前言
分类和回归是数据挖掘和机器学习中常见的两个主要预测问题。
分类算法
分类算法是拟合一个模型或函数的过程,该模型或函数有助于将数据分为多个类别,即离散值。在分类中,根据输入中给定的一些参数,数据被分类到不同的标签下。
-
在分类任务中,我们应该使用独立特征来预测离散的目标变量(类别标签)。
-
在分类任务中,我们需要找到一个决策边界,可以将目标变量中的不同类别分开。
得到的映射函数可以用“IF-THEN”规则的形式来展示。分类任务处理的问题中,数据可以被划分为二分类或多个离散标签的情况。让我们举一个例子,假设我们想要根据历史记录中的参数来预测A队在比赛中获胜的可能性。那么会有两个标签,即是和否。
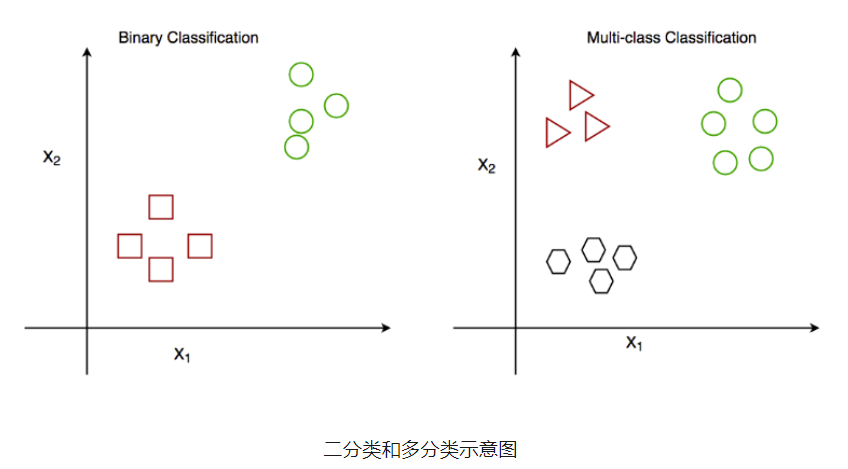
常见的分类算法
随着机器学习研究人员的努力,已经开发出了不同类型的分类算法,并可以通过bagging和boosting等技术来提高分类任务的性能。
-
逻辑回归
-
决策树
-
随机森林
-
K近邻
-
支持向量机
回归算法
回归是寻找一个模型或函数的过程,用于将数据区分为连续的实数值,而不是使用类别或离散值。它还可以根据历史数据识别分布的变化。
-
在回归任务中,我们应该使用独立特征来预测连续的目标变量。
-
在回归任务中,通常会遇到线性回归和非线性回归这两种类型的问题。
让我们也举一个回归任务的例子:我们根据历史记录的参数来预测特定地区的降雨可能性。然后与降雨相关联的是一个概率值。
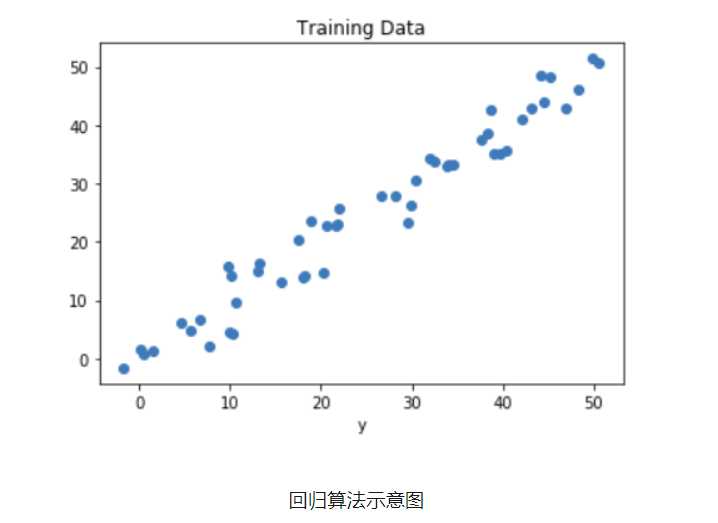
常见的回归算法
回归算法也可以通过bagging和boosting等技术来提高回归任务的性能。
-
线性回归
-
Lasso回归
-
Ridge回归
-
XGBoost回归
分类算法和回归算法的比较
| 分类 |
回归 | |
| 1 | 目标变量是离散的 | 目标变量是连续的 |
| 2 | 垃圾邮件分类、疾病预测 | 房价预测、降雨量预测 |
| 3 | 在这个场景中,我们试图找到可能的最佳决策边界,以实现两个类别之间的最大可能分离 | 在这个场景中,我们试图找到最佳拟合线,以表示数据的总体趋势 |
| 4 | 使用评估指标如精确率(Precision)、召回率(Recall)和 F1 值(F1-Score)来评估分类算法的性能 | 使用评估指标如均方误差(Mean Squared Error)、R2 分数(R2-Score)和平均绝对百分比误差(MAPE)来评估回归算法的性能 |
| 5 | 可以分为二分类和多分类等 | 可以分为线性回归和非线性回归等 |
| 6 | 输出是分类变量 | 输出是连续变量 |
写在最后
小伙伴们记得“点赞、在看、关注”三连,随时查看。
《BAT机器学习面试1000题》资料获取方式:第1步:打开微信搜索:1号程序员,并关注。第2步:在对话框中输入:E001,即可获取资源下载地址。