原文:PARALLEL-DATA-FREE VOICE CONVERSION USING CYCLE-CONSISTENT ADVERSARIAL NETWORKS
地址:https://arxiv.org/pdf/1711.11293v2.pdf
摘要:
我们提出了一种无需平行数据的语音转换(VC)方法,可以在不依赖平行数据的情况下从源语音学习到目标语音的映射。该方法具有通用性、高质量且无需平行数据,无需额外的数据、模块或对齐过程。与许多传统的基于统计模型的VC方法相比,它还避免了过度平滑的问题。我们的方法被称为CycleGAN-VC,它使用了循环一致对抗网络(CycleGAN)和门控卷积神经网络(CNNs),并采用了身份映射损失。CycleGAN同时使用对抗性和循环一致性损失来学习前向和逆向映射,这使得我们可以从非配对的数据中找到最优的伪配对。此外,对抗性损失有助于减少转换特征序列的过度平滑。我们配置了一个带有门控CNN的CycleGAN,并使用身份映射损失进行训练。这样可以使映射函数捕捉到时序和层次结构,同时保留语言信息。我们对无需平行数据的VC任务进行了评估。客观评估显示,转换的特征序列在全局方差和调制谱方面与自然语音接近。主观评估表明,在有利条件下,转换后的语音质量与基于高斯混合模型的方法相当,并且数据量为平行数据的两倍。
引言
语音转换(Voice conversion,VC)是一种在保留语言信息的同时修改语音的非语言/语音外信息的技术。这种技术可应用于多种任务,例如用于文本转语音(TTS)系统的说话人身份修改[1],言语辅助[2, 3],语音增强[4, 5, 6]以及发音转换[7]。
语音转换可以被看作是一个回归问题,即从源语音到目标语音的映射函数估计。其中一种成功的方法涉及使用高斯混合模型(Gaussian mixture model,GMM)的统计方法[8, 9, 10]。神经网络(Neural network,NN)为基础的方法,例如受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)[11, 12],前馈神经网络(Feed Forward NN)[13, 14],循环神经网络(Recurrent NN,RNN)[15, 16]和卷积神经网络(Convolutional NN,CNN)[7],以及基于示例的方法,如非负矩阵分解(Non-negative matrix factorization,NMF)[17, 18],也在近期被提出。
许多语音转换方法,包括上述提到的方法,通常使用源语音和目标语音的时间对齐平行数据作为训练数据。如果有完美对齐的平行数据可用,获得映射函数就相对简单;然而,在真实应用场景中收集这样的数据可能是一个费时费力的过程。即使我们能够收集这样的数据,我们仍需要执行自动时间对齐,这可能偶尔会失败。这可能是个问题,因为平行数据中的不正确对齐可能会导致语音质量下降;因此,可能需要进行仔细的预筛选和手动纠正[19]。
这些事实激发了我们考虑一个无需平行数据的语音转换问题。在本文中,我们提出了一种无需平行数据的语音转换方法,特别值得注意的是:(1)它不需要任何额外的数据,比如转录文本和参考语音,也不需要额外的模块,如自动语音识别(Automatic Speech Recognition,ASR)模块;(2)它不容易出现过度平滑现象,这是导致语音质量降低的主要因素之一;(3)它能够在没有任何对齐过程的情况下捕捉频谱时域结构。
为了满足这些要求,我们的方法被称为CycleGAN-VC,它使用循环一致性对抗网络(CycleGAN)[20](即DiscoGAN [21]或DualGAN [22])与门控卷积神经网络(Gated CNNs)[23]和恒等映射损失(Identity-mapping loss)[24]。
CycleGAN最初是为无配对图像转换而提出的。借助该模型,通过使用对抗性损失[25]和循环一致性损失[26]同时学习正向和逆向映射。这使得从无配对数据中找到最优伪配对成为可能。此外,对抗性损失不需要显式密度估计,并导致减少过度平滑效应[7, 27, 28, 29]。为了将CycleGAN用于无需平行数据的语音转换,我们配置了一个使用门控卷积神经网络的网络,并使用恒等映射损失对其进行训练。这使得映射函数能够捕捉顺序和层次结构,并保留语言信息。
我们在使用Voice Conversion Challenge 2016(VCC 2016)数据集[30]进行无需平行数据的语音转换任务的情况下对我们的方法进行了评估。客观评估结果显示,转换后的特征序列在全局方差(Global Variance,GV)[9]和调制谱(Modulation Spectra,MS)[31]方面表现相当不错。主观评估显示,语音质量与使用基于GMM的方法[9]相当,而该方法使用了平行数据以及两倍的数据量。这一点值得注意,因为我们的方法在训练条件下有一个劣势。
相关工作
近年来,已经提出了几种无需平行数据的语音转换方法。其中一种方法涉及使用ASR模块来找到对应帧的一对[32, 33]。如果ASR表现稳健且准确,这可能效果不错,但是需要大量的转录文本来训练ASR模块。同时,这种方法本质上很难捕捉非语言信息,这可能成为在一般情况下应用的限制。
另一种方法涉及使用自适应技术[34, 35]或将预构建的说话人空间[36, 37]纳入方法中。这些方法不需要源说话人和目标说话人之间的平行数据,但需要参考说话人之间的平行数据。最近也有一些尝试[38, 39, 40, 41]来开发完全不需要平行数据和额外模块的方法。使用这些方法,假设源语音和目标语音处于相同的低维嵌入空间。这不仅会限制应用领域,还会导致对复杂结构的建模困难,例如详细的频谱时域结构。相比之下,我们直接学习映射函数而不是进行嵌入。我们期望这将使我们的方法能够应用于各种需要考虑复杂结构建模的应用场景。
CycleGAN简介:
我们的目标是学习从源语音 x ∈ X 到目标语音 y ∈ Y 的映射,而不依赖于平行数据。我们基于CycleGAN[20]来解决这个问题。在这一小节中,我们简要回顾CycleGAN的概念,并在接下来的小节中解释我们提出的无需平行数据的语音转换方法。
CycleGAN使用两种损失函数来学习一个从源域到目标域的映射 GX→Y。这两种损失函数分别是对抗性损失[25]和循环一致性损失[26]。我们在图1中展示了训练过程。
对抗性损失:对抗性损失衡量了转换后的数据 GX→Y (x) 和目标数据 y 之间的区别。因此,转换后的数据 GX→Y (x) 的分布越接近目标数据 y 的分布 PData(y),这个损失就越小。对抗性损失的目标函数表示为:
Ladv(GX→Y , DY ) = Ey∼PData(y) [log DY (y)] +Ex∼PData(x) [log(1 − DY (GX→Y (x)))]. (1)
生成器 GX→Y 试图通过最小化此损失来生成与目标数据 y 无法区分的数据,而判别器 DY 试图通过最大化此损失来区分生成器 GX→Y 生成的数据与真实目标数据 y。
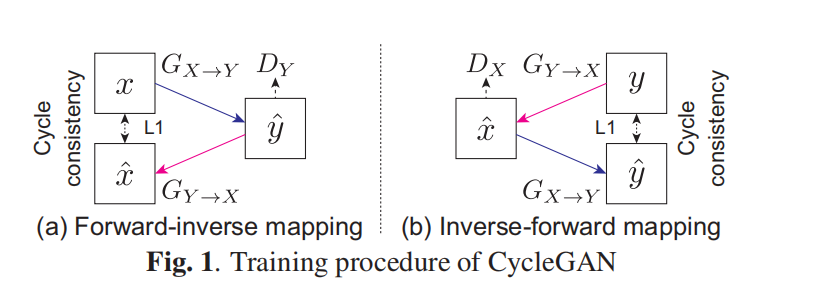
循环一致性损失:
仅优化对抗性损失并不一定能保证 x 和 GX→Y (x) 的上下文信息是一致的。这是因为对抗性损失只告诉我们 GX→Y (x) 是否遵循目标数据分布,并不能帮助保留 x 的上下文信息。CycleGAN[20]的思想是引入两个额外的项。一个是逆向映射 GY →X 的对抗性损失 Ladv(GY →X, DX),另一个是循环一致性损失,表示为:
Lcyc(GX→Y , GY →X) = Ex∼PData(x) [||GY →X (GX→Y (x)) − x||1] + Ey∼PData(y) [||GX→Y (GY →X(y)) − y||1]. (2)
这些额外的项鼓励 GX→Y 和 GY →X 找到具有相同上下文信息的 (x, y) 对。
完整的目标函数可以用权衡参数 λcyc 表示为:
Lfull = Ladv(GX→Y , DY ) + Ladv(GY →X, DX) + λcycLcyc(GX→Y , GY →X)。
通过优化上述目标函数,我们可以使生成器 GX→Y 和 GY →X 同时学习正向映射和逆向映射,并且保持上下文信息的一致性。这样一来,我们可以实现无需平行数据的语音转换。
CycleGAN用于无需平行数据的语音转换:
CycleGAN-VC 为了将CycleGAN用于无需平行数据的语音转换,我们主要对CycleGAN架构进行了两个修改:门控卷积神经网络(gated CNN)[23]和恒等映射损失(identity-mapping loss)[24]。
门控卷积神经网络:语音的一个特点是具有顺序和层次结构,例如声音/无声段和音素/形态素。表示这种结构的有效方法是使用循环神经网络(RNN),但由于难以进行并行实现,其计算成本较高。因此,我们使用门控卷积神经网络[23]来配置CycleGAN,这不仅允许在顺序数据上进行并行计算,而且在语言建模[23]和语音建模[7]方面取得了最新的成果。
在门控卷积神经网络中,使用门控线性单元(gated linear units,GLUs)作为激活函数。GLU是一种数据驱动的激活函数,第(l+1)层的输出Hl+1通过第l层的输出Hl和模型参数Wl、Vl、bl、cl计算得到,公式如下:
Hl+1 = (Hl ∗ Wl + bl) ⊗ σ(Hl ∗ Vl + cl),
其中, ⊗ 表示逐元素乘积,σ 是sigmoid函数。这种门控机制允许信息根据前一层的状态进行选择性传播。在门控线性单元中,sigmoid函数决定哪些信息被传递,而逐元素乘积则用于控制信息的放大或抑制。这样的机制使得网络能够更有效地学习顺序和层次结构,有助于在语音转换中保留重要的上下文信息。
恒等映射损失:循环一致性损失对结构提供了约束;然而,它并不足以保证映射始终保留语言信息。为了鼓励语言信息的保留,而无需依赖额外的模块,我们引入了恒等映射损失[24]:
Lid(GX→Y , GY →X) = Ey∼PData(y) [||GX→Y (y) − y||1] + Ex∼PData(x) [||GY →X(x) − x||1],
恒等映射损失鼓励生成器 GX→Y 和 GY →X 在转换过程中尽可能地保持原有的语言信息。该损失函数使得生成器试图在转换过程中尽量保持源语音 x 和目标语音 y 的一致性,从而减少在转换过程中可能引入的信息损失。这有助于提高语音转换的质量和可靠性,使得我们的方法能够在无需平行数据的情况下保持语言信息的一致性。
恒等映射损失鼓励生成器寻找保持输入和输出之间组合性的映射。在实践中,我们使用带有权衡参数 λid 的加权损失 Lid 添加到公式 3 中。值得注意的是,CycleGAN的原始研究[20]证明了这种损失在颜色保持方面的有效性。
通过使用恒等映射损失,我们鼓励生成器 GX→Y 和 GY →X 在转换过程中尽量保持原始的语音信息,这使得生成的输出语音与输入语音在语义上相对应。这有助于提高语音转换的质量和可靠性,并避免在转换过程中引入不必要的失真。因此,我们在实际训练中使用带有权衡参数 λid 的恒等映射损失,以进一步优化我们的模型。

图. 生成器和判别器的网络架构。在输入或输出层,h、w和c分别表示高度、宽度和通道数。在每个卷积层中,k、c和s分别表示核大小、通道数和步幅大小。由于生成器是完全卷积的[42],因此它可以接受任意长度T的输入。
实验
4.1. 实验条件
我们进行了实验,评估了我们的无需平行数据的语音转换方法。我们使用了VCC 2016数据集[30],该数据集由专业美国英语发音人录制,包括5位女性和5位男性。我们按照之前的研究[39],选取了一部分发音人进行评估。其中,一对女性(SF1)和男性(SM1)被选为源,另一对女性(TF2)和男性(TM3)被选为目标。每位发音人的音频文件被手动分割成216个短句(约13分钟)。其中,162个句子用于训练集,54个句子用于评估集。为了在无需平行数据的条件下评估我们的方法,我们将训练集分为两个没有重叠的子集。对于第一个子集,81个句子用于源,另外81个句子用于目标。语音数据被下采样到16 kHz,然后使用WORLD分析系统[43]每5毫秒提取24个梅尔倒谱系数(Mel-cepstral coefficients,MCEPs)、对数基频(log F0)和非周期性(aperiodicities,APs)。在这些特征中,我们使用我们的方法在MCEP域中学习了映射。基频使用对数高斯归一化转换[44]进行转换。非周期性则直接使用,因为之前的研究[45]表明,转换APs对语音质量影响不大。
实现细节:
我们设计了一个基于图像建模[20, 46, 47]和语音建模[7, 27]方面的最新成功的网络。网络架构如图2所示。我们设计了生成器,使用一维卷积神经网络(1D CNN)[7]来捕捉整体特征之间的关系,同时保留时间结构。受之前神经风格迁移和超分辨率研究的启发[47],我们使用包含下采样、残差[48]、上采样层以及实例标准化[49]的网络。我们使用像素洗牌器(pixel shuffler)进行上采样,这对高分辨率图像生成[46]非常有效。我们设计了判别器,使用二维卷积神经网络(2D CNN)[7],专注于2D频谱纹理[27]。
训练细节:
作为预处理,我们对源和目标MCEPs进行了每个维度的归一化处理。为了稳定训练,我们使用了最小二乘GAN(least squares GAN)[50],它将Ladv中的负对数似然目标替换为最小二乘损失。我们设置λcyc = 10。在前104次迭代中,我们只使用Lid,其中λid = 5,以引导学习过程。为了增加每个批次的随机性,我们没有直接使用整个序列,而是随机从随机选择的音频文件中裁剪了一个固定长度的段(128帧)。我们使用批大小为1来训练网络。生成器的初始学习率设置为0.0002,判别器的初始学习率设置为0.0001。在前2×105次迭代中,保持相同的学习率,并在接下来的2×105次迭代中线性衰减。动量项β1设置为0.5。
客观评估
在这些实验中,我们专注于MCEP的转换,因此我们评估了转换后MCEP的质量。我们将我们的方法(CycleGAN-VC)与基于GMM的方法(GMM-VC)[9]进行了比较,因为在相对较小的数据集[52]中,这种方法仍然可以与基于DNN的方法相媲美。由于这种方法需要平行数据,因此源和目标的所有训练数据(162个句子)都被使用。这意味着训练数据的量是我们的两倍。作为消融研究,我们检查了我们的方法,没有使用任何GLUs。我们使用了典型的GAN激活函数,即修正线性单元(ReLU)[53],用于生成器,而对于判别器,我们使用了Leaky ReLU [54, 55]。
在预实验中,我们还检查了我们的方法没有恒等映射损失的情况。结果显示,缺乏这个损失会导致显著的降低,例如语言结构的崩溃;因此,我们没有进一步研究这一点。
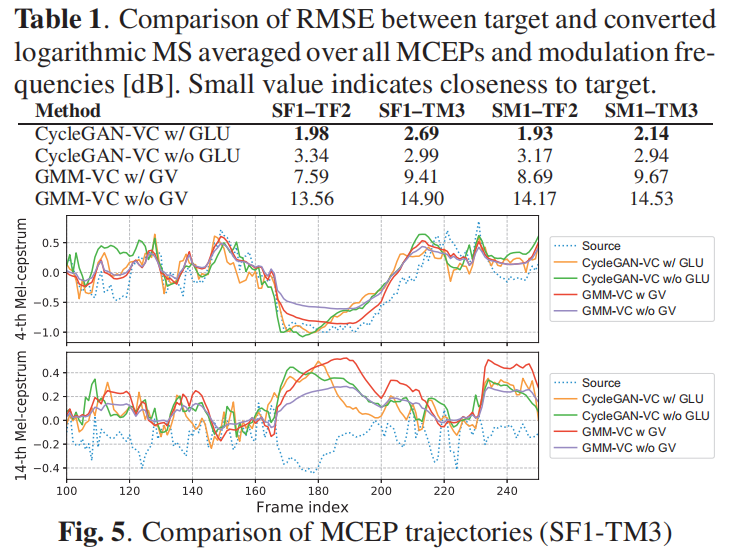
表格1. 目标和转换后对数调制谱(logarithmic MS)在所有MCEPs和调制频率[dB]上的均方根误差(RMSE)比较。较小的值表示与目标的接近程度。
梅尔倒谱失真是一种常用的评估合成MCEP质量的指标,但是最近的研究[9, 27, 41]指出了这种指标的局限性:它倾向于偏好过度平滑,因为它内部假设了高斯分布。因此,我们使用了两个与主观评估高度相关的结构性指标作为替代:GV [9]和MS [31]。我们在图3中展示了GV的比较。我们在表格1中列出了目标和转换后对数调制谱的均方根误差(RMSE)的比较。我们还在图4中展示了每个调制频率的MS比较。这些结果表明,我们的方法(CycleGAN-VC w/ GLU)获得的MCEP序列在GV和MS方面与目标最接近。这是因为(1)对抗性损失不需要明确的密度估计,因此避免了过度平滑,以及(2)GLU是一种数据驱动的激活函数,因此它能够更好地表示顺序和层次结构,比ReLU和leaky ReLU更好。我们在图5中展示了样本MCEP轨迹。CycleGAN-VC w/ GLU的轨迹在全局结构上与GMM-VC w/ GV类似,同时保留了与源相似的复杂性。
主观评估
我们进行了听觉测试,以评估转换后语音的性能。参考了VCC 2016 [56],我们评估了转换样本的自然度和说话人相似性。我们将我们的方法与VCC 2016的基准线进行比较,该基准线是一个使用平行数据和两倍于我们数据量的基于GMM的方法[9]。为了测量自然度,我们进行了平均意见分数(MOS)测试。作为参考,我们使用目标说话人的原始和合成分析(我们方法的上限)语音。我们随机选择了来自评估集的20个长度在2秒到5秒之间的句子。为了测量说话人相似性,我们采用了相同/不同的范式[56]。我们从评估集中随机选择了10个样本对。共有九名接受过良好教育的英语母语者参与了评估。参考[41]的研究,我们在两个子集上进行了评估:同性别VC(SF1-TF2)和异性别VC(SF1-TM3)。
我们在图6中展示了自然度的MOS。结果表明,我们的方法显著优于基准线。我们在图7中展示了与源说话人和目标说话人的相似性。结果表明,在SF1-TM3 VC方面,我们的方法略逊于基准线,但在SF1-TF2 VC方面优于基准线。总体而言,我们的方法与基准线相媲美。这是值得注意的,因为我们的方法在劣势条件下进行训练,只使用了一半的数据量和非平行数据。
讨论与结论
我们提出了一种无需平行数据的语音转换(VC)方法,称为CycleGAN-VC。该方法使用了CycleGAN和门控卷积神经网络(CNN),以及一个恒等映射损失。这种方法可以学习一个基于序列的映射函数,而无需额外的数据、模块或时间对齐过程。客观评估显示,使用我们的方法得到的MCEP序列在GV和MS方面与目标接近。主观评估显示,在有平行数据和两倍训练数据的优势条件下,转换后的语音质量与基于高斯混合模型(GMM)的方法相当。然而,原始语音与转换后的语音之间仍然存在一定差距。
为了弥合这个差距,我们计划将我们的方法应用于其他特征,比如STFT频谱图[28],以及其他语音合成框架,如无声码器的VC[57]。此外,我们的提议方法是一个通用框架,未来可能的研究方向包括将该方法应用于其他VC应用领域[1, 2, 3, 4, 5, 6, 7]。