1 requests高级用法
1.0 自动携带cookie 的session对象
# session对象----》已经模拟登录上了一些网站---》单独把cookie 取出来
-res.cookies 是cookiejar对象,里面有get_dict()方法转换成字典
-转成字典 res.cookies.get_dict()
# 使用session发送请求,cookie自动携带
session=requests.session()
res = session.post('http://www.aa7a.cn/user.php', data=data, headers=header)
res1 = session.get('http://www.aa7a.cn/') #不需要携带cookie了
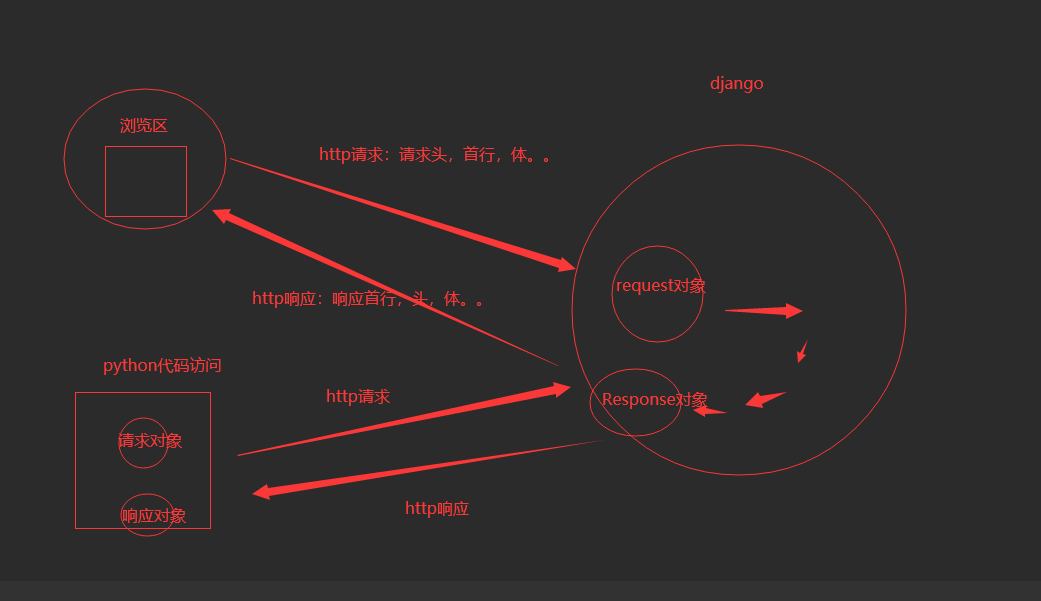
1.1 响应Response
# Http的响应,就是res对象,所有http响应的东西都在这个对象中
res = requests.get('http://www.aa7a.cn/')
import requests
respone=requests.get('http://www.jianshu.com')
# respone属性
print(respone.text) # 响应体转成字符串,默认utf-8,以后打印出来可能乱码
print(respone.content) # 响应体的bytes格式
print(respone.status_code) # 响应状态码
print(respone.headers) # 响应头
print(respone.cookies) # cookie
print(respone.cookies.get_dict()) # cookie转成字典
print(respone.cookies.items()) # 键值对形式
print(respone.url) # 请求地址
print(respone.history) # 访问一个地址,如果重定向了,requests会自动重定向过去,放着重定向之前的地址,列表
print(respone.encoding) # 网页编码
#关闭:response.close()
from contextlib import closing
with closing(requests.get('xxx',stream=True)) as response:
for line in response.iter_content():
# 一点一点取,用来下载图片视频之类
pass
1.2 下载图片到本地
res = requests.get(
'https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fsafe-img.xhscdn.com%2Fbw1%2Fa5ec79fe-843e-4a60-8033-2f73bbda2fa5%3FimageView2%2F2%2Fw%2F1080%2Fformat%2Fjpg&refer=http%3A%2F%2Fsafe-img.xhscdn.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=auto?sec=1691571832&t=c20db6d16f943b4f84502ec5434d1067')
print(res.content)
with open('meinv.png','wb') as f:
for line in res.iter_content(chunk_size=1024):
# chunk_size 是指在下载文件时每次读取的字节数
f.write(line)
1.3 编码问题
直接打印res.text字符串形式---》从网络过来是二进制---》转成字符串涉及到编码---》默认以utf-8---〉现在会自动识别网页编码,自动转成对应的
res.encoding='gbk' # 手动指定编码
print(res.text)
1.4 解析json
# 返回的数据可能是html,也可能是json(前后端分离项目返回数据json格式)
data={
'cname': '',
'pid': '',
'keyword': '周浦',
'pageIndex': 1,
'pageSize': 10
}
res = requests.post('http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword',data=data)
# 也可以写成
header = {'Content-Type':'application/x-www-form-urlencoded'}
res = requests.post('http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword',data='cname=&pid=&keyword=%E5%91%A8%E6%B5%A6&pageIndex=1&pageSize=10',headers=header)
print(res.json())
1.5 ssl认证(了解)
# https的请求
# 浏览器访问有证书,代码访问没有证书
res = requests.get('https://cnblogs.com/liuqingzheng/p/16005866.html',verify=False) # verify=False后不验证证书
# 极个别网站必须要验证,需要手动携带证书
import requests
respone=requests.get('https://www.12306.cn',
cert=('/path/server.crt',
'/path/key')) # 本地得有证书,写路径和密钥
print(respone.status_code)
# https和http的区别
# 参考文章?https://zhuanlan.zhihu.com/p/561907474
1.默认端口不同:443/80
2.https=http+ssl|tls,https保证了传输过程中数据的安全,可以防止中间人的攻击
1.6 使用代理(重要)
# 访问某些网站频率过高,就会被封ip===》使用代理ip访问
import requests
proxies={
'http':'104.193.88.77:80'
}
respone=requests.get('https://www.12306.cn',
proxies=proxies)
print(respone.status_code)
1.7 超时设置
#两种超时:float or tuple
#timeout=0.1 #代表接收数据的超时时间
#timeout=(0.1,0.2)#0.1代表链接超时 0.2代表接收数据的超时时间
import requests
respone=requests.get('https://www.baidu.com',
timeout=0.0001)
1.8 异常处理
#异常处理
import requests
from requests.exceptions import * #可以查看requests.exceptions获取异常类型
try:
r=requests.get('http://www.baidu.com',timeout=0.00001)
except ReadTimeout:
print('===:')
# except ConnectionError: #网络不通
# print('-----')
# except Timeout:
# print('aaaaa')
except RequestException:
print('Error')
1.9 上传文件
# 爬虫里面不会用,但是调用第三方服务的时候可能会用到,提供一个接口上传文件
def upload(request):
file = request.FILES.get('myfile')
with open('%s.png'% file.name,'wb') as f:
for line in file:
f.write(line)
return HttpResponse('上传成功')
import requests
files={'myfile':open('a.jpg','rb')}
respone=requests.post('http://127.0.0.1/upload',files=files)
print(respone.status_code)
认证登陆(了解)
# HTTPBasicAuth可以简写为如下格式
# 很难见到,古早路由器拨号登陆
import requests
r=requests.get('xxx',auth=('user','password'))
print(r.status_code)
2 代理池搭建
import requests
proxies = {
'http': '104.193.88.77:80',
}
respone=requests.get('http://127.0.0.1:8000/',proxies=proxies)
print(respone)
# 搭建一个代理池---》每次可以从池中随机取出一个代理---》发送请求
# 公司内部要用,会花钱买
# 咱们自己用,基于网上的开源软件,自己搭建
## 开源的代理池核心原理:https://github.com/jhao104/proxy_pool
-1 使用爬虫技术,爬取网上免费的代理
-2 爬完回来做验证,如果能用,存到redis中
# 启动调度程序,爬代理,验证,存到redis中
python proxyPool.py schedule
-3 使用flask启动服务,对外开放了几个接口,向某个接口发请求,就能随机获取一个代理
# 启动webApi服务
python proxyPool.py server
#搭建步骤:
1 从git拉去开源代码
git clone https://github.com/jhao104/proxy_pool.git
2 使用pycharm打开,创建虚拟环境
mkvirtualenv -p python3 pool
3 配置项目使用虚拟环境
4 修改项目配置文件
DB_CONN = 'redis://127.0.0.1:6379/2'
HTTP_URL = "http://www.baidu.com"
HTTPS_URL = "https://www.baidu.com"
5 启动调度程序---》爬取网站,验证,存到redis
python proxyPool.py schedule
6 启动web程序(flask写的)
python proxyPool.py server
7 向http://192.168.1.252:5010/get/?type=http 地址发送请求就可以随机获取代理ip
2.1 django后端获取客户端的ip
import requests
res = requests.get('http://192.168.1.252:5010/get/?type=http').json()['proxy']
proxies = {
'http': res,
}
print(proxies)
# 我们是http 要使用http的代理
respone = requests.get('http://139.155.203.196:8080/', proxies=proxies)
print(respone.text)
3 爬取某视频网站
# https://www.pearvideo.com/
# 加载下一页的地址
https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=0
import requests
import re
res = requests.get('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=0')
video_list = re.findall('<a href="(.*?)" class="vervideo-lilink actplay">', res.text)
print(video_list)
for video in video_list:
url = 'https://www.pearvideo.com/' + video
header = {
'Referer': url
}
video_id = video.split('_')[-1]
video_url = 'https://www.pearvideo.com/videoStatus.jsp?contId=%s&mrd=0.8273125965736401' % video_id
res1 = requests.get(video_url, headers=header).json() # 真正能拿到视频的地址发送请求
real_mp4_url = res1['videoInfo']['videos']['srcUrl']
real_mp4_url = real_mp4_url.replace(real_mp4_url.split('/')[-1].split('-')[0], 'cont-%s' % video_id)
print(real_mp4_url)
res2 = requests.get(real_mp4_url)
with open('./video/%s.mp4' % video, 'wb') as f:
for line in res2.iter_content():
f.write(line)
# ajax 请求拿回来的视频地址是:
# 能播放的地址:
# https://video.pearvideo.com/mp4/adshort/20181106/ 1688703103822 -13189302_adpkg-ad_hd.mp4 # 不能的
# https://video.pearvideo.com/mp4/adshort/20181106/ cont-1470647 -13189302_adpkg-ad_hd.mp4 #能的
# url = 'https://video.pearvideo.com/mp4/adshort/20181106/1688703103822-13189302_adpkg-ad_hd.mp4'
作业
# 最后爬视频,爬5页,使用多线程(线程池),使用代理
import requests
from concurrent.futures import ThreadPoolExecutor
import re
def get_video(url):
res = requests.get(url)
video_list = re.findall('<a href="(.*?)" class="vervideo-lilink actplay">', res.text)
for video in video_list:
video_url1 = 'https://www.pearvideo.com/' + video
header = {
'Referer': video_url1
}
video_id = video.split('_')[-1]
video_url2 = 'https://www.pearvideo.com/videoStatus.jsp?contId=%s&mrd=0.8273125965736401' % video_id
res1 = requests.get(video_url2, headers=header).json()
real_video_url = res1['videoInfo']['videos']['srcUrl']
real_video_url = real_video_url.replace(real_video_url.split('/')[-1].split('-')[0], 'cont-%s' % video_id)
res2 = requests.get(real_video_url)
with open('./video/%s.mp4' % video, 'wb') as f:
for line in res2.iter_content():
f.write(line)
if __name__ == '__main__':
pool = ThreadPoolExecutor(5)
urls = ['https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=0',
'https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=72',
'https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=96']
for url in urls:
pool.submit(get_video, url)
pool.shutdown(wait=True)