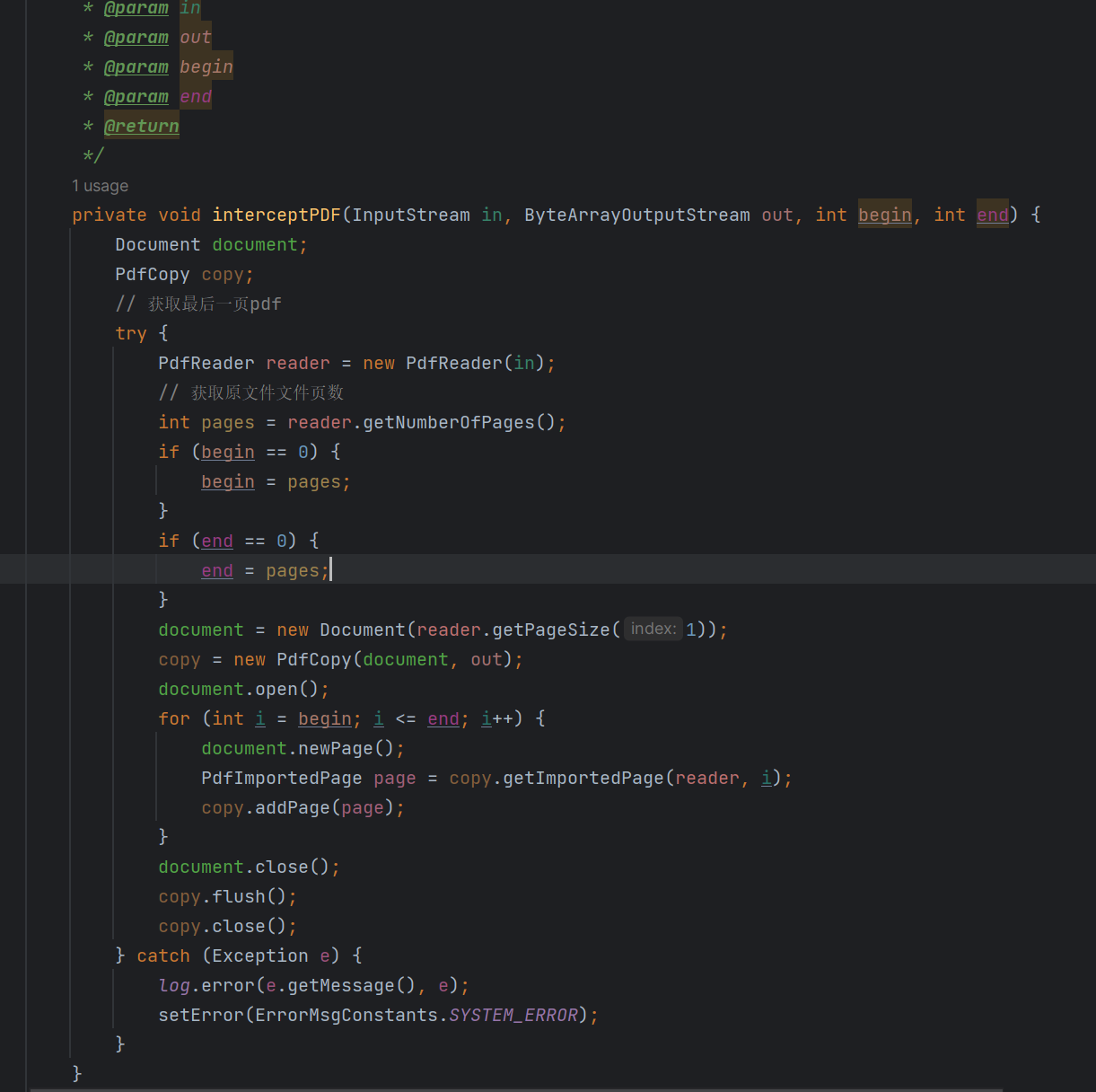
今天做了一个新需求,需要截取一个pdf的最后一页...
在面向百度编程之后呢,,也是成功实现了这个需求,,在这里将代码记录一下,,以后要是遇到类似的需求也可以回来搬一下!
首先是导入一下依赖
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.4.3</version>
</dependency>
其实这个问题也是比较简单的,只需要在我们原有的文件下载方法里,,获取到原文件后进行一个截取就行了,,
我的思路就是将获取到的文件流(inputStream)进行剪裁,,下面就是我的一个简单的工具类,,
参数主要有4个:InputStream,ByteArrayOutputStream,begin(开始截取页数),end(截止页数)