Overlay Filesystem
本文档描述了在Linux中提供叠加文件系统功能的新方法的原型(有时称为联合文件系统)。叠加文件系统试图呈现一个文件系统,该文件系统是在另一个文件系统之上叠加而成的结果。
叠加对象
叠加文件系统的方法是“混合的”,因为出现在文件系统中的对象并不总是看起来属于该文件系统。在许多情况下,通过联合访问的对象在访问原始文件系统中的相应对象时是无法区分的。这在通过stat(2)返回的“st_dev”字段中最为明显。
虽然目录将报告来自叠加文件系统的st_dev,但非目录对象可能会报告来自提供该对象的下层文件系统或上层文件系统的st_dev。类似地,只有当与st_dev结合时,st_ino才会是唯一的,而且这两者在非目录对象的生命周期内都可能会发生变化。许多应用程序和工具会忽略这些值,因此不会受到影响。
在所有叠加层都位于相同底层文件系统的特殊情况下,所有对象将报告来自叠加文件系统的st_dev和来自底层文件系统的st_ino。这将使叠加挂载更符合文件系统扫描器的要求,并且叠加对象将与原始文件系统中的相应对象可区分。
在64位系统上,即使所有叠加层不位于相同的底层文件系统上,也可以通过“xino”特性实现相同的符合行为。 “xino”特性从真实对象的st_ino和底层fsid索引组合出一个唯一的对象标识符。 “xino”特性使用高inode号位用于fsid,因为底层文件系统很少使用高inode号位。如果底层inode号溢出到高xino位,叠加文件系统将对该inode回退到非xino行为。
“xino”特性可以通过“-o xino=on”叠加挂载选项启用。如果所有底层文件系统都支持NFS文件句柄,则叠加文件系统对象的st_ino值不仅是唯一的,而且在文件系统的生命周期内也是持久的。 “-o xino=auto”叠加挂载选项仅在满足持久st_ino要求时启用“xino”特性。
以下表总结了不同叠加配置中可以期望的内容。
Inode的属性
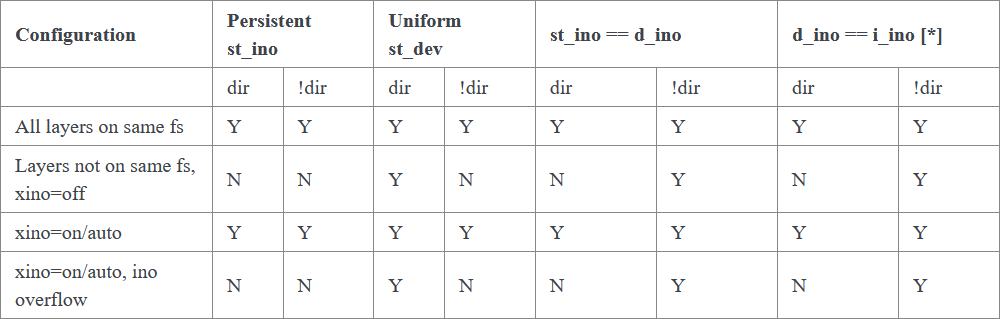
[*] nfsd v3 readdirplus 验证 d_ino == i_ino。 i_ino 通过几个 /proc 文件暴露,例如 /proc/locks 和 /proc/self/fdinfo/<fd>(其中 <fd> 是 inotify 文件描述符)。
上层和下层
叠加文件系统结合了两个文件系统 - 一个“上层”文件系统和一个“下层”文件系统。当一个名称同时存在于两个文件系统中时,“上层”文件系统中的对象是可见的,而“下层”文件系统中的对象要么被隐藏,要么(对于目录而言)与“上层”对象合并。
更准确的说法是将上层和下层称为“目录树”,而不是“文件系统”,因为两个目录树很可能位于同一个文件系统中,并且不需要为上层或下层指定文件系统的根目录。
Linux支持的广泛范围的文件系统可以作为下层文件系统,但并非所有可由Linux挂载的文件系统都具有OverlayFS工作所需的功能。下层文件系统不需要是可写的。下层文件系统甚至可以是另一个overlayfs。上层文件系统通常是可写的,如果是可写的话,它必须支持创建trusted.和/或user.扩展属性,并且必须在readdir响应中提供有效的d_type,因此NFS不适用。
两个只读文件系统的只读叠加可以使用任何文件系统类型。
目录
叠加主要涉及目录。如果一个给定的名称同时出现在上层和下层文件系统中,并且分别指向非目录对象,则下层对象将被隐藏 - 该名称只指向上层对象。
如果上层和下层对象都是目录,则形成一个合并的目录。
在挂载时,作为挂载选项“lowerdir”和“upperdir”给出的两个目录将被合并为一个合并的目录:
mount -t overlay overlay -olowerdir=/lower,upperdir=/upper,workdir=/work /merged
“workdir”需要是与upperdir相同文件系统上的空目录。
然后,每当在这样一个合并的目录中请求查找时,将在每个实际目录中进行查找,并将合并的结果缓存在属于叠加文件系统的dentry中。如果两个实际查找都找到目录,则两者都被存储,并创建一个合并的目录,否则只存储一个:如果存在上层,则存储上层,否则存储下层。
只有来自目录的名称列表被合并。其他内容,如元数据和扩展属性,仅针对上层目录报告。下层目录的这些属性将被隐藏。
白出和不透明目录
为了支持rm和rmdir而不更改下层文件系统,叠加文件系统需要在上层文件系统中记录已删除文件的信息。这是通过使用白出和不透明目录(非目录始终是不透明)来实现的。
白出是以0/0设备号创建的字符设备。当在合并目录的上层发现白出时,将忽略下层中任何匹配的名称,并且白出本身也将被隐藏。
通过将xattr“trusted.overlay.opaque”设置为“y”来使目录成为不透明。如果上层文件系统包含不透明目录,则将忽略下层文件系统中具有相同名称的任何目录。
readdir
当在合并目录上进行“readdir”请求时,将分别读取上层和下层目录,并以明显的方式合并名称列表(首先读取上层,然后读取下层 - 已存在的条目不会被重新添加)。这个合并的名称列表被缓存在属于叠加文件系统的“struct file”中,因此只要文件保持打开状态,它就会保持不变。如果目录被两个进程同时打开和读取,它们将各自拥有独立的缓存。将seekdir定位到目录的开头(偏移量为0),然后进行readdir将导致缓存被丢弃并重新构建。
这意味着在读取目录时,对合并目录的更改不会立即显示出来。这对许多程序来说可能不太明显。
当目录被读取时,seek偏移量是按顺序分配的。因此,如果:
- 读取目录的一部分
- 记住一个偏移量,并关闭目录
- 一段时间后重新打开目录
- 将偏移量定位到记住的位置
在文件名列表中的旧位置和新位置之间可能几乎没有关联,特别是如果目录中有任何更改。
对于未合并的目录进行的readdir操作将简单地由底层目录(上层或下层)处理。
重命名目录
当重命名位于下层或合并的目录(即目录最初不是在上层创建的)时,overlayfs可以以两种不同的方式处理:
-
返回EXDEV错误:当尝试跨文件系统边界移动文件或目录时,rename(2)会返回此错误。因此,应用程序通常准备处理此错误(例如,mv(1)会递归地复制目录树)。这是默认行为。
-
如果启用了“redirect_dir”功能,则目录将被复制上来(但不包括内容)。然后将“trusted.overlay.redirect”扩展属性设置为从叠加根目录到原始位置的路径。最后,目录将移动到新位置。
有几种方法可以调整“redirect_dir”功能。
内核配置选项:
-
OVERLAY_FS_REDIRECT_DIR:如果启用了此选项,则默认情况下会打开redirect_dir。
-
OVERLAY_FS_REDIRECT_ALWAYS_FOLLOW:如果启用了此选项,则默认情况下总是跟随重定向。启用此选项会导致配置不太安全。仅在担心与始终跟随重定向的内核的向后兼容性时启用此选项。
模块选项(也可以通过/sys/module/overlay/parameters/进行更改):
-
"redirect_dir=BOOL":参见上面的OVERLAY_FS_REDIRECT_DIR内核配置选项。
-
"redirect_always_follow=BOOL":参见上面的OVERLAY_FS_REDIRECT_ALWAYS_FOLLOW内核配置选项。
-
"redirect_max=NUM":绝对重定向的最大字节数(默认为256)。
挂载选项:
-
"redirect_dir=on":启用重定向。
-
"redirect_dir=follow":不创建重定向,但跟随重定向。
-
"redirect_dir=nofollow":不创建重定向,也不跟随重定向。
-
"redirect_dir=off":如果在内核/模块配置中启用了"redirect_always_follow",则此“off”将转换为“follow”,否则将转换为“nofollow”。
当启用NFS导出功能时,每个复制上来的目录都由下层inode的文件句柄和上层目录的文件句柄索引,并且上层目录的文件句柄存储在索引条目的“trusted.overlay.upper”扩展属性中。在查找合并目录时,如果上层目录与索引中存储的文件句柄不匹配,这表明多个上层目录可能被重定向到同一个下层目录。在这种情况下,查找将返回错误并警告可能存在不一致性。
因为无法使用索引验证下层重定向,因此在没有上层的叠加文件系统上启用NFS导出支持需要关闭重定向跟随(例如,“redirect_dir=nofollow”)。
非目录对象
不是目录的对象(文件、符号链接、设备特殊文件等)要么来自上层文件系统,要么来自下层文件系统。当以需要写访问权限的方式访问下层文件系统中的文件时,例如打开以进行写访问、更改某些元数据等操作,文件首先会从下层文件系统复制到上层文件系统(copy_up)。请注意,创建硬链接也需要进行copy_up,尽管创建符号链接不需要。
copy_up可能是不必要的,例如如果文件以读写方式打开但数据没有被修改。
copy_up过程首先确保上层文件系统中包含的目录存在-在需要时创建它和任何父目录。然后使用相同的元数据(所有者、模式、修改时间、符号链接目标等)创建对象,如果对象是文件,则将数据从下层文件系统复制到上层文件系统。最后,复制任何扩展属性。
完成copy_up后,叠加文件系统只需直接访问上层文件系统中新创建的文件-对文件的未来操作几乎不会被叠加文件系统注意到(尽管对文件名的操作,如重命名或取消链接,当然会被注意到和处理)。
权限模型
叠加文件系统中的权限检查遵循以下原则:
-
权限检查应在copy up之前和之后返回相同的结果
-
创建叠加挂载的任务不得获得额外的特权
-
非挂载任务可以通过叠加获得比直接访问底层下层或上层文件系统更多的特权
这通过对每个访问执行两个权限检查来实现
a. 检查当前任务是否根据本地DAC(所有者、组、模式和posix acl)以及MAC检查允许访问
b. 检查挂载任务是否根据底层文件系统权限允许对下层或上层层进行实际操作,再次包括MAC检查
检查(a)确保了一致性(1),因为所有者、组、模式和posix acls被复制。另一方面,它可能会忽略服务器强制执行的权限(例如NFS使用的权限)(3)。
检查(b)确保没有任务获得挂载任务没有的底层层的权限(2)。这也意味着可以创建不满足一致性规则(1)的设置;然而,通常,挂载任务将具有足够的特权来执行所有操作。
另一种演示此模型的方法是在以下命令之间进行类比
mount -t overlay overlay -olowerdir=/lower,upperdir=/upper,... /merged
和
cp -a /lower /upper mount --bind /upper /merged
结果的访问权限应该是相同的。区别在于复制的时间(按需与预先)。
多个下层层
现在可以使用冒号(“:”)作为目录名称之间的分隔符来指定多个下层层。例如:
mount -t overlay overlay -olowerdir=/lower1:/lower2:/lower3 /merged
如示例所示,“upperdir=”和“workdir=”可以省略。在这种情况下,叠加将是只读的。
指定的下层目录将从最右边的目录开始堆叠,并向左移动。在上述示例中,lower1将是顶部,lower2将是中间,lower3将是底层。
注意:包含冒号的目录名称可以通过使用单个反斜杠对冒号进行转义来作为下层层提供。例如:
mount -t overlay overlay -olowerdir=/a:lower::dir /merged
自内核版本v6.5以来,还可以使用新的mount api中的fsconfig系统调用将包含冒号的目录名称作为下层层提供:
fsconfig(fs_fd, FSCONFIG_SET_STRING, "lowerdir", "/a:lower::dir", 0);
在后一种情况下,当在/proc/self/mountinfo中显示时,下层层目录名称中的冒号将转义为八进制字符(072)。
仅元数据复制
启用元数据仅复制功能后,当执行元数据特定操作(例如chown/chmod)时,overlayfs仅复制元数据(而不是整个文件)。完整文件将在打开文件进行写操作时稍后复制。
换句话说,这是延迟数据复制操作,只有在实际修改数据时才会复制数据。
有多种方法可以启用/禁用此功能。可以设置/取消设置配置选项CONFIG_OVERLAY_FS_METACOPY以默认启用/禁用此功能。或者可以在模块加载时使用模块参数metacopy=on/off启用/禁用它。最后,还有一个每个挂载选项metacopy=on/off,用于每个挂载启用/禁用此功能。
不要在不受信任的上层/下层目录中使用metacopy=on。否则,攻击者可以创建一个手工制作的文件,其中包含适当的REDIRECT和METACOPY xattr,并访问由REDIRECT指向的下层文件。这在本地系统上是不可能的,因为设置“trusted.” xattr将需要CAP_SYS_ADMIN。但是对于不受信任的层(例如来自U盘),这应该是可能的。
注意:redirect_dir={off|nofollow|follow[*]}和nfs_export=on挂载选项与metacopy=on冲突,并将导致错误。
[*] redirect_dir=follow仅在给出upperdir=...时与metacopy=on冲突。
仅数据下层
启用“metacopy”功能后,overlayfs常规文件可以是来自最多三个不同层的信息的组合:
-
来自上层的文件的元数据
-
来自下层的文件的st_ino和st_dev对象标识符
-
来自另一个下层的文件的数据(更低层)
“较低数据”文件可以位于任何下层,除了最顶层下层。
在最顶层下层以下,可以使用双冒号(“::”)分隔符定义任意数量的“仅数据”下层。不允许将普通下层放在数据仅下层下面,因此不允许在双冒号(“::”)分隔符右侧使用单个冒号分隔符。
例如:
mount -t overlay overlay -olowerdir=/l1:/l2:/l3::/do1::/do2 /merged
在合并的overlayfs目录中,不可见“仅数据”下层中的文件的路径,overlayfs节点中的文件的元数据和st_ino/st_dev也不可见。
只有“仅数据”下层中文件的数据可能在上面的一个下层中的“metacopy”文件中可见,该文件具有指向“仅数据”下层中的“较低数据”文件的绝对路径的“重定向”。
fs-verity 支持
在下层文件进行元数据复制时,如果源文件启用了 fs-verity 并且启用了叠加 verity 支持,那么下层文件的摘要将被添加到 "trusted.overlay.metacopy" xattr 中。然后在打开 metacopy 文件时,将用于验证下层文件的内容。
当使用包含 verity xattrs 的层时,这意味着上层中任何此类 metacopy 文件都保证与复制时下层中的内容匹配。如果在任何时候(在挂载期间,重新挂载后等)下层中的这样一个文件被替换或以任何方式修改,访问 overlayfs 中相应的文件将导致 EIO 错误(由于 overlayfs 摘要检查而在打开时,或者由于 fs-verity 而在稍后读取时),并且会在内核日志中打印详细错误。有关 fs-verity 文件访问工作原理的更多详细信息,请参阅 Documentation/filesystems/fsverity.rst。
Verity 可以用作一般的鲁棒性检查,以检测 overlayfs 中使用的目录的意外更改。但是,通过额外的注意,它也可以提供更强大的保证。例如,如果上层是完全受信任的(通过使用 dm-verity 或类似的东西),那么可以使用不受信任的下层来为所有 metacopy 文件提供经过验证的文件内容。如果另外指定了不受信任的下层目录为 "Data-only",那么它们只能提供这样的文件内容,并且整个挂载可以被信任与上层匹配。
此功能由 "verity" 挂载选项控制,支持以下值:
- "off":永远不生成或使用 metacopy 摘要。如果未指定 verity 选项,则这是默认值。
- "on":每当 metacopy 文件指定预期摘要时,相应的数据文件必须与指定的摘要匹配。在生成 metacopy 文件时,将根据源文件在其中设置 verity 摘要(如果有的话)。
- "require":与 "on" 相同,但另外所有 metacopy 文件必须指定摘要(否则在打开时返回 EIO)。这意味着只有在数据文件启用了 fs-verity 时才会使用元数据复制,否则将使用完全复制。
分享和复制层
下层可以在多个 overlay 挂载之间共享,并且这确实是一个非常常见的做法。一个 overlay 挂载可以使用与另一个 overlay 挂载相同的下层路径,也可以使用位于另一个 overlay 下层路径之上或之下的下层路径。
不允许使用已被另一个 overlay 挂载使用的上层路径和/或 workdir 路径,可能会因 EBUSY 而失败。不允许使用部分重叠的路径,可能会因 EBUSY 而失败。如果从两个共享或重叠上层路径和/或 workdir 路径的 overlayfs 挂载中访问文件,overlay 的行为是未定义的,尽管不会导致崩溃或死锁。
允许使用已被另一个挂载的 overlay 使用的上层路径进行挂载,除非启用了 "inodes index" 功能或 "metadata only copy up" 功能。
对于 "inodes index" 功能,在第一次挂载时,下层根目录的 NFS 文件句柄以及下层文件系统的 UUID 被编码并存储在上层根目录的 "trusted.overlay.origin" 扩展属性中。在后续的挂载尝试中,将比较上层根目录中存储的下层根目录文件句柄和下层文件系统 UUID 与下层根源的验证失败时,挂载将以 ESTALE 失败。启用 "inodes index" 的 overlayfs 挂载将在下层文件系统不支持 NFS 导出、下层文件系统没有有效的 UUID 或上层文件系统不支持扩展属性时以 EOPNOTSUPP 失败。
对于 "metadata only copy up" 功能,在挂载时没有验证机制。因此,如果使用不同的下层挂载相同的上层,挂载可能会成功,但稍后可能会出现意外情况。所以不要这样做。
将 overlay 层复制到同一或不同的底层文件系统上的不同目录树,甚至复制到不同的机器上,是一种常见的做法。使用 "inodes index" 功能时,尝试挂载复制的层将失败验证下层根文件句柄。
非标准行为
当前版本的 overlayfs 可以作为大部分符合 POSIX 的文件系统。
以下是 overlayfs 目前不处理的情况列表:
a) POSIX 规定对读取更新 st_atime。在文件位于下层时,目前不会执行此操作。
b) 如果位于下层的文件以只读方式打开,然后使用 MAP_SHARED 进行内存映射,那么对文件的后续更改不会反映在内存映射中。
c) 如果位于下层的文件正在执行,则打开该文件进行写入或截断文件将不会因 ETXTBSY 而被拒绝。
以下选项允许 overlayfs 更像一个符合标准的文件系统:
- "redirect_dir"
使用挂载选项或模块选项 "redirect_dir=on" 或内核配置选项 CONFIG_OVERLAY_FS_REDIRECT_DIR=y 启用。
如果禁用此功能,则对下层或合并目录的重命名将因为 EXDEV("无效的跨设备链接")而失败。
- "inode index"
使用挂载选项或模块选项 "index=on" 或内核配置选项 CONFIG_OVERLAY_FS_INDEX=y 启用。
如果禁用此功能并且复制了具有多个硬链接的文件,则这将 "破坏" 这个链接。更改将不会传播到指向相同 inode 的其他名称。
- "xino"
使用挂载选项 "xino=auto" 或 "xino=on",使用模块选项 "xino_auto=on" 或内核配置选项 CONFIG_OVERLAY_FS_XINO_AUTO=y 启用。也通过使用组成 overlay 的所有层的相同底层文件系统来隐式启用。
如果禁用此功能或底层文件系统的 inode 号没有足够的空闲位,则 overlayfs 将无法保证 stat(2) 返回的 st_ino 和 st_dev 的值以及 readdir(3) 返回的 d_ino 的值会像在正常文件系统上一样。例如,同一 overlay 文件系统中两个对象的 st_dev 的值可能不同,而文件系统对象的 st_ino 的值可能不是持久的,甚至在挂载 overlay 文件系统时也可能会发生变化,如上述 inode 属性表中总结的那样。
联合文件系统底层文件系统更改
在挂载的联合文件系统的底层文件系统发生更改时是不允许的。如果底层文件系统发生更改,联合文件系统的行为是未定义的,尽管不会导致崩溃或死锁。
允许对上层树进行离线更改,但只有在未使用"metadata only copy up"、"inode index"、"xino"和"redirect_dir"特性的情况下才允许对下层树进行离线更改。如果修改了下层树并且使用了其中任何特性,联合文件系统的行为是未定义的,尽管不会导致崩溃或死锁。
当启用联合文件系统的NFS导出功能时,底层较低层的离线更改行为与禁用NFS导出时的行为不同。
在每次复制上时,底层索引节点的NFS文件句柄以及底层文件系统的UUID会被编码并存储在上层索引节点的扩展属性"trusted.overlay.origin"中。
当启用NFS导出功能时,对于找到了下层目录的合并目录的查找,会验证查找到的下层目录文件句柄和下层文件系统的UUID是否与复制上时存储的原始文件句柄匹配。如果找到的下层目录与存储的原始目录不匹配,则该目录将不会与上层目录合并。
NFS导出
当底层文件系统支持NFS导出并启用了"nfs_export"特性时,联合文件系统可以被导出到NFS。
使用"nfs_export"特性时,在任何下层对象的复制上时,会在索引目录下创建一个索引条目。索引条目的名称是复制上原始文件句柄的十六进制表示。对于非目录对象,索引条目是指向上层索引节点的硬链接。对于目录对象,索引条目具有一个扩展属性"trusted.overlay.upper",其中包含上层目录索引节点的编码文件句柄。
在对来自联合文件系统对象的文件句柄进行编码时,遵循以下规则:
- 对于非上层对象,从下层索引节点编码一个下层文件句柄
- 对于已索引的对象,从复制上原始文件句柄编码一个下层文件句柄
- 对于纯上层对象和现有的非索引上层对象,从上层索引节点编码一个上层文件句柄
编码的联合文件句柄包括:
- 包括路径类型信息的头部(例如下层/上层)
- 底层文件系统的UUID
- 底层索引节点的底层文件系统编码
这种编码格式与存储在扩展属性"trusted.overlay.origin"中的文件句柄的编码格式相同。
解码联合文件句柄时,遵循以下步骤:
- 通过UUID和路径类型信息找到底层层
- 将底层文件系统文件句柄解码为底层目录项
- 对于下层文件句柄,在索引目录中按名称查找句柄
- 如果在索引中找到了白出,返回ESTALE。这表示一个在其文件句柄被编码后被删除的覆盖对象
- 对于非目录,从解码的底层目录项、路径类型和索引索引节点(如果找到)实例化一个断开的覆盖目录项
- 对于目录,使用连接的底层解码目录项、路径类型和索引来查找连接的覆盖目录项
解码非目录文件句柄可能会返回一个断开的目录项。对该断开的目录项进行复制上将创建一个没有上层别名的上层索引条目。
当覆盖文件系统具有多个下层时,中间层目录可能具有指向下层目录的"重定向"。因为中间层"重定向"没有被索引,所以无法使用从"重定向"原始目录编码的下层文件句柄来找到中间或上层目录。同样,无法使用从"重定向"原始目录的后代编码的下层文件句柄来重建连接的覆盖路径。为了减轻无法从下层文件句柄解码的目录的情况,这些目录在编码时被复制上,并作为上层文件句柄进行编码。在没有上层的覆盖文件系统上,这种缓解措施无法使用。在这种设置中,NFS导出需要关闭重定向跟随(例如"redirect_dir=nofollow")。
覆盖文件系统不支持非目录可连接的文件句柄,因此使用'subtree_check'导出配置进行导出将导致在NFS上查找文件时失败。
当启用NFS导出功能时,所有目录索引条目在挂载时都会进行验证,以确保上层文件句柄不是过时的。在某些情况下,这种验证可能会导致显着的开销。
注意:挂载选项index=off,nfs_export=on在读写挂载时是冲突的,会导致错误。
注意:挂载选项uuid=off可以用于将底层文件系统中的文件句柄中的UUID替换为null,并有效地禁用UUID检查。这在底层磁盘被复制且此复制的UUID已更改的情况下很有用。这仅适用于所有下层/上层/工作目录都在同一文件系统上的情况,否则将回退到正常行为。
UUID和fsid
覆盖fs实例本身的UUID和statfs(2)报告的fsid由"uuid"挂载选项控制,支持以下值:
- "null":覆盖fs的UUID为null。fsid取自最上层文件系统。
- "off":覆盖fs的UUID为null。fsid取自最上层文件系统。忽略底层层的UUID。
- "on":生成覆盖fs的UUID并用于报告唯一的fsid。UUID存储在xattr "trusted.overlay.uuid"中,使覆盖fs的fsid唯一且持久。此选项需要支持xattr的上层文件系统的覆盖fs。
- "auto":(默认)如果存在xattr "trusted.overlay.uuid",则从中获取UUID。对于首次挂载满足先决条件的新覆盖文件系统,升级为"uuid=on"。对于以前从未使用"uuid=on"挂载的现有覆盖文件系统,降级为"uuid=null"。
临时挂载
这是通过"volatile"挂载选项启用的。临时挂载不能保证在崩溃后能够恢复。强烈建议只在可以轻松重建覆盖内容的情况下使用临时挂载。
使用"volatile"选项挂载的优点是省略了对上层文件系统的所有同步调用。
为了避免给出错误的安全感,临时挂载的syncfs(和fsync)语义与VFS的其余部分略有不同。如果在临时挂载后发生了上层目录文件系统的任何写回错误,所有同步函数都将返回错误。一旦达到这种情况,文件系统将无法恢复,每次后续的同步调用都将返回错误,即使自上次同步调用以来上层目录没有发生新的错误。
当使用"volatile"选项挂载覆盖时,将创建目录"$workdir/work/incompat/volatile"。在下一次挂载期间,覆盖将检查此目录,如果存在则拒绝挂载。这是一个强烈的指示,用户应该丢弃上层和工作目录并创建新的目录。在非常有限的情况下,用户知道系统没有崩溃且上层目录的内容完好无损时,可以删除"volatile"目录。
用户xattr
"-o userxattr"挂载选项强制覆盖fs使用"user.overlay." xattr命名空间,而不是"trusted.overlay."。这对于非特权挂载覆盖fs很有用。
测试套件
最初由David Howells开发,目前由Amir Goldstein维护的测试套件位于:
https://github.com/amir73il/unionmount-testsuite.git
以root身份运行:
# cd unionmount-testsuite
# ./run --ov --verify