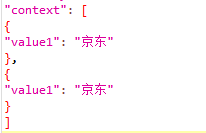
在使用jmeter做压测时,除了增加并发数,还可能在请求体中增加多个字段相同的list。如图:
如果是几百条可以复制粘贴,但是几千上万条复制粘贴就比较费时费力了。另外可能这些数据并不是完全相同,可能还需要并发执行。
一.数据容器
当请求体是由多个字段相同的list组成时,可以把这些list存放在txt文件里,通过CSV数据文件设置传参给请求体。
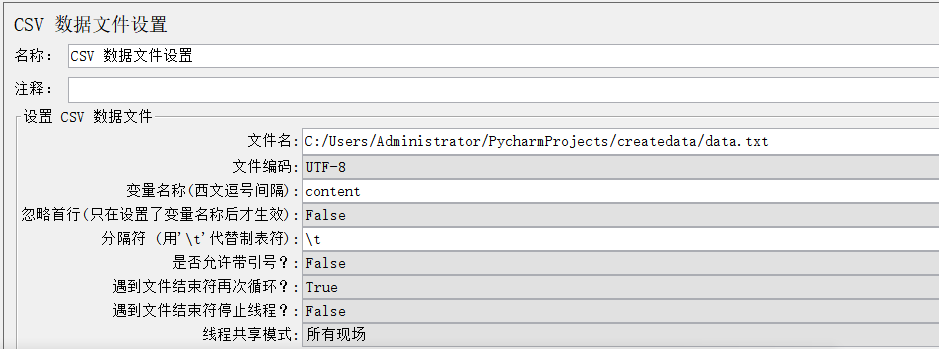
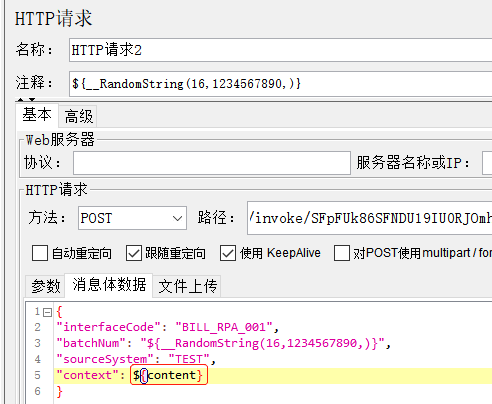
二.数据来源
但是成千上万条list要如何在txt文件中生成呢?
这里使用python循环,然后通过python读写文件,把循环得到的数据存入文件中,得到一个txt文件。
三.造数据代码
1.请求体里每个list数据完全相同
import json data_text=[] for x in range(2): a={ #a为list "value1": "京东" } data_text.append(a) #把a添加到列表里,循环多次 filename="data.txt" #在当前路径下的txt文件 with open(filename,"a",encoding="utf-8") as fd: #需要加utf-8,否则写入的内容会出现中文乱码 fd.write(json.dumps(data_text,ensure_ascii=False)) #写入内容 fd.write("\n") fd.close()
文件输出结果:

得到一行list数据相同的数据。
2.并发数为1,请求体里的list字段相同但是某些字段的数据不同
import json data_text=[] for x in range(2): a={ "value1": "京东"+str(x+1) #每次循环a的value1字段的值都不同 } data_text.append(a) filename="data.txt" with open(filename,"a",encoding="utf-8") as fd: fd.write(json.dumps(data_text,ensure_ascii=False)) fd.write("\n") fd.close()
文件输出结果:

得到一行list数据不同的数据,如果执行多个并发时,传入txt文件的数据是相同的。
3.并发数大于1,请求体里的list字段相同但是某些字段数据不同
import json def coniface_list(numi,numj): i = 1 #i为需要的并发数 while i <= numi: a = [] j = 1 #j为列表包含的list数量 while j <= numj: b = { "value1": "京东"+ str(i) + str(j) #每次循环b的value1字段不同 } a.append(b) j += 1 filename = "data.txt" with open(filename,"a",encoding="utf-8") as f: f.write(json.dumps(a, ensure_ascii=False)) f.write("\n") i += 1 f.close() coniface_list(3,3) #调用函数
文件输出结果:

得到三行不同数据,可以在并发大于1时传入txt文件的数据,每个并发传入的数据是不同的。