在计算机系统中,缓存无处不在,比如我们访问一个网页,网页和引用的 JS/CSS 等静态文件,根据不同的策略,会缓存在浏览器本地或是 CDN 服务器,那在第二次访问的时候,就会觉得网页加载的速度快了不少;比如微博的点赞的数量,不可能每个人每次访问,都从数据库中查找所有点赞的记录再统计,数据库的操作是很耗时的,很难支持那么大的流量,所以一般点赞这类数据是缓存在 Redis 服务集群中的。
缓存会有哪些问题:
- 内存受限:随机删掉好呢?还是按照时间顺序好呢?或者是有没有其他更好的淘汰策略呢?不同数据的访问频率是不一样的,优先删除访问频率低的数据是不是更好呢?数据的访问频率可能随着时间变化,那优先删除最近最少访问的数据可能是一个更好的选择。我们需要实现一个合理的淘汰策略。;
- 并发写入冲突:对缓存的访问,一般不可能是串行的。map 是没有并发保护的,应对并发的场景,修改操作(包括新增,更新和删除)需要加锁;
- 单机性能不够:单台计算机的资源是有限的,计算、存储等都是有限的。随着业务量和访问量的增加,单台机器很容易遇到瓶颈。如果利用多台计算机的资源,并行处理提高性能就要缓存应用能够支持分布式,这称为水平扩展(scale horizontally)。与水平扩展相对应的是垂直扩展(scale vertically),即通过增加单个节点的计算、存储、带宽等,来提高系统的性能,硬件的成本和性能并非呈线性关系,大部分情况下,分布式系统是一个更优的选择。
设计一个分布式缓存系统,需要考虑资源控制、淘汰策略、并发、分布式节点通信等各个方面的问题。而且,针对不同的应用场景,还需要在不同的特性之间权衡,例如,是否需要支持缓存更新?还是假定缓存在淘汰之前是不允许改变的。不同的权衡对应着不同的实现。
LRU 缓存淘汰策略
最近最少使用,相对于仅考虑时间因素的 FIFO 和仅考虑访问频率的 LFU,LRU 算法可以认为是相对平衡的一种淘汰算法。LRU 认为,如果数据最近被访问过,那么将来被访问的概率也会更高。LRU 算法的实现非常简单,维护一个队列,如果某条记录被访问了,则移动到队尾,那么队首则是最近最少访问的数据,淘汰该条记录即可。
核心数据结构
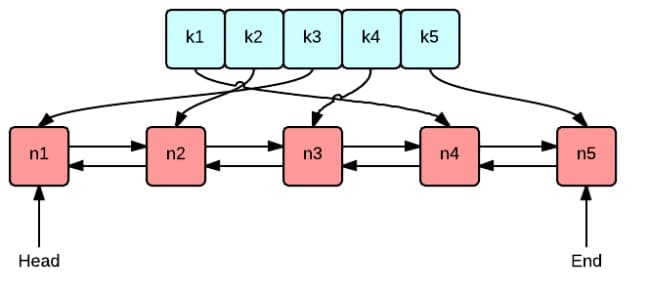
这张图很好地表示了 LRU 算法最核心的 2 个数据结构
- 绿色的是字典(map),存储键和值的映射关系。这样根据某个键(key)查找对应的值(value)的复杂是
O(1),在字典中插入一条记录的复杂度也是O(1)。 - 红色的是双向链表(double linked list)实现的队列。将所有的值放到双向链表中,这样,当访问到某个值时,将其移动到队尾的复杂度是
O(1),在队尾新增一条记录以及删除一条记录的复杂度均为O(1)。
资料:
2. Go语言编程 (豆瓣)