1 数据的生成与导入
这里主要使用的pandas
import pandas as pd
#加载excel数据
df_excel=pd.read_excel('')
df_excel.head()
#加载text数据
df_text=pd.read_table('')
df_text.head()
#加载csv数据
df_csv=pd.read_csv('')
df_csv.head()
2 读取多个数据并合并
import glob
glob.glob(path)
返回所有符合path条件的文件的路径。
import glob
#设置文件路径
path='/user/..../data2'
#合并多个数组
all_files=glob.glob(path+'/*.csv')
all_data=[]
for filename in all_files:
df=pd.read_csv(filename,index_col=None,header=0)
all_data.append(df)
data2=pd.concat(all_data,axis=0,ignore_index=True)
文件


3 数据的信息查看
#查看数据规模(维度)
data.shape
#查看各变量的数据类型
data.dtypes
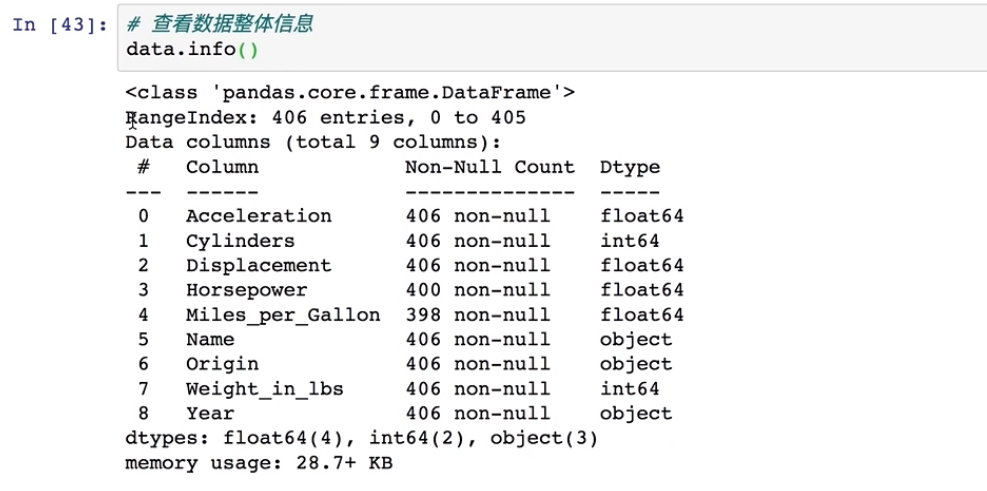
#查看数据的整体信息
data.info()
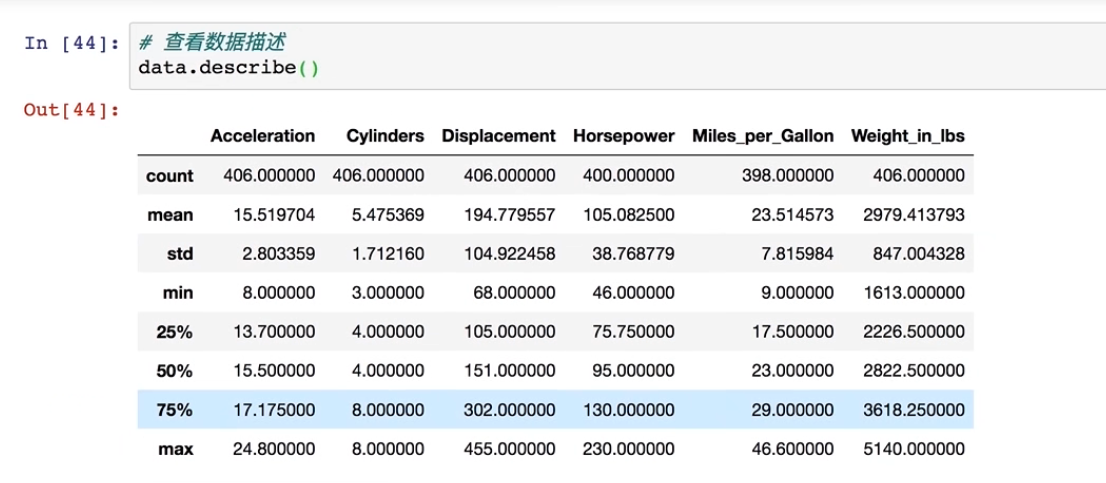
#查看数据的描述
data.decribe()
#查看数据的列名
data.columns
#查看Origin唯一值
data['Origin'].unique()
#查看数据表值
data['Origin'].values
#查看前5行
data.head()
#查看后5行
data.tail()


4 数据清洗与预处理
4.1 查找空值
这个的axis=0就是按照列为标准(一列一列看)
axis=1就是按照行为标准(一行一行看)
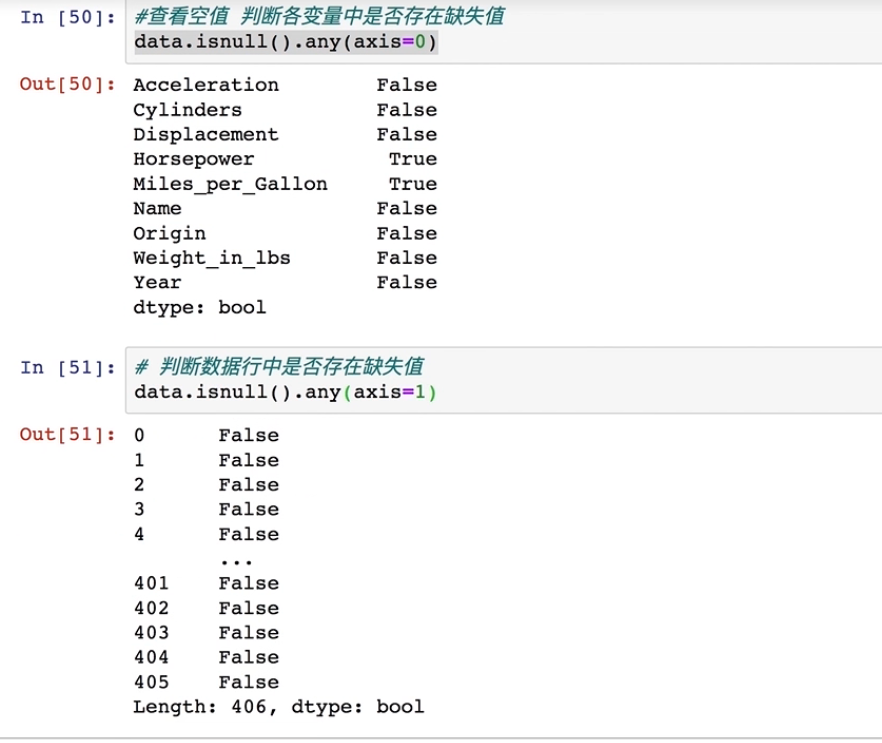
#查看空值,判断各变量中是否存在缺失值
data.isnull().any(axis=0)
#判断数据行中是否存在缺失值
data.isnull().any(axis=1)
#定位缺失值所在的行
data.loc[data.isnull().any(axis=1)]
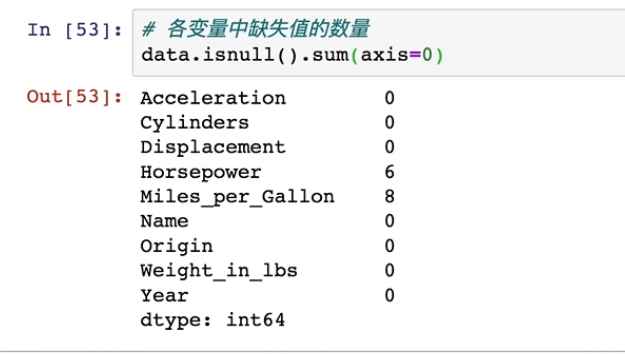
#统计各变量中的缺失值的数量
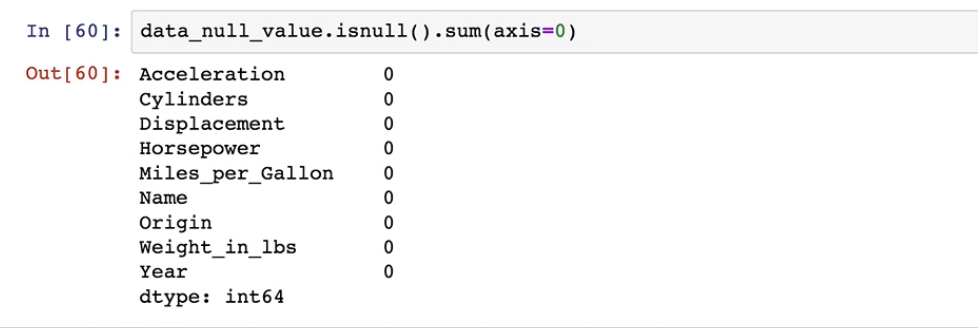
data.isnull().sum(axis=0)

4.2 处理空值
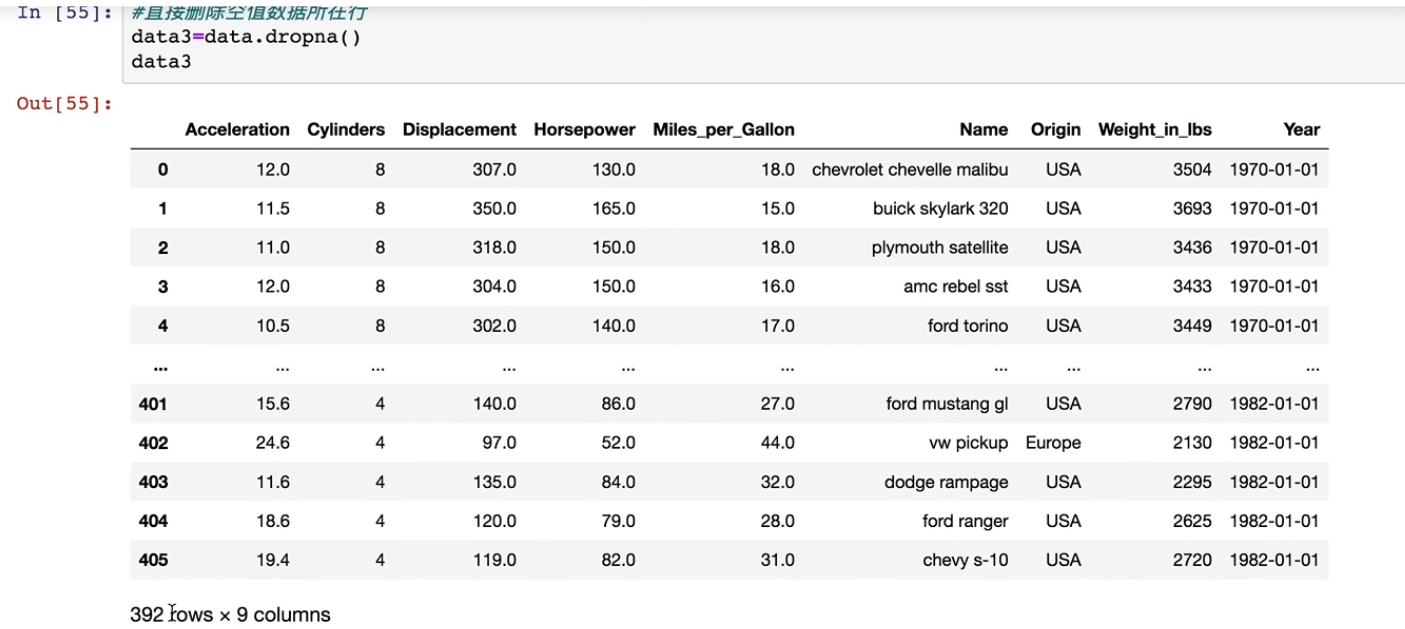
#直接删除空值所在行
data3=data.dropna()
data3
DataFrame.fillna(value=, method=, axis=, inplace=False, limit=, downcast=)
value:用于填充缺失值的值,可以是标量、字典、Series 或 DataFrame。
method:填充缺失值的方法,可选值包括 backfill(向前填充)、bfill(向后填充)、pad(用前面的非缺失数据填充)、ffill(用后面的非缺失数据填充)等。
axis:指定在哪个轴上执行填充操作。
inplace:是否在原 DataFrame 上直接进行修改,True就是把原来的DataFram修改,False反之。
limit:对于前向填充和后向填充,限制填充缺失值的最大数量。
downcast:指定填充后的数据类型,可选值包括infer(自动推断)、integer(整型)等。
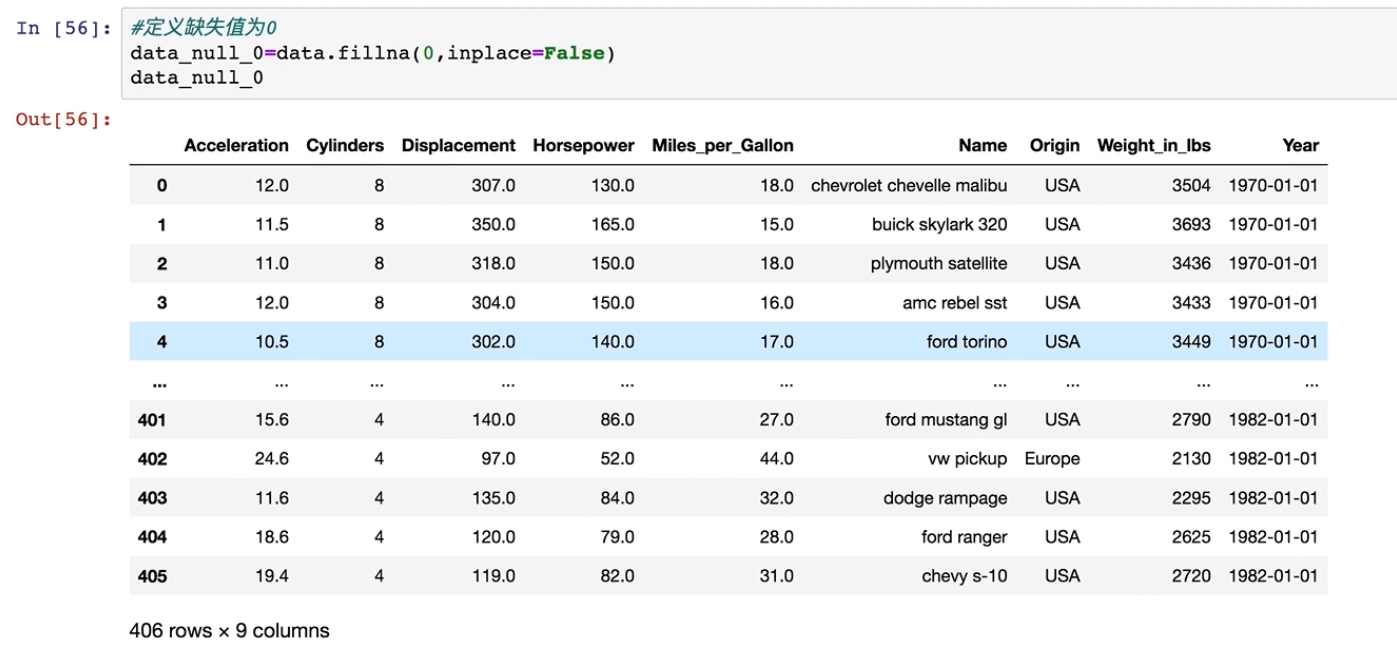
#定义缺失值为0
data_null_0=data.fillna(0,inplace=False)
data_null_0
#对缺失值进行填充(用中位数或者平均数
data_null_value=data.fillna(value={'Horsepower':data['Horsepower'].mode()[0],
'Miles_per_Gallon':data['Miles_per_Gallon'].mean()},inplace=False)
data_null_value
上面是因为fillna支持字典的形式
验证:
4.3 处理重复数据
data_du=pd.read_csv('....csv')
data_du
这里一共有417rows*9columns

#判断数据中是否有重复值
data_du.dupilcated().any()
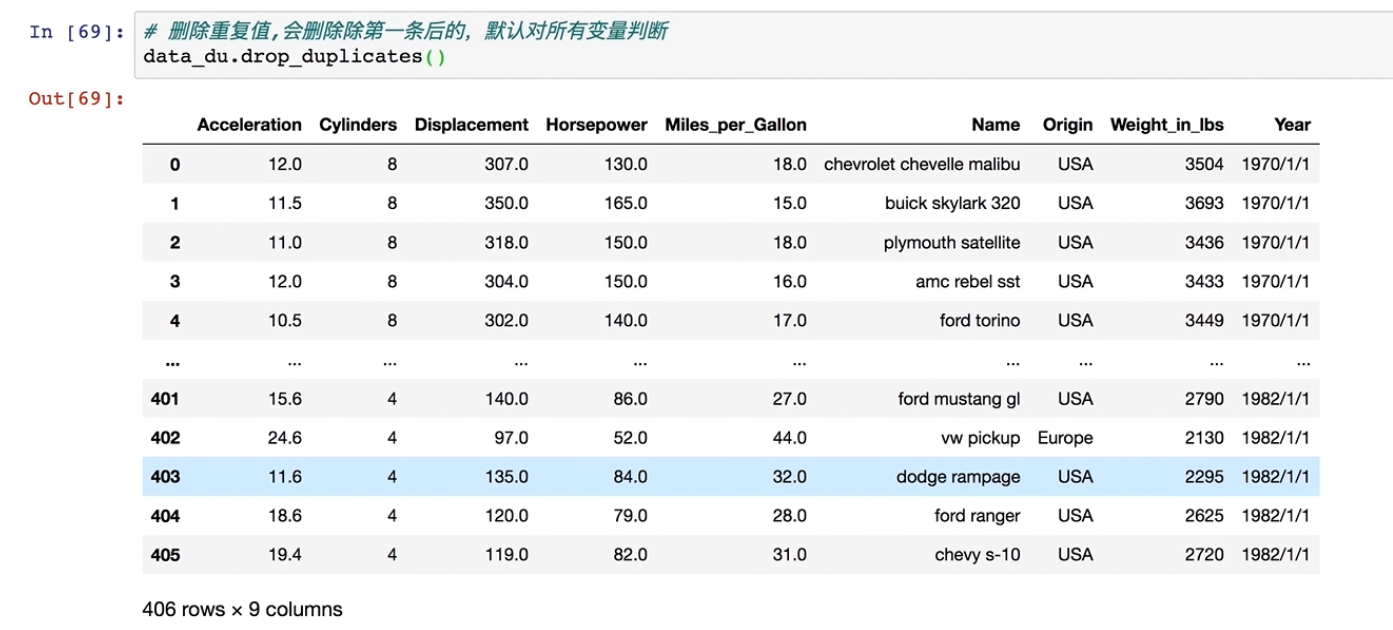
#删除重复值,会删除除第一条后的,默认对所有变量判断
data_du.drop_duplicates()
这里我们看见变成了406*9
#指定变量判断
data_du.drop_duplicates(subset=['Horsepower','Miles_per_Gallon'],keep='First',inplace=False)
#first保留第一个,inplace=True对原数据进行修改

4.4 数据的提取和筛选
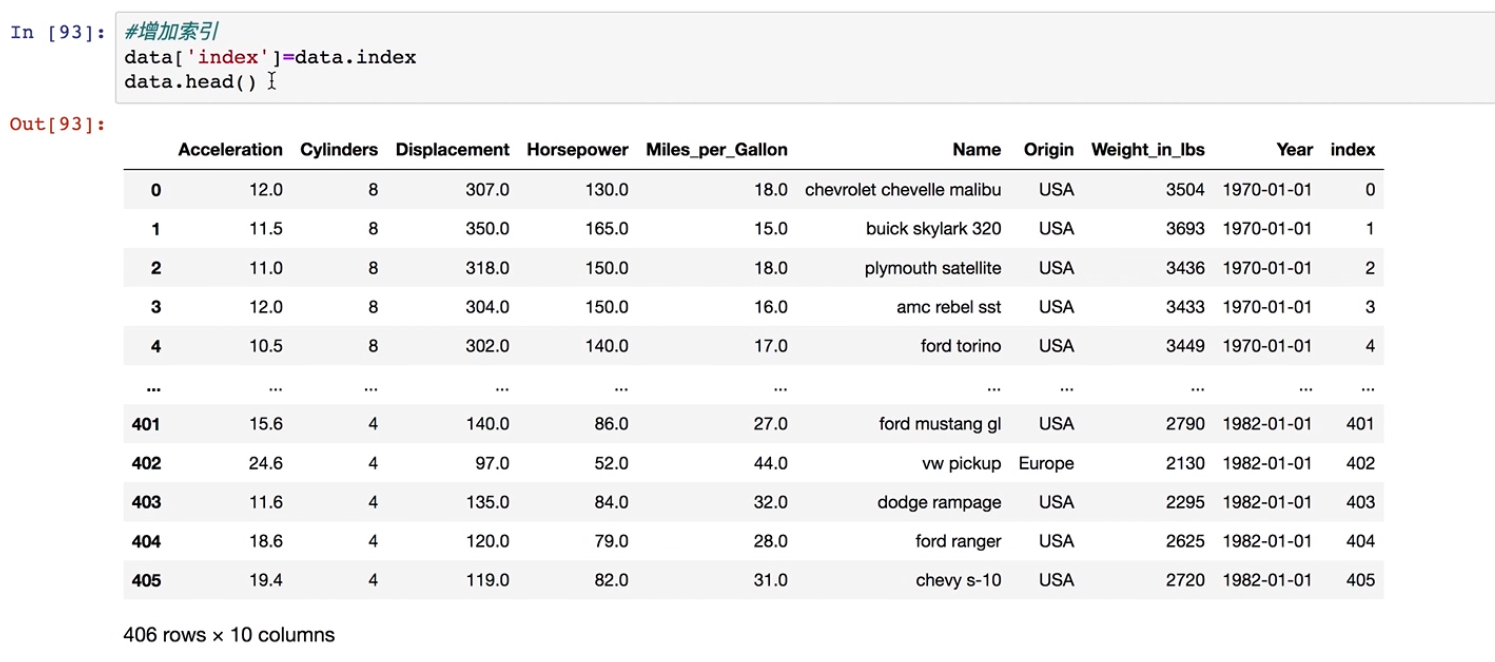
#增加索引
data['index']=data.index
data.head()