Java中有哪些集合
Java中的集合可以分为4类,使用4个接口代表,分别是List Set Queue Map。其中List Set Queue都继承自Collection。
List:是有序可重复集合,元素可为空,常用的有ArrayList LinkedList
Set: 无序不可重复集合 元素可为空,常用的有HashSet TreeSet
Queue: 先进先出的队列,常用的有ArrayDeque
Map:键值映射关系,键值可为空,常用的有HashMap TreeMap HashTable
DNS(域名系统)是什么
DNS域名系统是将域名和IP相互映射的分布式数据库服务,可以通过域名查到对应的IP,让用户可以更好的记住地址
http超文本传输协议是什么
http超文本传输协议是运行在tcp之上的一种协议,基于请求响应模型的无状态协议,规定了一次请求和一次响应的格式
判断mysql中索引是否生效
使用explain关键字,语法是explain select * from t where ...
返回结果如下图

如果possible_keys行和key行都包含了某个索引,则说明在查询时使用了该索引。
- possible_keys列给出了MySQL在搜索数据记录时可选用的各个索引。
- key列是MySQL实际选用的索引。
Sql列转行
- A.使用max(case when)
SELECT name as '姓名',
MAX(CASE WHEN course = '语文' THEN score END) AS '语文',
MAX(CASE WHEN course = '数学' THEN score END) AS '数学',
MAX(CASE WHEN course = '英语' THEN score END) AS '英语',
MAX(CASE WHEN course = '历史' THEN score END) AS '历史'
FROM t_student
GROUP BY name; - B.使用sum(if(条件,列,为空替换值))
SELECT name as '姓名',
SUM(IF(course = '语文',score,0)) AS '语文',
SUM(IF(course = '数学',score,0)) AS '数学',
SUM(IF(course = '英语',score,0)) AS '英语',
SUM(IF(course = '历史',score,0)) AS '历史'
FROM t_student
GROUP BY name;
数据库事务
- 事务的特点
原子性:事务是一个逻辑单位,处于同一事务的操作要么都成功,要么都失败
一致性:执行结果必须是从一个正确的状态变成另外一个正确的状态,实现一种可以预期的结果。
隔离性:事务之间是独立的,不能相互影响
持续性:事务一旦提交,对数据库的状态改变是永久的,后续的操作对其执行结果不应该有影响。 - 事务的隔离级别
读未提交:事务可以读取别的事务没有提交的数据,可能出现脏读
读已提交:事务只能读取别的事务已经提交的数据,可能出现幻读、不可重复度等情况
可重复读:mysql默认的隔离级别,事务开启后不允许别的事务对数据进行update
序列化读:数据库最高隔离级别,事务只能一个个排队执行,效率差 - 分布式事务的解决方案
可以加全局锁,保证即时性比较高的业务,也可以通过消息机制进行事务补偿,保证最终一致性
什么是数据库回表操作
非主键索引树上存储的是索引值和与其对应的主键值,通过非主键索引查询会先在非主键索引树上查询出主键值,然后再到主键索引树上查询完整的记录,这个过程叫做回表;
若查询的结果在非主键索引树上都有则直接返回结果,不会进行回表。例如:select id from table where index=’i’
什么是索引下推
Mysql5.6版本有索引下推
将部分服务层负责的事情交给存擎处层理,减少回表操作。
索引规则是最左匹配原则
5.6之前:
存储引擎读取索引记录,联合索引使用最左匹配原则筛选一次,获取主键值
根据主键值定位完整记录(回表)
将记录返给server层进行条件筛选
5.6之后:
存储引擎读取索引记录,
判断条件部分能否使用索引列检查,否则处理下一个索引记录,是则定位完整记录
将记录返给server层进行条件筛选
redis数据类型
string:字符串基本数据类型,每个value最多存储512M
list:集合
set:元素不可重复集合
zset:与set一样都是元素不可重复,但是关联了一个评分score,根据score升序排序
hash:键值对集合
redis持久化
Redis支持RDB(快照)和AOF(指令追加)两种方式持久化
- RDB:在Redis.conf中默认使用RDB持久化机制,生产dump.rdb二进制文件
save 900 1
save 300 10
save 60 10000
以上配置标识900s内至少1个key的值变更,则持久化一次
300s内至少10个key的值变更,持久化一次
...... - AOF:redis.conf中默认关闭,开启方法是将如下配置的no改成yes
appendonly no
appendfilename "appendonly.aof" #指定文件名,不可更改
AOF开启后将生成appendonly.aof文件,该文件记录了redis所有操作指令,当文件体积达到一定程度后将触发重写机制
AOF有三种同步策略配置如下
appendfsync always 每个指令同步一次,执行速度慢
appendfsync everysec 每秒同步一次,最差只丢失1S内数据(推荐)
appendfsync no 从不同步,不安全
redis主从模式和哨兵模式
1.主从模式解决的问题
应对频繁的读操作,实现读写分离,提高性能
提高服务的安全性,和健壮性,从服务作为主服务的灾备
2.哨兵模式解决的问题
在主从的基础上,增加哨兵监控,实现主从自动切换,避免了人工干预
原理:一般需要奇数个节点,哨兵不存储数据,会想主从机器发送ping命令监控服务状态。若某个哨兵发现主服务宕机,则该哨兵会进行主管线下,直到其他哨兵发现问题后投票进行客观下线,并选出设置优先级数量小(0除外)的从机切换为主机
redis分布式锁
获取锁失败后有三种处理方式
1.循环:可以结合程序内循环加队列的方式处理,现在程序内根据程序需要定义循环次数,都失败后放到等待队列中,避免业务中断
2.丢弃:根据业务需要,判断丢弃后是否有影响
3.阻塞:需要注意避免造成死锁
spring mvc参数传递
- 不使用注解

url:支持
form:支持
json:不支持,但不报错 - @RequestParam注解,只能修饰单一参数

url:支持
form:支持
json:不支持,报错 '' is not present - @PathVariable注解,将参数作为地址的一部分
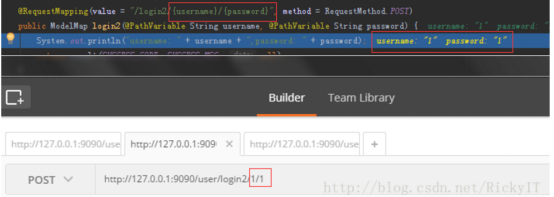
- @RequestBody注解,只适合json格式数据传参
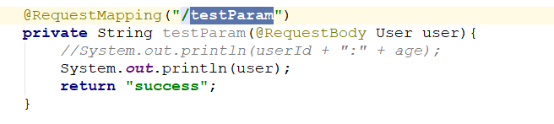
url:不支持
form:不支持
json:支持
springboot自动配置原理
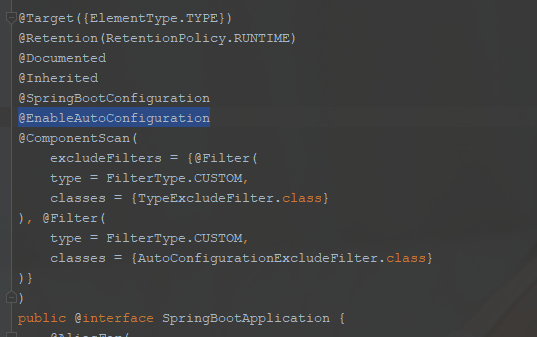
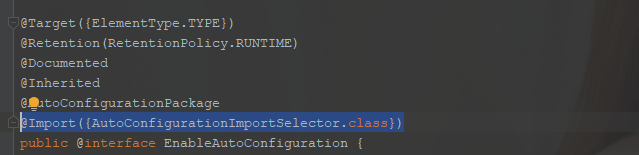
启动类上注解@SpringBootApplication的修饰注解中有@EnableAutoConfiguration,这个注解中使用@Import注解加载了AutoConfigurationImportSelector,主要实现方法为getCandidateConfigurations,该方法被selectImports()调用,启动时在run方法的refreshContext方法中调用,目的是从jar包的META-INF/spring.factories中获取配置类集合
线程池任务调度流程
1.任务提交到线程池
2.判断是否达到核心线程数,未达到则新建一条线程执行任务
3.达到核心线程数,判断阻塞队列是否满了,未满则放入阻塞队列,等待工作线程执行完后从队列的开头获取任务执行
4.队列满了,判断是否达到最大线程树,未达到则新建一个非核心线程立即执行任务
5.达到最大线程数,执行拒绝策略
线程池核心参数
- corePoolSize: 核心线程数,线程池维护最小线程数量,受到allowCoreThreadTimeOut配置影响
- maxinumPoolSize:最大线程数,线程池可维护的最大线程数量,非核心线程受到keepAliveTime配置影响
- keepAliveTime:非核心空闲线程最大存活时间,达到该设置值后会自动销毁
- ThreadFactory: 线程工厂,创建线程并设置线程属性,比如线程名称,是否守护线程等
- workQueue: 任务队列
ArrayBlockingQueue: 有界数组阻塞队列,必须初始化大小
LinkedBlockingQueue:无界链表阻塞队列,不用初始化大小
SynchronousQueue: 无缓存阻塞队列;不会保存提交的任务,会一直创建新线程执行任务,触发最大线程数就执行拒绝策略
PriorityBlockingQueue:无界有优先级阻塞队列;优先级通过参数Comparator实现
DelayQueue:无界延迟阻塞队列;底层通过PriorityBlockingQueue实现,等任务达到过期时间,才会出队 - rejectedExecutionHandler:拒绝策略;队列满了,并且触发最大线程数时执行
AbortPolicy:丢弃任务并抛出RejectedExecutionException异常
DiscardPolicy:丢弃任务但是不跑出异常
DiscardOldestPolicy:丢弃任务队列最早的任务,把当前任务放入队尾
CallerRunsPolicy:由提交任务的线程处理该任务,若线程池已shutdown则直接丢弃
mybatis中如何避免SQL注入
在mybatis中使用#{}的方式替代${}的方式接收参数,可以避免SQL注入,因为#{}使用的是预编译,会先替换为“?”然后再set值,而${}是字符串替换,在处理时是直接替换为变量的值。
mybatis中mapper的工作原理,参数不同时方法能不能重载
Dao也就是mapper接口,接口的权限定名,关联mybatis的namespace,然后接口中的方法名称与xml中的id映射。调用接口方法时,全限定名+方法名拼接为一个key,定位一个唯一的MapperStatement,在xml中每个sql标签会被解析成一个MapperStatement对象。
mapper中的方法不能重载,根据上述所说,每个MapperStatement的定义是全限定名+方法名拼接的key
mybatis分页原理,分页插件原理
Mybatis 使用 RowBounds 对象进行分页,它是针对 ResultSet 结果集执行的内存分页,而非物理分页。可以在 sql 内直接书写带有物理分页的参数来完成物理分页功能,也可以使用分页插件来完成物理分页。
分页插件的基本原理是使用 Mybatis 提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的 sql,然后重写 sql,根据 dialect 方言,添加对应的物理分页语句和物理分页参数。
mybatis将结果集转成目标对象的映射方式
- 使用标签将字段和对象属性对应
- 使用sql别名,与对象属性对应
mybatis的缓存机制
mybatis的一级缓存和二级缓存默认都是基于PerpetualCache 的 HashMap 本地缓存,不同的是一级缓存默认开启,并且是session级别的,当session关闭后所有的cache都会清空,而二级缓存是namespaces级别的默认关闭,且可以自定义存储源,若开启二级缓存,使用到的类需要实现Serializable 序列化接口
对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了 C/U/D 操作后,默认该作用域下所有 select 中的缓存将被 clear