selenium-元素定位方式CSS的详细使用
发布时间 2023-03-30 21:54:15作者: 不氪金玩家
Web UI自动化中,定位方式的优先级
- 优先级最高:ID
- 优先级其次:name
- 优先级再次:CSS selector
- 优先级再次:Xpath
在项目中我们可能用的最多的是css或者xpath,那么针对这两种,我们优先选择css,原因在哪些?
- 原因1:css是配合html来工作,它实现的原理是匹配对象的原理,而xpath是配合xml工作的,它实现的原理是遍历的原理,所以两者在设计上,css性能更优秀
- 原因2:语言简洁,明了,相对xpath
- 原因3:前端开发主要是使用css,不使用xpath,所以在技术上面,我们可以获得帮助的机会非常多
定位元素的注意事项
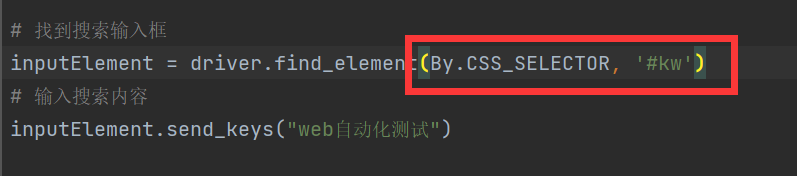
- 找到待定位元素的唯一属性
- 如果该元素没有唯一属性,则先找到能被唯一定位到的父元素/子元素/相邻元素,再使用 > , " " , + 等进行辅助定位
- 不要使用随机唯一属性定位
- 最重要的是多跟研发沟通,尽量把关键元素加上ID或者name,并减少不合理的页面元素,例如重复ID这样的事情最好不要发生
基础的CSS选择器
| 选择器 |
名字 |
例子 |
例子描述 |
| 基础选择器 |
| .class |
class选择器 |
.intro |
选择 class="intro" 的所有元素。 |
| #id |
id选择器 |
#firstname |
选择 id="firstname" 的所有元素。 |
| * |
通配符 |
|
选择所有元素。 |
| element |
标签选择器 |
p |
选择所有 <p> 元素。 |
| 多层选择器 |
| element,element |
分组选择器 |
div,p |
同时选择所有 <div> 元素和所有 <p> 元素。 |
| element element |
后端选择器 |
div p |
选择 <div> 元素内部的所有 <p> 元素(包括子元素、孙子元素) |
| element>element |
子元素选择器 |
div>p |
选择 <div> 元素下的 <p> 子元素。 |
| element+element |
相邻选择器 |
div+p |
选择 <div> 元素之后的所有兄弟 <p> 元素。 |
| 属性选择器 |
| [attribute] |
[target] |
|
选择带有 target 属性所有元素。 |
| [attribute=value] |
[target=_blank] |
|
选择 target="_blank" 的所有元素。 |
| [attribute~=value] |
[title~=flower] |
|
选择 title 属性包含单词 "flower" 的所有元素。 |
| [attribute|=value] |
[lang|=en] |
|
选择 lang 属性值以 "en" 开头的所有元素。 |
伪类选择器
| 选择器 |
例子 |
例子描述 |
| :first-child |
p:first-child |
选择属于父元素的第一个子元素的每个 <p> 元素。 |
| :nth-child(n) |
p:nth-child(2) |
选择属于其父元素的第二个子元素的每个 <p> 元素。 |
| :nth-last-child(n) |
p:nth-last-child(2) |
同上,从最后一个子元素开始计数。 |
| :nth-of-type(n) |
p:nth-of-type(2) |
选择属于其父元素第二个 <p> 元素的每个 <p> 元素。 |
| :nth-last-of-type(n) |
p:nth-last-of-type(2) |
同上,但是从最后一个子元素开始计数。 |
| :last-child |
p:last-child |
选择属于其父元素最后一个子元素每个 <p> 元素。 |