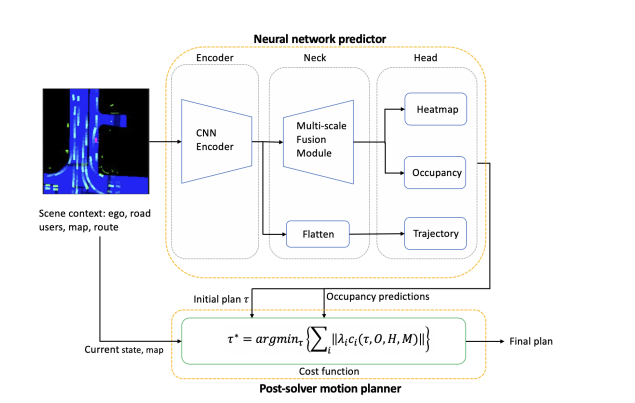
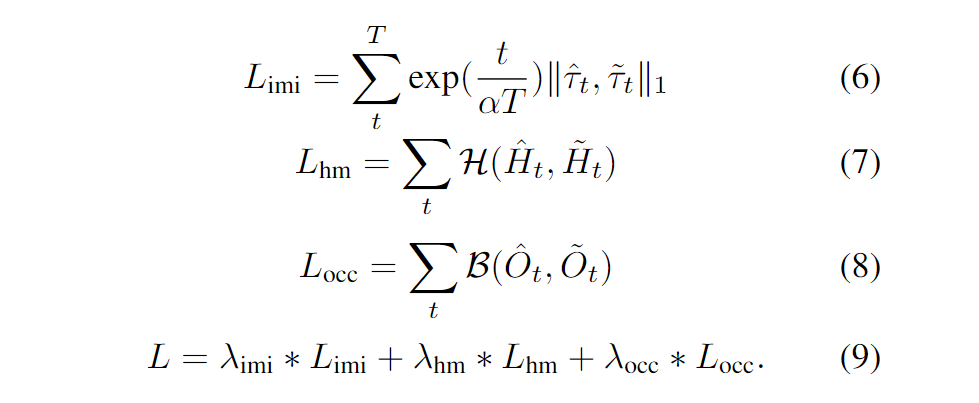
这是horizon做的,nuplan第二 ,https://arxiv.org/pdf/2306.15700.pdf
感觉从UNIAD开始提端到端的都开始玩赖了,网络规划结果只作为优化初始解,然后接个利用感知结果做优化的planning
优化的planning是在线跑的时候才用,训的时候不用,也不能用因为用了的话就梯度消失了,uniad也一样的
E2E现在说是决策导向,但抽出来看他们做的跟决策相关的事情其实是接了一个head输出模仿人类的轨迹,然后在线跑的时候加个优化器把感知的显式结果用上来一套规则决策
如果结果很好的话,我的评价是优化算法设计的不错,因为head扔出来的轨迹质量可以很差,而且我用任何IL/RL算法甚至硬用规则采样也能实现同样的结果,不需要他的head给的优化初始解
本质上他还是模仿学习,让初始优化轨迹像人类轨迹。
但是,决策本质是一个优化问题,我们尝试让网络学会这个优化问题的解法。
比如目标是避免碰撞,那么网络应该通过数据的学习,学会不去执行碰撞动作,我们需要网络生成的轨迹符合我们优化问题的目标。
这些方法里面,网络训练的目标是,输出轨迹像人类轨迹。
然而,最优的决策结果像人类轨迹是充分不必要条件,最优决策结果看起来会很像人类开的,但人类开的轨迹就不是最优轨迹,更不用提模仿学习去拟合真值带来的误差,以及本来就不存在真值。
优化问题被单独拎出来,在在线决策的阶段使用来达成最优决策目标,这违背了用网络做决策的初衷,相当于网络没有学会我们优化的目标,把这个大问题大目标直接规避掉了。