图。

在我们得到最终的输出后,也可以拿输出框与原标记框(ground truth bound)之间的IoU,使用1-IoU来作为loss(区间[0,1]找极小值),并以此实现模型的迭代优化。

$$
Loss=1-IoU=1-0.91=0.09
$$
IoU在语义分割中的应用
在语义分割任务里,我们同样可以计算图像中的预测区域与真实区域之间的IoU,并使用1-IoU作为Loss来对模型进行迭代优化。

$$
LOSS=1-IoU=1-0.89=0.11
$$
IoU的终极目标
通过上述几个例子,我们能够发现,计算IoU可以看做是在比较两个框或者两个图像的大小、区域、位置相不相同,进而可以把它想象成是在比较两个图像之间的几何图形相似度,那么我们不妨想一想,这个相似度都与哪些参数相关呢?我们能想到的有重叠比例、图形距离、形状相似度(矩形长宽比)等等。
下面我将为大家介绍IoU的计算原理,以及它是如何一步一步进行优化,朝着理想的方向迈进的。
IoU
IoU原理
IoU其实是Intersection over Union的简称,也叫‘交并比’。IoU在目标检测以及语义分割中,都有着至关重要的作用。
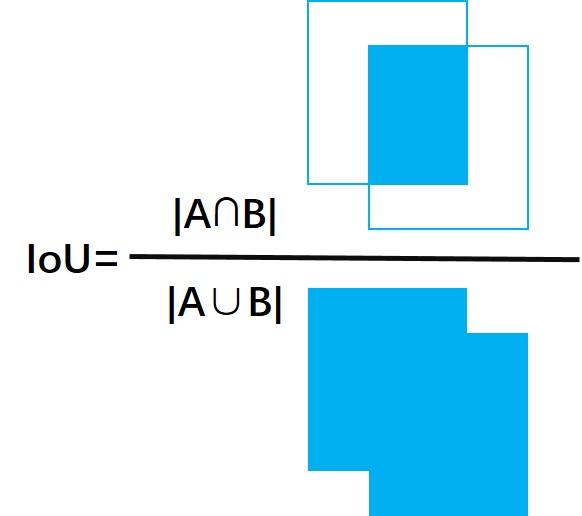
首先,我们先来了解一下IoU的定义:
$$
IoU=\frac{\left| A \cap B \right|}{\left|A \cup B\right|}
$$
直观来讲,我们可以把IoU的值定为为两个图形面积的交集和并集的比值,如下图所示:
通过IoU来评判两个图像的重合度具有以下几点优点:
- 具有尺度不变性;
- 满足非负性;
- 满足对称性;
但与此同时,IoU也有几点很明显的不足:
- 如果|A∩B|=0,也就是两个图像没有相交时,无法比较两个图像的距离远近;
- 无法体现两个图像到底是如何相交的。
我们可以认为,这个IoU初步满足了计算两个图像的几何图形相似度的要求,简单实现了图像重叠度的计算,但无法体现两个图形之间的距离以及图形长宽比的相似性。
IoU计算
下面我来带大家手动计算一下IoU:
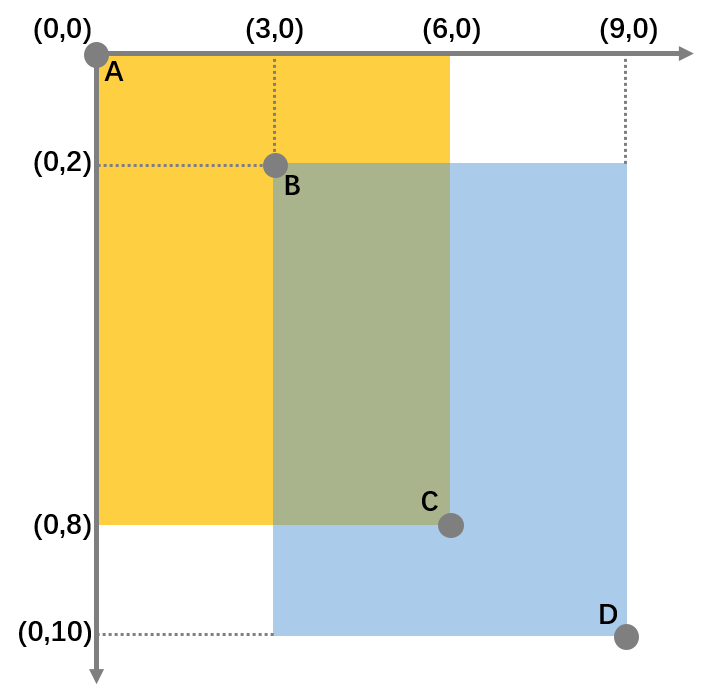
如上图所示,黄色矩形与蓝色矩形相交,他们的顶点A、B、C、D分别是:
A:(0,0) B:(3,2) C:(6,8) D:(9,10)
此时IoU的计算公式应为:
$$
IoU=\frac{\left| A \cap B \right|}{\left|A \cup B\right|}=\frac{绿色面积}{黄色+蓝色-绿色} \=\frac{(C_x - B_x) \times (C_y - B_y)}{(C_x - A_x) \times (C_y - A_y) + (D_x -B_x) \times (D_y - B_y) - (C_x - B_x) \times (Cy - B_y)}
$$
带入A、B、C、D四点的实际坐标后,可以得到:
$$
IoU=\frac{(6 - 3) \times (8 - 2)}{(6 - 0) \times(8 - 0) + (9 - 3) \times (10 - 2) - (6 - 3) \times (8 -2)} \
= \frac{3 \times 6}{6 \times 8 + 6 \times 8 - 3 \times 6} = \frac{18}{78} = 0.23
$$
所以,别看两个矩形相交了不少,但IoU的值其实只有0.23。
IoU实现
import numpy as np
# box:[上, 左, 下, 右]
box1 = [0,0,8,6]
box2 = [2,3,10,9]
def IoU(box1, box2):
# 计算中间矩形的宽高
in_h = min(box1[2], box2[2]) - max(box1[0], box2[0])
in_w = min(box1[3], box2[3]) - max(box1[1], box2[1])
# 计算交集、并集面积
inter = 0 if in_h < 0 or in_w < 0 else in_h * in_w
union = (box1[2] - box1[0]) * (box1[3] - box1[1]) + \
(box2[2] - box2[0]) * (box2[3] - box2[1]) - inter
# 计算IoU
iou = inter / union
return iou
IoU(box1, box2)
Out: 0.23076923076923078
GIoU
GIoU原理
GIoU(Generalized Intersection over Union)相较于IoU多了一个‘Generalized’,这也意味着它能在更广义的层面上计算IoU,并解决刚才我们说的‘两个图像没有相交时,无法比较两个图像的距离远近’的问题。
GIoU的计算公式为:
$$
GIoU=IoU- \frac{\left| C - (A \cup B) \right|}{C}
$$
其中C代表两个图像的最小包庇面积,也可以理解为这两个图像的最小外接矩形的面积。
由此我们可以看出:
- 原有IoU取值区间为[0,1],而GIoU的取值区间为[-1,1];在两个图像完全重叠时,IoU=GIoU=1,在两个图像距离无限远时,IoU=0而GIoU=-1。
- 与IoU只关注重叠区域不同,GIoU不仅关注重叠区域,还关注非重叠区域,这样能更好的的反映两个图像的重合度。
此时我们可以认为,GIoU完善了图像重叠度的计算功能,但仍无法对图形距离以及长宽比的相似性进行很好的表示。
注:GIoU论文地址https://arxiv.org/pdf/1902.09630.pdf
GIoU计算
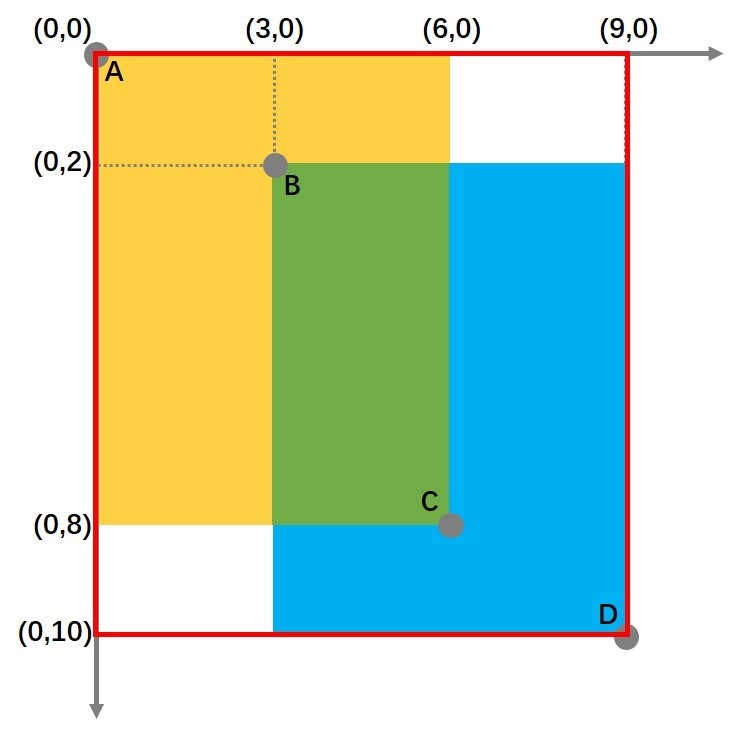
还是刚才那种情况,现在我们来计算GIoU:
$$
\begin{array}{c}
G I o U=I o U-\frac{|C-(A \cup B)|}{C}=0.23-\frac{\mid \text { 红框面积 }- \text { 黄绿蓝面积 } \mid}{\text { 红框面积 }}=0.23 \
-\frac{9 * 10-78}{9 * 10}=0.097
\end{array}
$$
GIoU实现
import numpy as np
# box:[上, 左, 下, 右]
box1 = [0,0,8,6]
box2 = [2,3,10,9]
def GIoU(box1, box2):
# 计算最小包庇面积
y1,x1,y2,x2 = box1
y3,x3,y4,x4 = box2
area_C = (max(x1,x2,x3,x4)-min(x1,x2,x3,x4)) * \
(max(y1,y2,y3,y4)-min(y1,y2,y3,y4))
# 计算IoU
in_h = min(box1[2], box2[2]) - max(box1[0], box2[0])
in_w = min(box1[3], box2[3]) - max(box1[1], box2[1])
inter = 0 if in_h < 0 or in_w < 0 else in_h * in_w
union = (box1[2] - box1[0]) * (box1[3] - box1[1]) + \
(box2[2] - box2[0]) * (box2[3] - box2[1]) - inter
iou = inter / union
# 计算空白部分占比
end_area = (area_C - union)/area_C
giou = iou - end_area
return giou
GIoU(box1, box2)
Out: 0.09743589743589745
DIoU
DIoU原理
GIoU虽然解决了IoU的一些问题,但是它并不能直接反映预测框与目标框之间的距离,DIoU(Distance-IoU)即可解决这个问题,它将两个框之间的重叠度、距离、尺度都考虑了进来,DIoU的计算公式如下:
$$
DIoU=IoU-\frac{\rho^2(b, b{gt})}{c2}
$$
其中b,bgt分别代表两个框的中心点,ρ代表两个中心点之间的欧氏距离,C代表最小包庇矩形的对角线,即如下图所示:
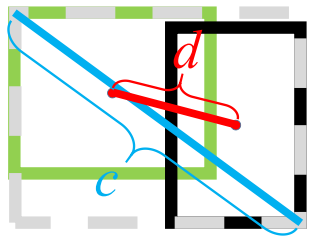
DIoU相较于其他两种计算方法的优点是:
- DIoU可直接最小化两个框之间的距离,所以作为损失函数的时候Loss收敛的更快;
- 在两个框完全上下排列或左右排列时,没有空白区域,此时GIoU几乎退化为了IoU,但是DIoU仍然有效。
此时我们可以认为,DIoU在完善图像重叠度的计算功能的基础上,实现了对图形距离的考量,但仍无法对图形长宽比的相似性进行很好的表示。
注:DIoU论文地址https://arxiv.org/pdf/1911.08287.pdf
DIoU计算
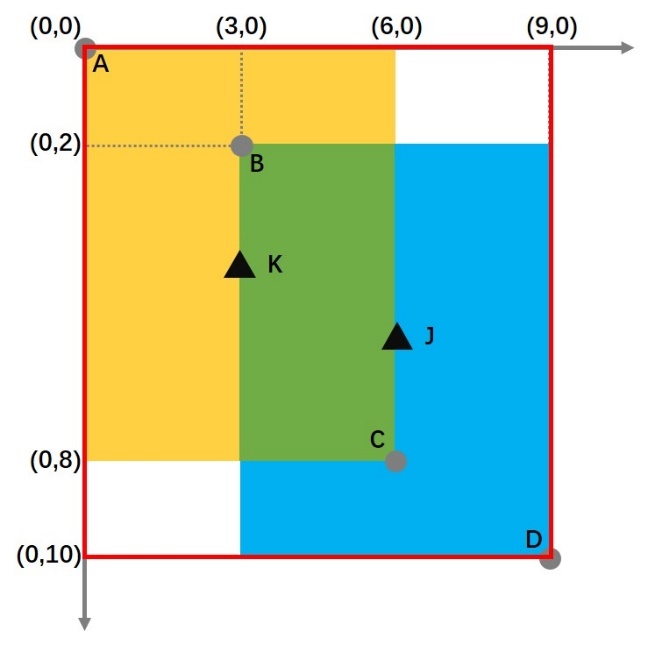
通过计算可得,黄框中心点K、蓝框中心点J的坐标分别为:
K:(3,4) J:(6,6)
那么此时的DIoU计算公式为:
$$
D I o U=I o U-\frac{\rho^{2}\left(b, b^{g t}\right)}{c{2}}=0.23-\frac{{\sqrt{3+2{2}}}{2}}{{\sqrt{9{2}+10{2}}}^{2}}=0.158
$$
DIoU实现
import numpy as np
import IoU
# box:[上, 左, 下, 右]
box1 = [0,0,8,6]
box2 = [2,3,10,9]
def DIoU(box1, box2):
# 计算对角线长度
y1,x1,y2,x2 = box1
y3,x3,y4,x4 = box2
C = np.sqrt((max(x1,x2,x3,x4)-min(x1,x2,x3,x4))**2 + \
(max(y1,y2,y3,y4)-min(y1,y2,y3,y4))**2)
# 计算中心点间距
point_1 = ((x2+x1)/2, (y2+y1)/2)
point_2 = ((x4+x3)/2, (y4+y3)/2)
D = np.sqrt((point_2[0]-point_1[0])**2 + \
(point_2[1]-point_1[1])**2)
# 计算IoU
iou = IoU(box1, box2)
# 计算空白部分占比
lens = D**2 / C**2
diou = iou - lens
return diou
DIoU(box1, box2)
Out: 0.1589460263493413
CIoU
CIoU原理
CIoU的全称为Complete IoU,它在DIoU的基础上,还能同时考虑两个矩形的长宽比,也就是形状的相似性,CIoU的计算公式为:
$$
CIoU=IoU-\frac{\rho2(b,b)}{c^2}-\alpha \nu
$$
其中$\alpha$是权重函数,而v用来度量长宽比的相似性:
$$
\nu=\frac{4}{\pi2}(arctan\frac{w{gt}}{h^{gt}} - arctan\frac{w}{h})^2
\
\alpha=\frac{\nu}{(1-IoU) + \nu}
$$
可以看出,CIoU就是在DIoU的基础上,增加了图像相似性的影响因子,因此可以更好的反映两个框之间的差异性。
我们还需要注意的一点是,在使用CIoU作为Loss的时候,v的梯度同样会参与反向传播的计算,其中:
$$
\begin{aligned}
& \frac{\partial v}{\partial w}=2 * \frac{4}{\pi^2} *\left(\arctan \frac{w^{g t}}{h^{g t}}-\arctan \frac{w}{h}\right) *(-1) * \frac{1}{1+\left(\frac{w}{h}\right)^2} * \frac{1}{h} \
&=\frac{8}{\pi^2} *\left(\arctan \frac{w^{g t}}{h^{g t}}-\arctan \frac{w}{h}\right) *(-1) * \frac{h2}{w2+h^2} * \frac{1}{h} \
&=-\frac{8}{\pi^2} *\left(\arctan \frac{w^{g t}}{h^{g t}}-\arctan \frac{w}{h}\right) * \frac{h}{w2+h2} \
& \frac{\partial v}{\partial h}=2 * \frac{4}{\pi^2} *\left(\arctan \frac{w^{g t}}{h^{g t}}-\arctan \frac{w}{h}\right) *(-1) * \frac{1}{1+\left(\frac{w}{h}\right)^2} * w *(-1) * h^{-2} \
&= \frac{8}{\pi^2} *\left(\arctan \frac{w^{g t}}{h^{g t}}-\arctan \frac{w}{h}\right) * \frac{h2}{w2+h^2} * w * h^{-2} \
&= \frac{8}{\pi^2} *\left(\arctan \frac{w^{g t}}{h^{g t}}-\arctan \frac{w}{h}\right) * \frac{w}{w2+h2}
\end{aligned}
$$
如果矩形的w和h均小于1,w2+h2的值则会很小,这样很容易出现梯度爆炸的现象,所以在计算v的梯度时,直接把$\frac{1}{w2+h2}$当做1来计算。
至此,我们终于完成了最初所定的目标,实现了对两个图像之间的重叠比例、图形距离、形状相似度(矩形长宽比)的综合度量。
注:CIoU论文与DIoU是同一篇。
CIoU计算
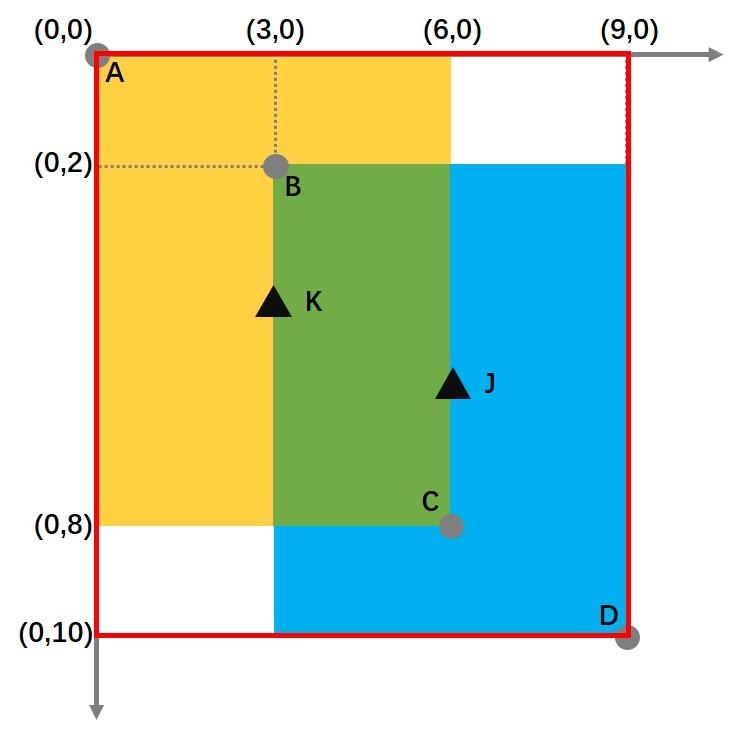
通过计算可得,黄框中心点K、蓝框中心点J的坐标分别为:
K:(3,4) J:(6,6)
此时CIoU的计算公式为:
$$
CIoU=IoU-\frac{\rho2(b,b)}{c^2}-\alpha \nu \
=0.1589 - \frac{\nu}{(1 - IoU) + \nu} \times \frac{4}{\pi2}(arctan\frac{6{gt}}{8{gt}}-arctan\frac{6}{8})2 \
= 0.1589
$$
由于最开始设定的两个矩形的形状相同,计算所得的形状惩罚项为0,因此此时CIoU=DIoU。由此可见,两个形状差别越大,CIoU相较于DIoU则越小。
CIoU实现
import numpy as np
import math
import IoU
import DIoU
# box:[上, 左, 下, 右]
box1 = [0,0,8,6]
box2 = [2,3,10,9]
def CIoU(box1, box2):
y1,x1,y2,x2 = box1
y3,x3,y4,x4 = box2
iou = IoU(box1, box2)
diou = DIoU(box1, box2)
v = 4 / math.pi**2 * (math.atan((x2-x1)/(y2-y1)) - \
math.atan((x4-x3)/(y4-y3)))**2 + 1e-5
alpha = v / ((1-iou) + v)
ciou = diou - alpha * v
return ciou
CIoU(box1, box2)
Out: 0.1589460263493413
旋转变换
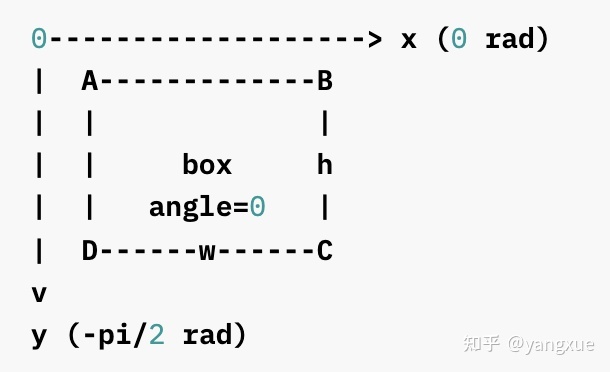
实际上,旋转框既可以由水平框绕在中心点顺时针旋转得到,也可以由水平框绕在中心点逆时针旋转得到。 旋转方向和坐标系的选择密切相关。图像空间采用右手坐标系 $(y,x)$,其中$y$轴 是上 -> 下,$x$轴是左 -> 右。 此时存在 2 种相反的旋转方向。
顺时针
- CW示意图
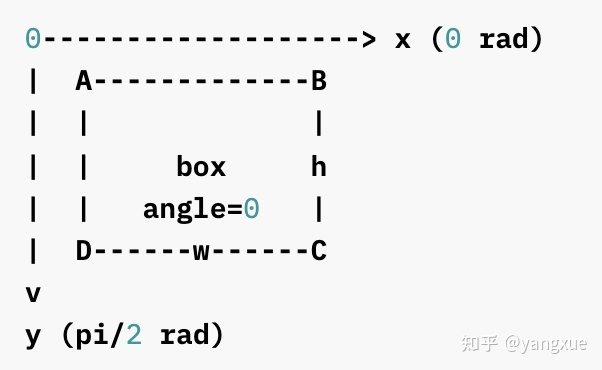
- CW的旋转矩阵
$$
\left(\begin{array}{cc}
\cos \alpha & -\sin \alpha \
\sin \alpha & \cos \alpha
\end{array}\right)
$$
- CW的旋转变换
$$
\begin{array}{r}
P_A=\left(\begin{array}{l}
x_A \
y_A
\end{array}\right)=\left(\begin{array}{l}
x_{\text {center }} \
y_{\text {center }}
\end{array}\right)+\left(\begin{array}{cc}
\cos \alpha & -\sin \alpha \
\sin \alpha & \cos \alpha
\end{array}\right)\left(\begin{array}{l}
-0.5 w \
-0.5 h
\end{array}\right) \
=\left(\begin{array}{l}
x_{\text {center }}-0.5 w & \cos \alpha+0.5 h \sin \alpha \
y_{\text {center }}-0.5 w & \sin \alpha-0.5 \cos \alpha
\end{array}\right)
\end{array}
$$
逆时针
- CCW的示意图
- CCW的旋转矩阵
$$
\left(\begin{array}{cc}
\cos \alpha & \sin \alpha \
-\sin \alpha & \cos \alpha
\end{array}\right)
$$
- CCW的旋转变换
$$
\begin{array}{r}
P_A=\left(\begin{array}{l}
x_A \
y_A
\end{array}\right)=\left(\begin{array}{l}
x_{\text {center }} \
y_{\text {center }}
\end{array}\right)+\left(\begin{array}{cc}
\cos \alpha & \sin \alpha \
-\sin \alpha & \cos \alpha
\end{array}\right)\left(\begin{array}{l}
-0.5 w \
-0.5 h
\end{array}\right) \
=\left(\begin{array}{l}
x_{\text {center }}-0.5 w &\cos \alpha-0.5 h \sin \alpha \
y_{\text {center }}+0.5 w & \sin \alpha-0.5h \cos \alpha
\end{array}\right)
\end{array}
$$
注:在 MMCV 中可以设置旋转方向的算子有:box_iou_rotated (默认为 CW),nms_rotated (默认为 CW),RoIAlignRotated (默认为 CCW),RiRoIAlignRotated (默认为 CCW)。
旋转框的定义方式
进入正题,我们以下一 CW 为例,即逆时针负角度,顺时针正角度。我收集了开源社区里比较常用的几种旋转框定义。根据角度定义方式,主要还是 OpenCV 定义法和长边定义法 ,但是里面还有一些细分,一共四种,介绍如下:
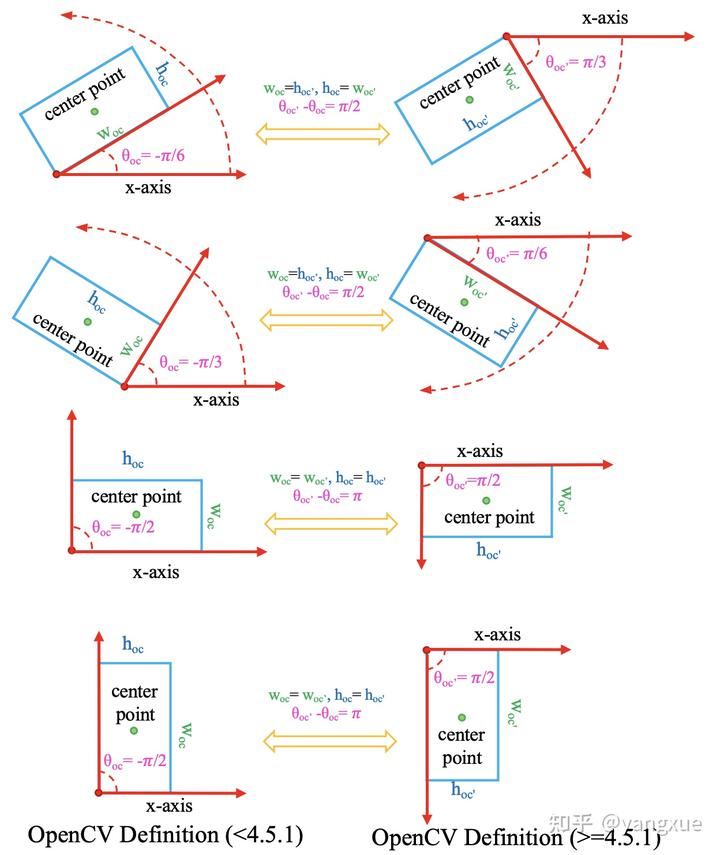
旧版本OpenCV定义法$D_{oc}$
进入正题,我们以下一 CW 为例,即逆时针负角度,顺时针正角度。我收集了开源社区里比较常用的几种旋转框定义。根据角度定义方式,主要还是 OpenCV 定义法和长边定义法 ,但是里面还有一些细分,一共四种,介绍如下:OpenCV 在版本 4.5.1 之前,表示形式为$(x_{oc},y_{oc},w_{oc},\theta)$,示意图如下:

新版本OpenCV定义法 $D_{oc^{'}}$
不知道为什么,OpenCV 在版本 4.5.1 之后修改了角度定义范围,变成了由$w_{oc}$与$x$轴所成的正的锐角或者直角。表示形式为 $(x_{oc'},y_{oc'},w_{oc'},h_{oc'},\theta_{oc'}), \theta_{oc'} \in (0,\pi/2]$,示意图如下:

需要注意的是除了角度变成正的,定义域的闭集方向从原来的左边变成了右边。‘
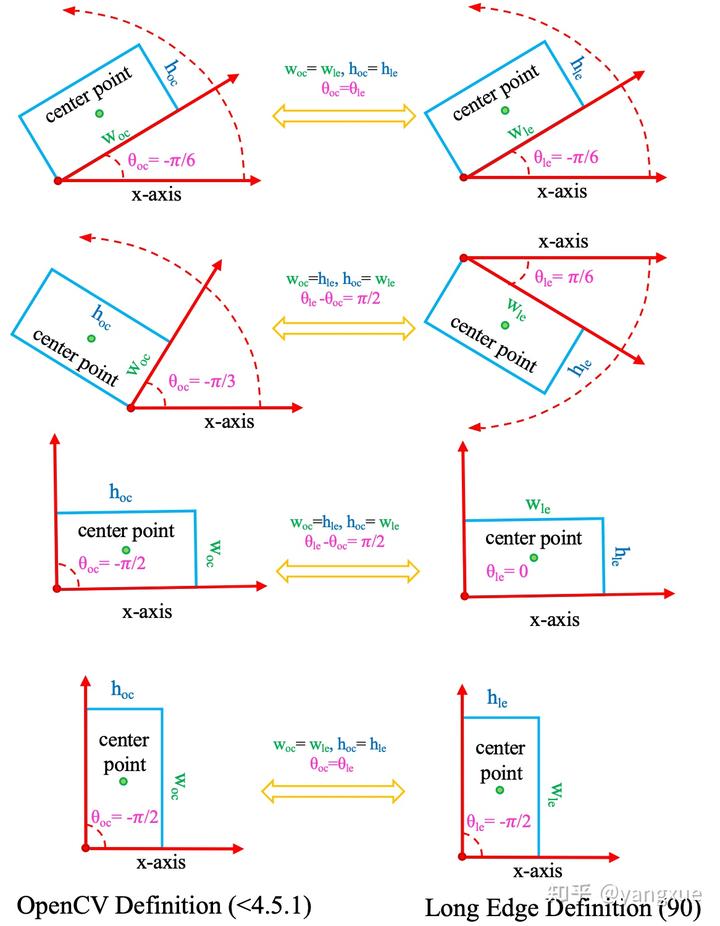
长边定义法$D_{le}$
顾名思义,该类定义法的角度由长边和$x$轴所决定,但是目前开源社区存在多种取值范围。第一种表示形式为:$(x_{le},y_{le},w_{le},h_{le},\theta_{le}), \theta_{le} \in [-\pi/2,\pi/2)$,示意图如下:

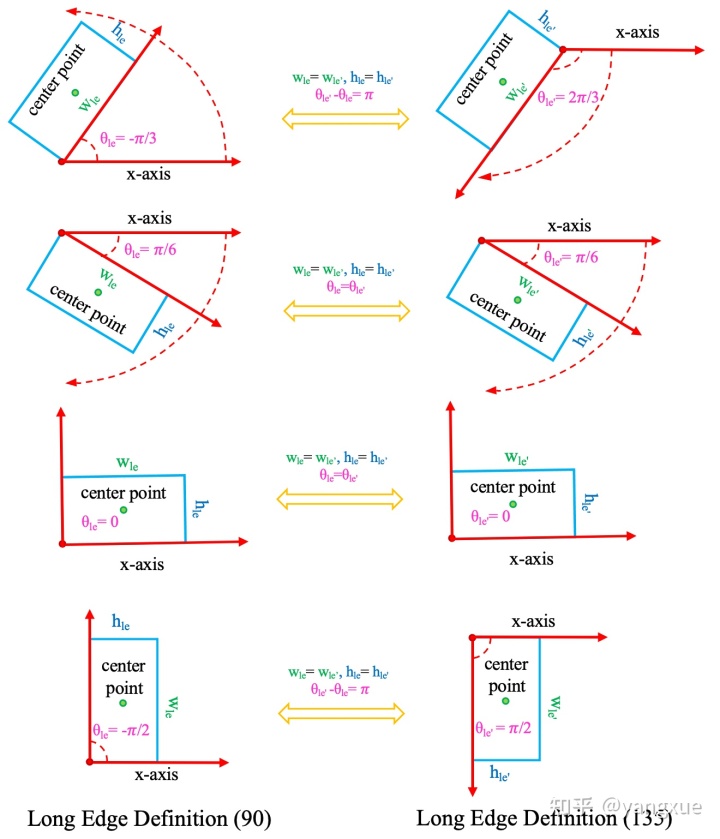
长边定义法$D_{le^{'}}$
可能是考虑到处于$\pm\pi/2$的目标太多,作为边界位置不太合适,有些代码(最早可能是RRPN)采用的表示形式是$(x_{le'},y_{le'},w_{le'},h_{le'},\theta_{le'}), \theta_{le'} \in [-\pi/4,3\pi/4)$
,示意图如下:

表示边的转换关系
尽管定义略有区别,不同表示法之间其实是可以相互转换的。
$D_{oc} $和$ D_{oc'} $之间的相互转换
$$
D_{oc}(w_{oc},h_{oc},\theta_{oc}) = \begin{cases}
D_{oc'}(h_{oc'},w_{oc'},\theta_{oc'}-\frac{\pi}{2}) & \theta \ne \frac{\pi}{2}
\ D{oc'}(w_{oc'},h_{oc'},\theta_{oc'}-\pi) & otherwise
\end{cases}
\
D_{oc'}(w_{oc'},h_{oc'},\theta_{oc'}) = \begin{cases}
D_{oc}(h_{oc},w_{oc},\theta_{oc'}+\frac{\pi}{2}) & \theta \ne -\frac{\pi}{2}
\ D{oc'}(w_{oc'},h_{oc'},\theta_{oc'}+\pi) & otherwise
\end{cases}
$$
这里要注意的是两者的闭集位置进行了调换,所以在边界角度处的转换和非边界角度处的转换越有所不同。
示意图如下:
$D_{oc}$ 和 $D_{le}$ 之间的相互转换
$$
D_{le}(w_{le},h_{le},\theta_{le}) = \begin{cases}
D_{oc}(h_{oc},w_{oc},\theta_{oc}) & w_{oc} \geqslant h_{oc}
\ D_{oc}(h_{oc}, w_{oc},\theta_{oc}+\frac{\pi}{2}) & otherwise
\end{cases}
\
D_{oc}(w_{oc},h_{oc},\theta_{oc}) = \begin{cases}
D_{le}(w_{le},h_{le},\theta_{le}) & \theta_{le} \in [-\frac{\pi}{2}, 0)
\ D_{le}(h_{le},w_{le},\theta_{le}- \frac{\pi}{2}) & otherwise
\end{cases}
$$
示意图如下:
$D_{le}$ 和 $D_{le'}$ 之间的相互转换
$$
D_{le}(w_{le},h_{le},\theta_{le}) = \begin{cases}
D_{le'}(w_{le'},h_{le'}\theta_{le'}-\pi) & \theta \in [\frac{\pi}{2}, \frac{3\pi}{4})
\ D_{le'}(w_{le'},h_{le'},\theta_{le'}-\pi) & otherwise
\end{cases}
\
D_{le'}(w_{le'},h_{le'},\theta_{le'}) = \begin{cases}
D_{le}(w_{le},h_{le},\theta_{le'}+\pi) & \theta \in [\frac{\pi}{2}, -\frac{\pi}{4})
\ D_{le}(w_{le},h_{le},\theta_{le}) & otherwise
\end{cases}
$$
示意图如下:
总结
上面只列了三种转换关系,未列的可以通过这三个进行多步转换或者有兴趣的可以自己总结一下转换关系。不管是哪个表示法的转换,我们可以发现当需要进行变换操作的时候一般是这两种:
- 边进行交换,同时角度加减 $\frac{\pi}{2}$
- 边不交换,角度加减$\pi$
这就很有意思,熟悉GWD论文的朋友可能也回想起不同定义法下的边界问题好像也是这两个关系。我们再来回顾一下为什么高斯建模可以统一不同的定义法和边界问题:
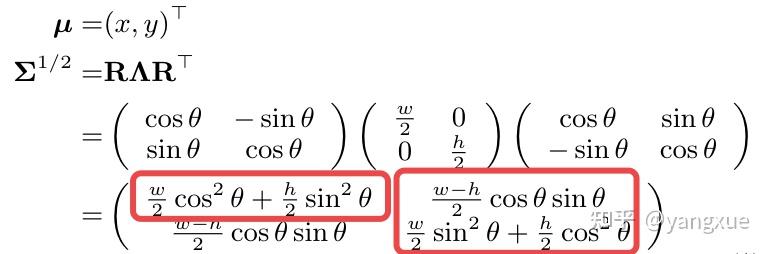
红框中是协方差 $\varSigma $中三种不同的元素,这三个元素有一个共同的特点就是经过上面两种变换前后还是相同的,所以高斯建模的优势就在于此。之所以需要三个,那是因为这里有三个参数。抛开高斯分布这个框架,我们是不是可以自己先构造三个这样性质的不同组合,通过直接回归这些参数组合而不是采用GWD和KLD也能成功。
如果再思考得深入一点,我们发现对于不同的表示方式,它们计算IoU的代码其实都是通用的。这是为什么呢?因为IoU的计算过程是和第2节讲的旋转变换有关。在框的旋转过程中我们是不需要考虑旋转角度是怎么定义的,也就不需要担心变换之后是否超过定义范围,逆时针旋转5度对应的就是原始角度减去5度。检测器的参数回归也是这么做的,即使在解码中出现了我们所说的边界问题,其本质还是一个正常的旋转变换。边界问题是针对某一个确定的表示法来说的,因此如果使用IoU损失这种不用考虑框表示方式的损失函数来优化检测器就能完全不用在意边界问题。相同的,高斯建模中的协方差$\varSigma $也存在旋转变换,基于它的回归损失同样不需要考虑定义方式和边界问题。我暂将这种回归损失称为表示方式无关和边界问题免疫。
因此在设计旋转检测器过程中,表示法的作用应该局限于给初始候选框(如anchor)一个初始的表示形式,不能参与回归损失的计算,否则不同表示法和边界问题都会对检测器的优化带来影响,即回归损失应该是表示方式无关和边界问题免疫的。
各种表示方法的边界问题
这两种定义法各有各的缺点,比如$D_{oc}$在边界处有角度周期性(PoA)和边的交换性(EoE)两种问题,而$D_{le}$有角度周期性(PoA)和类正方形检测问题(SLP)。这些问题我都总结在下图中了:
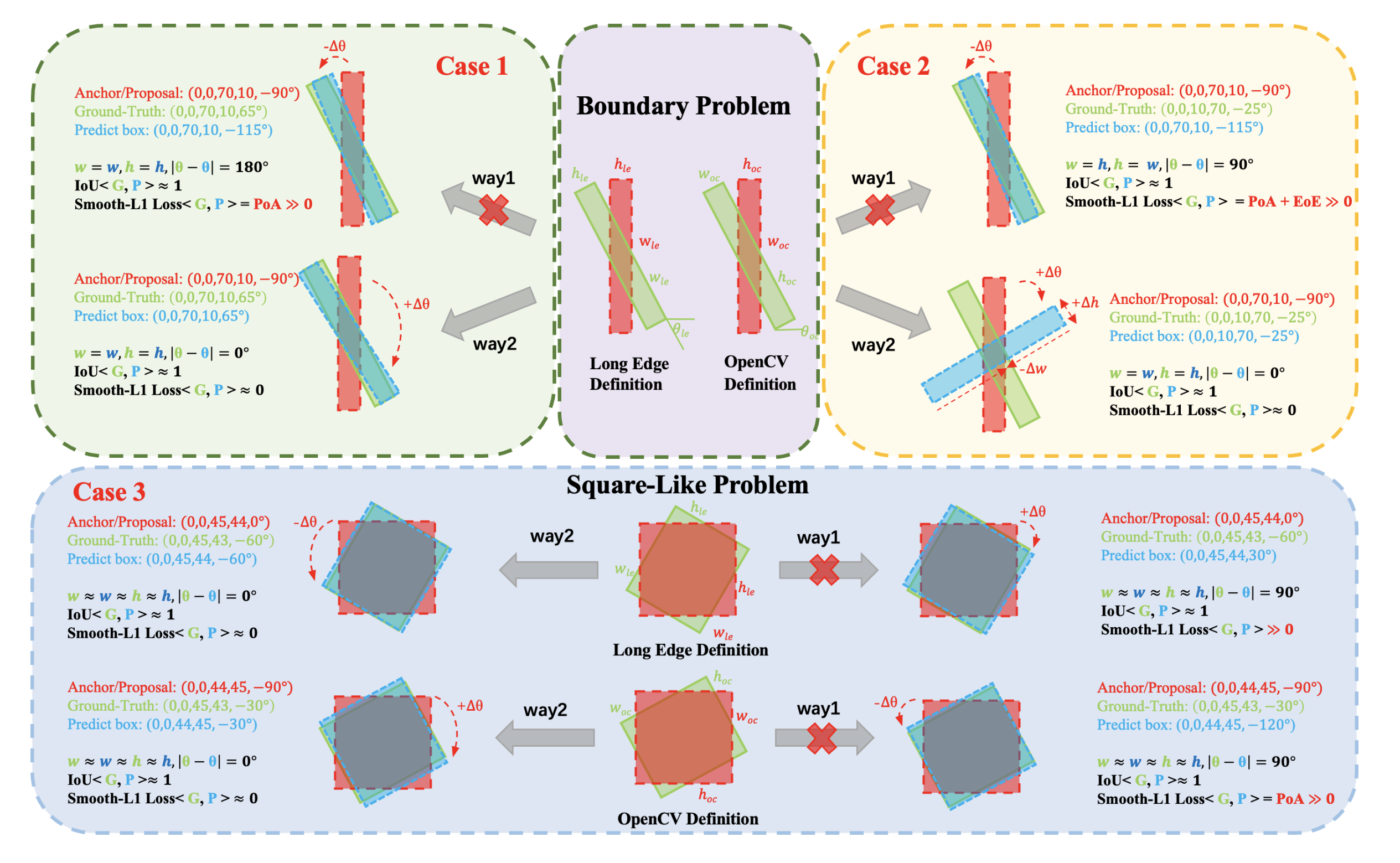
我们的目的是想让模型可以按照 way1 走通。这里有些小伙伴可能会有疑惑,way1 走不通不是有 way2 吗,反正模型能有回归到正确位置的方式就行了。我们来看下面这张图,在非边界位置的时候模型是按下图底部方式回归的,而在边界位置就不会这么回归了,这说明存在边界位置和非边界位置的回归方式的不一致。由于非边界位置出现的概率非常大,因此模型在边界处时 “经验” 告诉它应该通过 way1 训练,但是计算出来的 Loss 又告诉它要用 way2,这使得模型在边界处训练的非常“左右摇摆不定”。加之 way2 也比较复杂,因此边界处的预测往往比较不准,尤其是使用$D_{oc}$定义法。
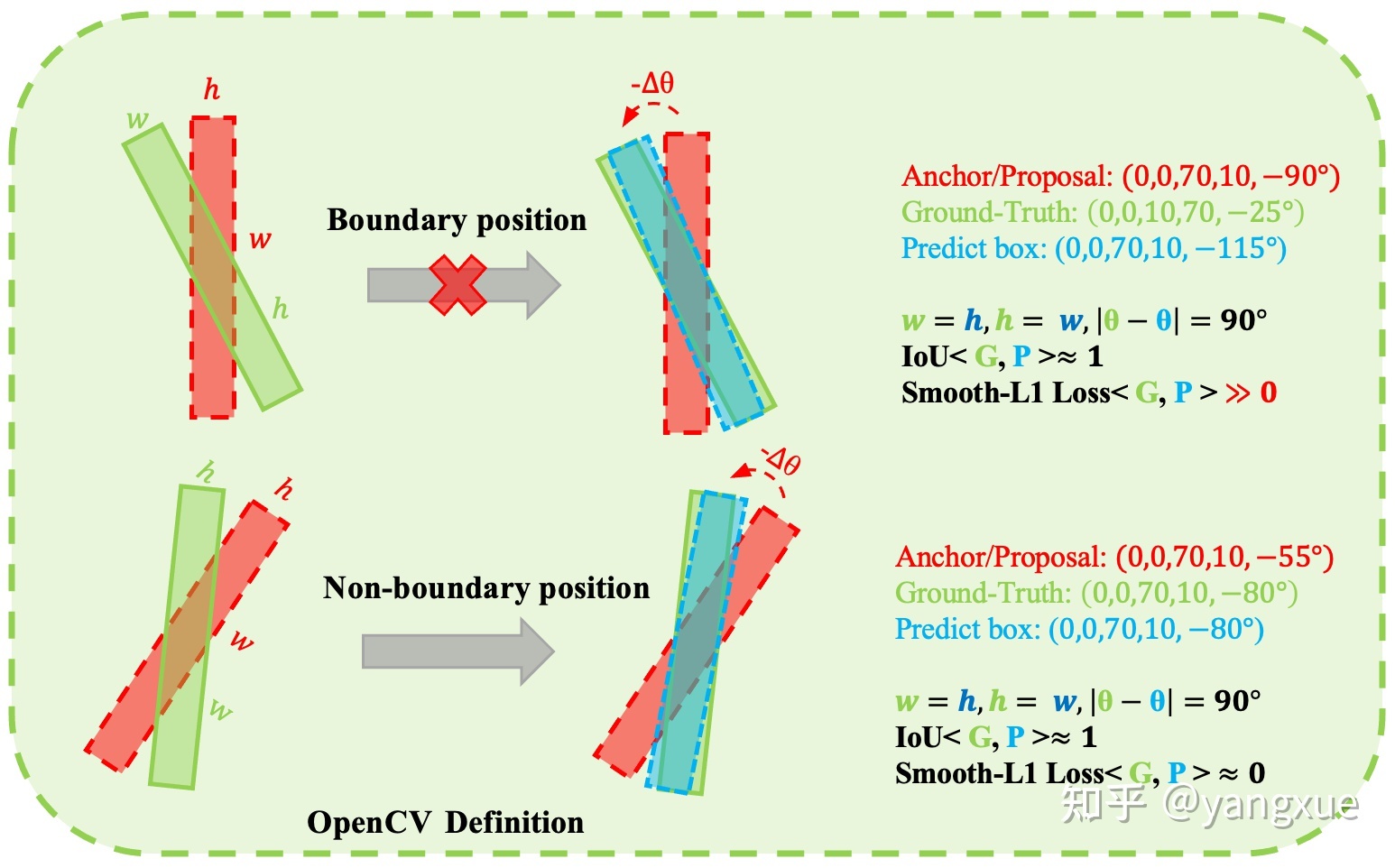
可以看到,损失与IoU指标不一致,此时我们需要使用一种新的损失来度量预测边界框与真实边界框之间的距离。
PIoU
存在问题:使用方向边界框(OBB)进行目标检测可以通过减少与背景区域的重叠来更好地定位旋转对象。现有的 OBB 方法大多是通过引入由距离损失优化的附加角度尺寸而在水平边界框检测器上构建的。但是,由于距离损失仅使 OBB 的角度误差最小,并且与 IoU 的相关性较松散,因此它对具有高纵横比的对象不敏感。

因此,本文提出了一种新的损失,即 Pixels-IoU(PIoU)损失,以利用角度和 IoU 进行精确的 OBB 回归。PIoU 损失是从 IoU 度量导出的,具有像素级形式,这很简单,适用于水平和定向边界框。
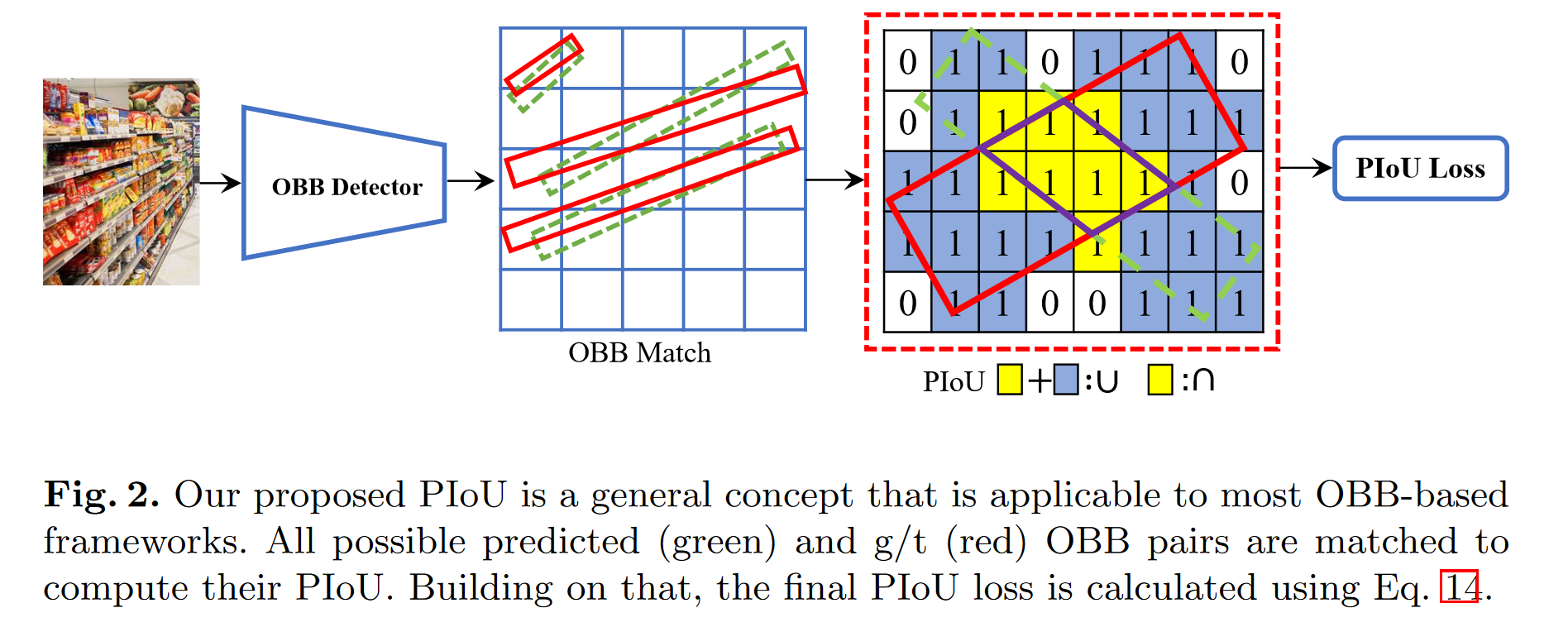
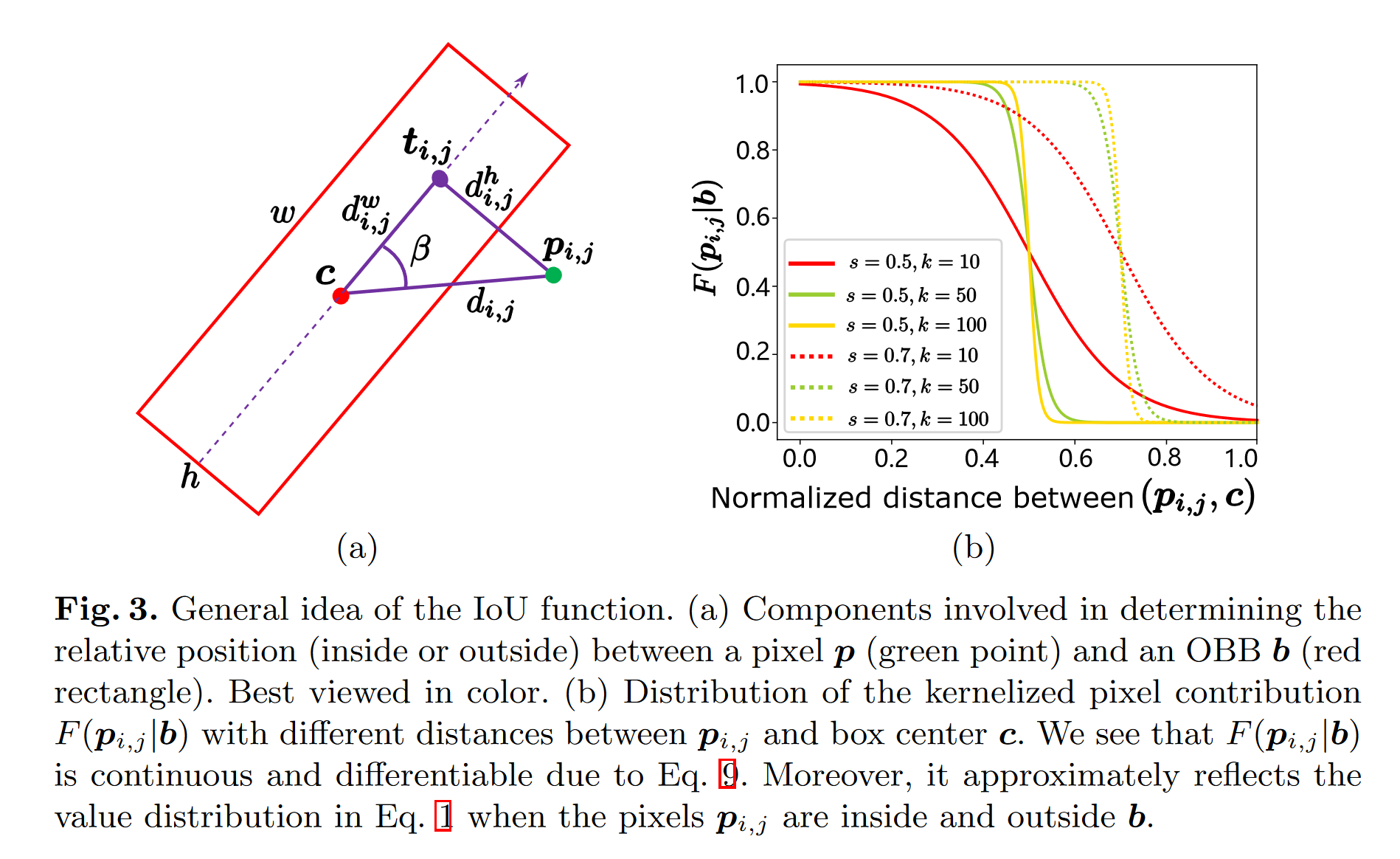
在论文中,详细说明了计算的步骤,这里还是列出公式:
$$
L_{\text {pIoU }}=\frac{-\sum_{\left(\boldsymbol{b}, \boldsymbol{b}^{\prime}\right) \in M} \ln P \operatorname{IoU}\left(\boldsymbol{b}, \boldsymbol{b}^{\prime}\right)}{|M|}
$$
这个详细的公式可以看论文中的内容。
GWD
为了解决损失(loss)和评估(metric)的不一致问题,以及解决由于角度周期性等引起的回归边界问题。
PIoU Loss 的想法比较简单,就是统计两个任意旋转框之间的共有像素个数来近似 IoU。文章有一个很大的问题就是 baseline 太低了,文章最终报的性能才 60 出头,但是在这个领域做 DOTA 数据集的 baseline 不给 65 以上都不好意思了,所以有理由质疑这个方法是否有效了。
这篇文章中 “将任意旋转矩形近似成一个二维的高斯分布,通过计算分布之间的 Wasserstein 距离解决 RIoU 不可导的问题”
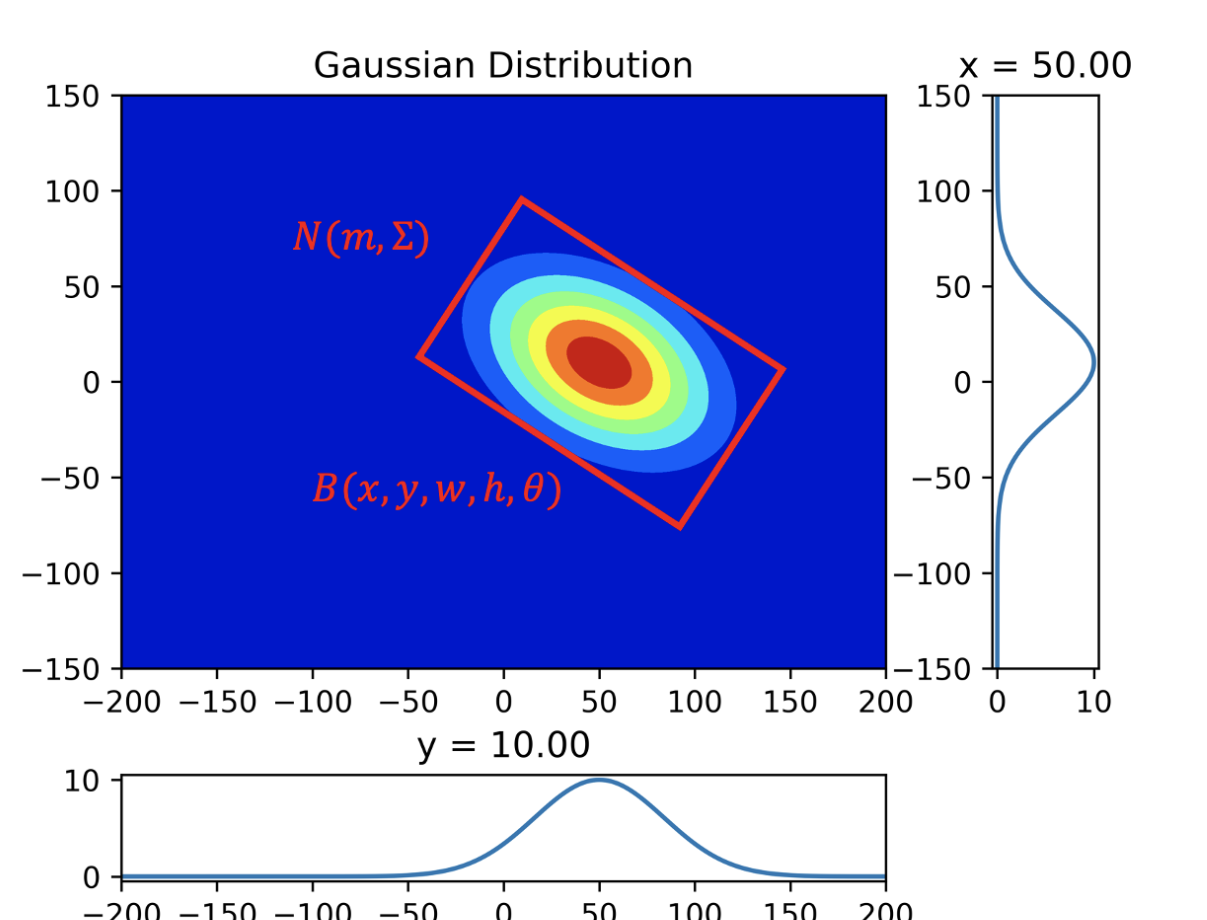
任意旋转矩形框和二维高斯分布的转换关系:
$$
\begin{aligned}
\boldsymbol{\Sigma}^{1 / 2} & =\mathbf{R S R}^{\top} \
& =\left(\begin{array}{cc}
\cos \theta & -\sin \theta \
\sin \theta & \cos \theta
\end{array}\right)\left(\begin{array}{cc}
\frac{w}{2} & 0 \
0 & \frac{h}{2}
\end{array}\right)\left(\begin{array}{cc}
\cos \theta & \sin \theta \
-\sin \theta & \cos \theta
\end{array}\right) \
& =\left(\begin{array}{cc}
\frac{w}{2} \cos ^{2} \theta+\frac{h}{2} \sin ^{2} \theta & \frac{w-h}{2} \cos \theta \sin \theta \
\frac{w-h}{2} \cos \theta \sin \theta & \frac{w}{2} \sin ^{2} \theta+\frac{h}{2} \cos ^{2} \theta
\end{array}\right) \
\mathbf{m} & =(x, y)^{\top}
\end{aligned}
$$
两个高斯分布之间的 Wasserstein 距离公式:
$$
d{2}=\left|\mathbf{m}_{1}-\mathbf{m}_{2}\right|_{2}+\operatorname{Tr}\left(\boldsymbol{\Sigma}{1}+\boldsymbol{\Sigma}-2\left(\boldsymbol{\Sigma}{1}^{1 / 2} \boldsymbol{\Sigma} \boldsymbol{\Sigma}_{1}^{1 / 2}\right)^{1 / 2}\right)
$$
在之前的工作中,我们提出了各种针对不同问题的方法,但是在一次意外测试的时候我们发现了 GWD 几个重要的性质。我们模拟了不同边界框定义下 PoA、EoE、SLP 的情况,发现这些情况下 GWD 依然可以计算出准确的 IoU。
这意味着 GWD 可能对这些问题是免疫的。因此就有了以下三个性质的提炼:
$$
Property 1: \boldsymbol{\Sigma}^{1 / 2}(w, h, \theta)=\boldsymbol{\Sigma}^{1 / 2}\left(h, w, \theta-\frac{\pi}{2}\right);\
Property 2: \boldsymbol{\Sigma}^{1 / 2}(w, h, \theta)=\boldsymbol{\Sigma}^{1 / 2}(w, h, \theta-\pi);\
Property 3: \boldsymbol{\Sigma}^{1 / 2}(w, h, \theta) \approx \boldsymbol{\Sigma}^{1 / 2}\left(w, h, \theta-\frac{\pi}{2}\right),& if w \approx h
$$
这三个性质分别对应解决 $D_{oc}$的 PoA 和 EoE、$D_{le}$的 PoA、$D_{le}$的 SLP 问题。其实我们发现根据性质 1,$D_{oc}$和$D_{le}$在 GWD 下是等价的。这下好了,我们就不用考虑选用什么边界框的定义方式、以及乱七八糟问题的困扰,GWD 可以说是全免疫了。回过头来再分析,这些好处都归功于旋转框转换成高斯分布这一步骤,正式因为高斯分布的$\Sigma$才有了这些性质。至于后续使用 Wasserstein 距离来作为回归损失都是水到渠成的操作了。
KFIoU
接下来引出本次的重头戏:KFIoU损失。
在通用检测中,IoU 损失一直是备受欢迎的,它可以有效对齐当前评估(IoU 主导)和回归损失($L_{n}$损失)的不一致性。由于旋转 IoU(SkewIoU)损失在当前开源框架中并没有被支持,且用现有的算子实现比较困难,因此 SkewIoU 损失在该领域中被没有被广泛使用。
也有一些工作研究如何近似的 SkewIoU 损失,比如 PIoU、projection IoU、GWD、KLD 等。值得注意的是,GWD引入了高斯建模,使得检测器能免疫边界不连续等问题。但是它们本质上不是 SkewIoU 损失,这是因为它们的计算并不是按照 SkewIoU 的计算过程得到的,而是使用了高斯分布距离度量,所以在最终损失函数的设计上引入了非线性变换以及超参数。
此次工作的目的是设计一个简单且更高效的 SkewIoU 近似损失,目标如下:
- 可以通过当前深度学习框架现有的算子轻松实现
- 不引入额外超参数,不需要额外调参
- 效果比朴素的 SkewIoU、GWD、KLD 等损失更好
此次工作的目的是设计一个简单且更高效的 SkewIoU 近似损失,目标如下:可以通过当前深度学习框架现有的算子轻松实现 不引入额外超参数,不需要额外调参效果比朴素的 SkewIoU、GWD、KLD 等损失更好由于设计的是损失函数,因此我们并不需要严格实现精确的 SkewIoU 计算。这是显然的结论,如$y=\left| x \right|$和$y=\left| x \right|+b$作为损失函数来说是等效的。因此我们只需要实现一个和朴素 SkewIoU 损失具有高度一致性的损失函数就行了,也就是文中提到的保证 trend-level consistency 而不需要 value-level consistency,这一个发现其实大大简化了设计的难度。理想的 trend-level consistency是设计的损失函数和理想的损失函数之间的差值是一个常数。为有效衡量损失函数之间的 trend-level consistency,我们设计了一个损失函数的误差方差(error variance, EVar),公式如下:
$$
EMean = \frac{1}{N} \sum_{i=1}^{N}{(SkewIoU_{plain}-SkewIoU_{apporox})}\
Evar=\frac{1}{N} \sum_{i=1}^{N}{(SkewIoU_{approx} - EMean)}^2
$$
我们可以比较一下 L1、GWD、KLD 与 plain SkewIoU 损失之间的误差方差:
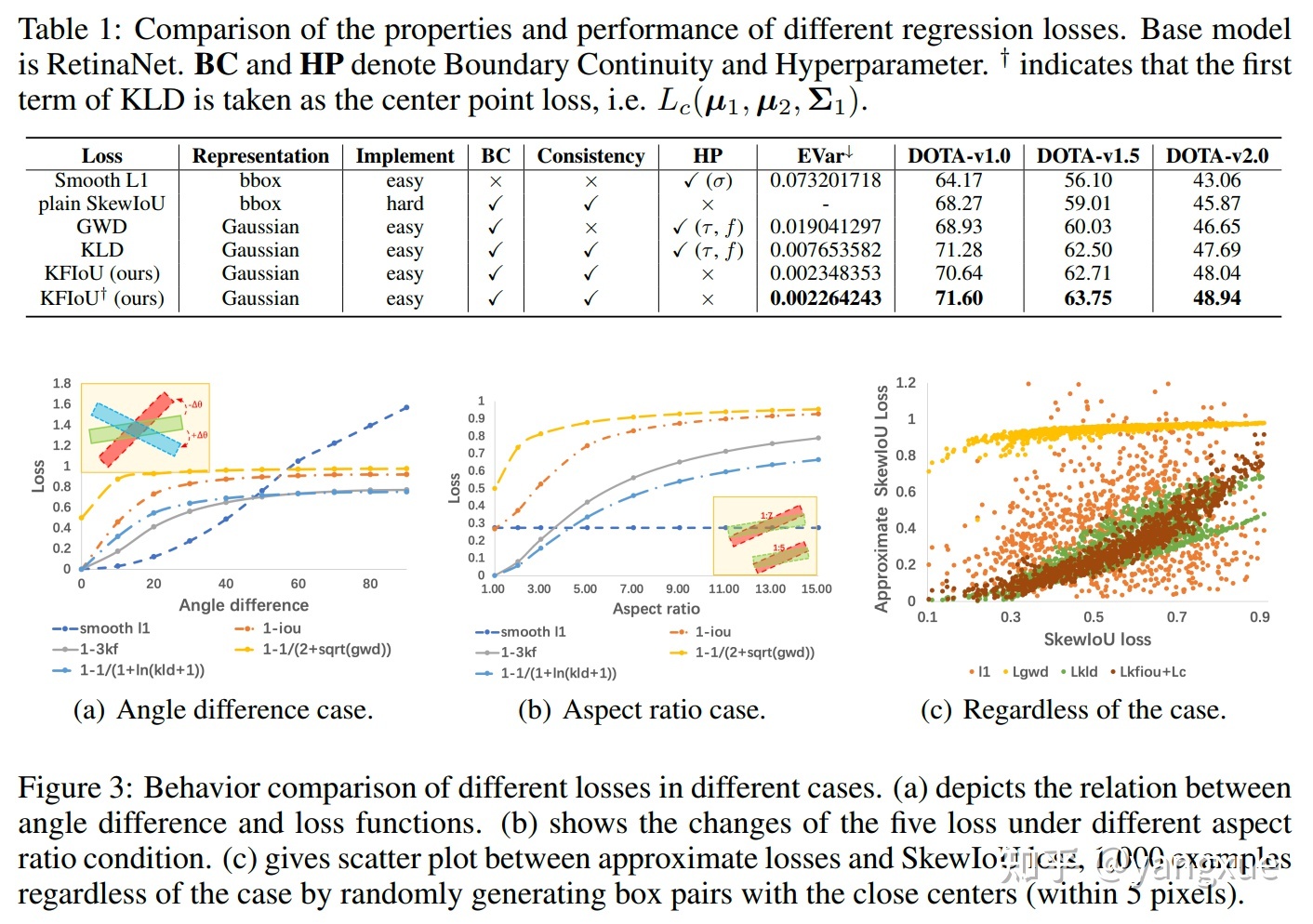
如果仅关注误差方差和性能的话,我们可以发现误差方差越小,性能趋向于越好。这一个发现也很好佐证了我们上面的发现:保证 trend-level consistency 而不需要 value-level consistency。
如果仅关注误差方差和性能的话,我们可以发现误差方差越小,性能趋向于越好。这一个发现也很好佐证了我们上面的发现:保证 trend-level consistency 而不需要 value-level consistency。吸取了 GWD 和 KLD 在近似 SkewIoU 路上的经验教训,此次我们依然采用高斯建模的方式,但不再通过分布距离度量来构建新的损失函数而是想通过高斯分布模拟 SkewIoU 的计算过程,具体步骤如下图:
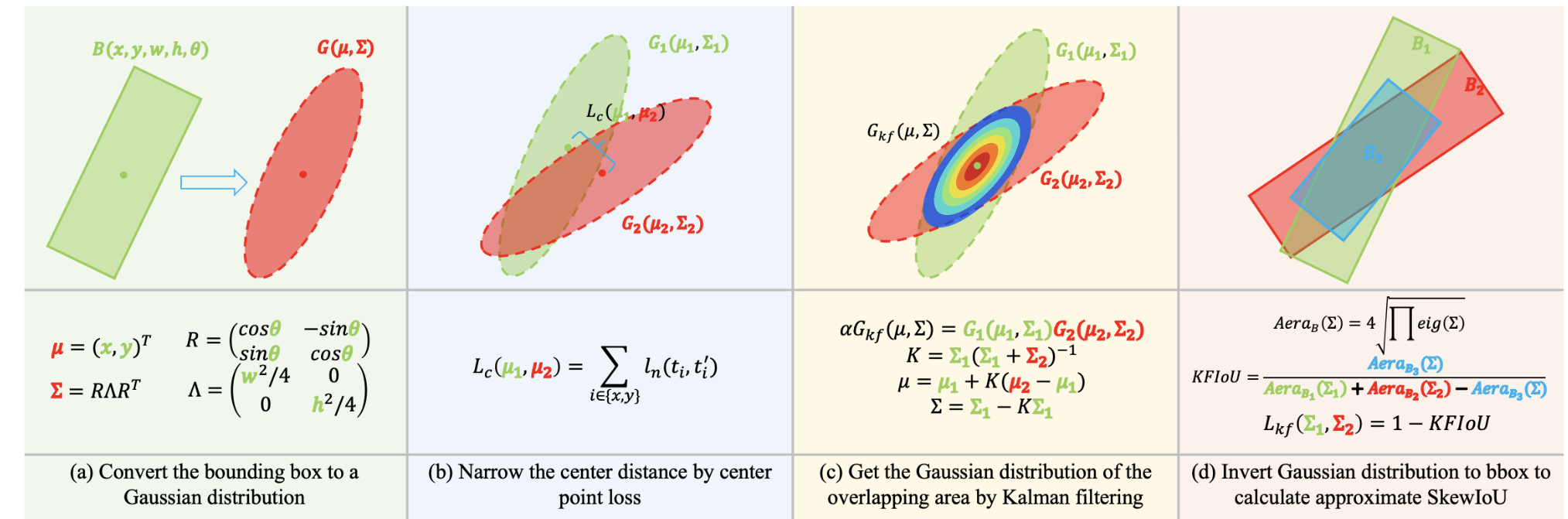
- 将两个旋转矩形框转换成高斯分布;
- 引入中心点损失拉近使得两个分布同中心(需要这个步骤的原因会在后面分析);
- 通过两个高斯相乘的到相交区域的高斯分布;
- 将三个高斯分布反转换成旋转矩形,计算近似的 SkewIoU
很显然整个过程是按照 SkewIoU(交 / 并)的计算过程进行的,但是计算出来的结果肯定不是精确的 SkewIoU,上面分析过,精确的 SkewIoU 这个并不重要。这里需要解释一下为什么最后取名 KFIoU(Kalman filtering IoU),主要是因为卡尔曼滤波中同样应用到了高斯分布相乘,我也是通过这个想到通过相乘后的高斯分布来计算相交区域的面积,从而达到近似 SkewIoU 的目的。
因为核心是高斯相乘,所以取名 Kalman filtering 有点草率,但我确实是从 Kalman filtering 中受到的启发,就当致敬一下。当然也不是不可以强行解释一波:我们将预测框、真实框和重叠区域分别建模为预测值、观察值和不确定性。由于卡尔曼滤波中的预测值、观察值都不是确定的,所以需要迭代的过程,而旋转检测中的预测框、真实框是确定的,所以就不需要迭代过程了。当然,卡尔曼滤波我自己是一知半解的,并没有深入研究,上面的解释在行家眼里可能就是瞎扯,大家就随意看看就行了。回到正题,我们来更详细地解释上述过程。首先,我们可以通过高斯分布计算出其对应旋转矩形框的面积,其实就是协方差特征值累乘(协方差特征值对应旋转矩形的两条边),公式如下:
$$
\upsilon_{\beta}(\varSigma)=2^n \sqrt{\prod{eig(\varSigma)}}=2^n .|\varSigma{\frac{1}{2}}|=2n.|\varSigma|^\frac{1}{2}
$$
要计算 SkewIoU,得到相交区域的面积才是关键。如果我们将相交区域也近似成一个高斯分布的话,就可以通过上面的公式计算相交区域面积了。而这个高斯分布则可以通过当前两个高斯分布的乘积的到,公式如下:
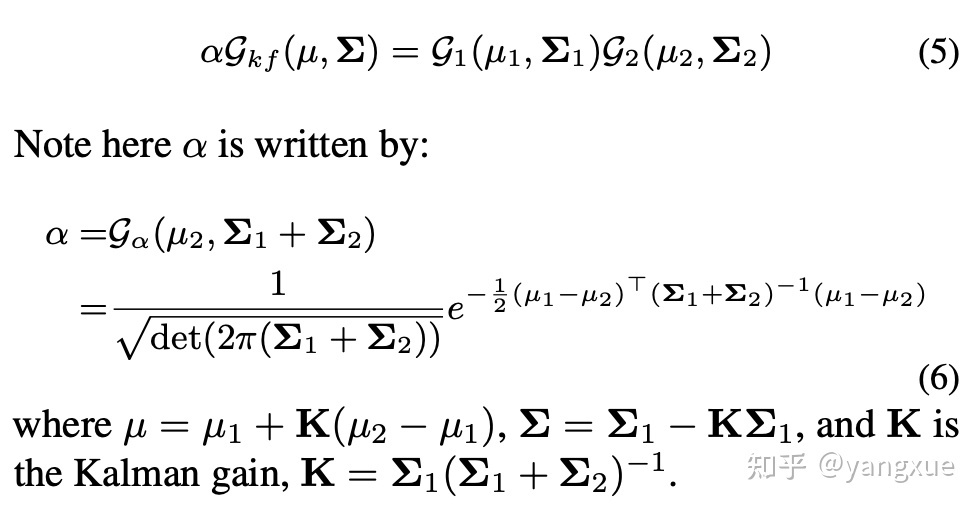
得到新的高斯分布之后,我们不忙着急用它来计算相交区域面积。先仔细观察一下新高斯分布的协方差,该协方差只和相乘的两个高斯的协方差有关,也就意味着无论两个高斯分布如何移动,只要它们的协方差固定,计算出来的面积就不会改变。这显然不符合直觉:当两个高斯分布相距较远时,应该重叠区域面积应该减少。造成这个现象的原因是得到的新高斯分布并不是一个标准的高斯分布,它的前面有一个系数$\alpha$,这个系数则与中心点的距离有关。因此,如果我们要计算相交面积,是需要同时考虑这个系数。根据上述发现,我们引入了中心点损失使得两个高斯分布同中心,这样系数$\alpha$就可以近似成一个常数,从而不需要考虑了。另外,中心点损失的引入也会使得整个损失可以优化没有相交的情况,这个是 SkewIoU 损失无法做到的,也是当前 GIoU 等变种损失所考虑到的。最后计算 KFIoU 的公式如下:
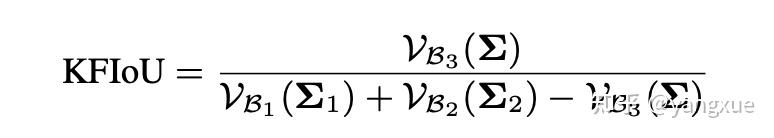
我们在文中附件部分证明了 KFIoU 的取值范围,在 n 维下,值域是 $0\leq KFIoU \leq \frac{1}{2^{\frac{n}{2}+1}-1}$。在二维检测任务中,取值范围是$[0,\frac{1}{3}]$。我们可以轻松将 KFIoU 的值域拉升到 [0, 1] 和 SkewIoU 保持一致,但这个操作并不是必要的,因为我们的目标是 trend-level consistency。通过计算,KFIoU 损失的 EVar 是最小的,而性能也几乎都是最好的,进一步证明了维持 trend-level consistency 的正确性。我们再来逐个分析我们最开始的目标:
- 可以通过当前深度学习框架现有的算子轻松实现:高斯分布转换、矩阵计算都有现成的算子。
- 不引入额外超参数,不需要额外调参:由于 KFIoU 就是模拟的 IoU 的计算过程(交/并),因此不需要超参数。
- 效果比朴素的 SkewIoU 损失更好:可以优化非相交情况;计算完全可导;高斯建模的优势。