MLIR矩阵乘算法,新建Dialect,lowering
MLIR:新建一个Dialect,lowering
Multi-Level Intermediate Representation(MLIR)是创建可重用、可扩展编译器基础设施的新途径。
MLIR 项目的核心是 Dialect,MLIR 自身就拥有例如linalg,tosa,affine 这些 Dialect。各种不同的 Dialect 使不同类型的优化或转换得以完成。
好了,如果说前面的部分算是 MLIR 的坡道起步,那这一节就要开始弹射起飞了。本期开始讲解 Dialect 的 Lowering,即由 MLIR 代码逐级转换为机器代码的过程。
当然了,前期也提到过,MLIR 生态的目标只在中间阶段,所以其 lowering 本质上并不涉及太多最终的 IR 生成,这一部分更依赖 LLVM 的基石。
内容较多,建议收藏、细品。
1复习
工具链、总览等等知识请自行翻看历史 MLIR 标签的相关文章
mlir-hello[1] 项目的目标就是使用自建的 Dialect 通过 MLIR 生态实现一个 hello world,具体做法为:
创建hello-opt 将原始 print.mlir (可以理解成 hello world 的 main.cpp)转换为 print.ll 文件使用 LLVM 的 lli 解释器直接运行
print.ll 文件
前文主要介绍了如何通过 ODS[2] 实现新的 Dialect/Op 的定义。
2Lowering
MLIR 看似清爽,但相关 Pass 的实现一样工作量巨大。
在定义和编写了 HelloDialect 的方方面面后,最终还是要使它们回归 LLVM MLIR “标准库” Dialect,从而再做面向硬件的代码生成。因为标准库中的 Dialect 的剩余工作可以“无痛”衔接到 LLVM 的基础组件上。
具体到 mlir-hello,HelloDialect 到 LLVM 标准库 Dialect,例如 affine dialect,llvm dialect 的 lowering 将手工编码完成。
这一部分可能是 MLIR 相关任务工作量最大的地方。
这一篇文章作为 lowering 相关内容的开端,来解读如何通过 C++ 实现 HelloDialect 到 affine dialect 的 lowering。
相关文件如下:
mlir-hello/include/Hello/HelloDialect.h,主要内容通过前期讲过的 ODS 自动生成,略mlir-hello/include/Hello/HelloOps.h,主要内容通过前期讲过的 ODS 自动生成,略mlir-hello/include/Hello/HelloPasses.h,注册本不存在的 lowering pass,比如 Hello 到 Affine 的 passmlir-hello/lib/Hello/LowerToAffine.cpp,lowering pass 的实现
3代码解读
简单讲,Dialect 到 Dialect 是一个 match and rewrite 的过程。
注意,有一个之前介绍过的、在 MLIR 中被大量应用的 C++ 编程技巧可能需要巩固一下:C++:CRTP,传入继承。
Pass registration
mlir-hello/include/Hello/HelloPasses.h
通过 std::unique_ptr<mlir::Pass> 在 MLIR 中注册两条 lowering pass。
注册的这个函数钩子将会在下一节的 cpp 中得到具体的实现的函数。
// mlir-hello/include/Hello/HelloPasses.h
//该文件在MLIR中注册两条lowering pass,没啥特别的
#ifndef MLIR_HELLO_PASSES_H
#define MLIR_HELLO_PASSES_H
#include <memory>
#include "mlir/Pass/Pass.h"
namespacehello {
std::unique_ptr<mlir::Pass>createLowerToAffinePass();
std::unique_ptr<mlir::Pass>createLowerToLLVMPass();
}
#endif // MLIR_HELLO_PASSES_H
Lowering implementation
mlir-hello/lib/Hello/LowerToAffine.cpp
负责 hello 到 affine 的 lowering 实现,本质上分为各 Op lowering 的前置工作和Dialect to Dialect实现两个部分。最终的实现 createLowerToAffinePass 将作为 Pass 注册时函数钩子的返回。
1. Op lowering
例如对于某 Xxx 算子,共性为
定义为class XxxOpLowering
继承自
mlir::OpRewritePattern<hello::XxxOp>
重载
matchAndRewrite 函数,做具体实现
XxxOpLowering 最终将作为模板参数传入新 pass 的 mlir::RewritePatternSet<XxxOpLowering>
例如 class ConstantOpLowering 的实现如下:它会将 ConstantOp 所携带的信息最终转储到 mlir::AffineStoreOp 中。
classConstantOpLowering:publicmlir::OpRewritePattern<hello::ConstantOp> {
usingOpRewritePattern<hello::ConstantOp>::OpRewritePattern;
mlir::LogicalResultmatchAndRewrite(hello::ConstantOp op, mlir::PatternRewriter &rewriter)constfinal{
//捕获ConstantOp的元信息:值、位置
mlir::DenseElementsAttr constantValue = op.getValue();
mlir::Location loc = op.getLoc();
// lowering时,需要将constant的参数转存为memref
autotensorType = op.getType().cast<mlir::TensorType>();
automemRefType = convertTensorToMemRef(tensorType);
autoalloc = insertAllocAndDealloc(memRefType, loc, rewriter);
//预先声明一个“最高维”的变量
autovalueShape = memRefType.getShape();
mlir::SmallVector<mlir::Value, 8> constantIndices;
if(!valueShape.empty()) {
for(autoi : llvm::seq<int64_t>(
0, *std::max_element(valueShape.begin(), valueShape.end())))
constantIndices.push_back(rewriter.create<mlir::arith::ConstantIndexOp>(loc, i));
}else{
// rank为0时
constantIndices.push_back(rewriter.create<mlir::arith::ConstantIndexOp>(loc, 0));
}
// ConstantOp将作为一个“多维常量”被使用,它可能包含下面这些隐含信息(结构、值),
// [4, 3] (1, 2, 3, 4, 5, 6, 7, 8)
// storeElements(0)
// indices = [0]
// storeElements(1)
// indices = [0, 0]
// storeElements(2)
// store (const 1) [0, 0]
// indices = [0]
// indices = [0, 1]
// storeElements(2)
// store (const 2) [0, 1]
// ...
//于是,可以通过定义一个递归functor(中文一般译为仿函数)去捕获这些信息。
// functor的基本思路为,从第一个维度开始,向第2,3,...个维度递归取回每个维度上的元素。
mlir::SmallVector<mlir::Value, 2> indices;
autovalueIt = constantValue.getValues<mlir::FloatAttr>().begin();
std::function<void(uint64_t)> storeElements = [&](uint64_tdimension"&") {
//递归边界情况:到了最后一维,直接存下整组值
if(dimension == valueShape.size()) {
rewriter.create<mlir::AffineStoreOp>(
loc, rewriter.create<mlir::arith::ConstantOp>(loc, *valueIt++), alloc,
llvm::makeArrayRef(indices));
return;
}
//未到递归边界:在当前维度上挨个儿递归,存储结构信息
for(uint64_ti = 0, e = valueShape[dimension]; i != e; ++i) {
indices.push_back(constantIndices[i]);
storeElements(dimension + 1);
indices.pop_back();
}
};
//使用上面的functor
storeElements(/*dimension=*/0);
//将insertAllocAndDealloc替换为当前op
rewriter.replaceOp(op, alloc);
returnmlir::success();
}
};
2. Dialect to Dialect
定义好 op 的 lowering 后,就可以通过点对点的 lowering pass 说明如何进行 Dialect 之间的转换了。
这里的 class HelloToAffineLowerPass 主要需要实现 runOnOperation 函数。
namespace{
//继承PassWrapper,定义HelloToAffineLowerPass,它将作为函数钩子的实现返回到上面的pass注册
classHelloToAffineLowerPass:publicmlir::PassWrapper<HelloToAffineLowerPass, mlir::OperationPass<mlir::ModuleOp>> {
public:
MLIR_DEFINE_EXPLICIT_INTERNAL_INLINE_TYPE_ID(HelloToAffineLowerPass)
//依赖哪些标准库里的Dialect
voidgetDependentDialects(mlir::DialectRegistry ®istry)constoverride{
registry.insert<mlir::AffineDialect, mlir::func::FuncDialect, mlir::memref::MemRefDialect>();
}
voidrunOnOperation()final;
};
}
//需要实现的函数,它来说明如何做lowering
voidHelloToAffineLowerPass::runOnOperation(){
//获取上下文
mlir::ConversionTargettarget(getContext());
//在addIllegalDialect中将HelloDialect置为不合法(需要被lowering)
target.addIllegalDialect<hello::HelloDialect>();
//说明哪些Dialect是合法(lowering目标,通常是标准库中的Dialect)的
target.addLegalDialect<mlir::AffineDialect, mlir::BuiltinDialect,
mlir::func::FuncDialect, mlir::arith::ArithDialect, mlir::memref::MemRefDialect>();
//后期可通过`isDynamicallyLegal`决定其是否合法,这里具体表现为“当PrintOp的参数合法时,它才合法”
target.addDynamicallyLegalOp<hello::PrintOp>([](hello::PrintOp op"") {
returnllvm::none_of(op->getOperandTypes(),
[](mlir::Type type"") {returntype.isa<mlir::TensorType>(); });
});
//说明如何lowering,只需要把illegal的op的lowering实现作为模板参数传入RewritePatternSet
mlir::RewritePatternSetpatterns(&getContext());
patterns.add<ConstantOpLowering, PrintOpLowering>(&getContext());
if(mlir::failed(mlir::applyPartialConversion(getOperation(), target,std::move(patterns)))) {
signalPassFailure();
}
}
Pass 的实现确实工作量比较大,但是又不可避免,因为新的 Dialect 到标准库 Dialect 的过程还是必定需要手工实现。这也是很多反对 MLIR 的声音的来源。我们下期继续。
附全部代码
mlir-hello/lib/Hello/LowerToAffine.cpp
// Licensed to the Apache Software Foundation (ASF) under one
// or more contributor license agreements. See the NOTICE file
// distributed with this work for additional information
// regarding copyright ownership. The ASF licenses this file
// to you under the Apache License, Version 2.0 (the
// "License"); you may not use this file except in compliance
// with the License. You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing,
// software distributed under the License is distributed on an
// "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
// KIND, either express or implied. See the License for the
// specific language governing permissions and limitations
// under the License.
#include "Hello/HelloDialect.h"
#include "Hello/HelloOps.h"
#include "Hello/HelloPasses.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
#include "mlir/Dialect/Arith/IR/Arith.h"
#include "mlir/Dialect/Func/IR/FuncOps.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Pass/Pass.h"
#include "mlir/Transforms/DialectConversion.h"
#include "llvm/ADT/Sequence.h"
staticmlir::MemRefTypeconvertTensorToMemRef(mlir::TensorType type){
assert(type.hasRank() &&"expected only ranked shapes");
returnmlir::MemRefType::get(type.getShape(), type.getElementType());
}
staticmlir::ValueinsertAllocAndDealloc(mlir::MemRefType type, mlir::Location loc,
mlir::PatternRewriter &rewriter){
autoalloc = rewriter.create<mlir::memref::AllocOp>(loc, type);
// Make sure to allocate at the beginning of the block.
auto*parentBlock = alloc->getBlock();
alloc->moveBefore(&parentBlock->front());
// Make sure to deallocate this alloc at the end of the block. This is fine
// as toy functions have no control flow.
autodealloc = rewriter.create<mlir::memref::DeallocOp>(loc, alloc);
dealloc->moveBefore(&parentBlock->back());
returnalloc;
}
classConstantOpLowering:publicmlir::OpRewritePattern<hello::ConstantOp> {
usingOpRewritePattern<hello::ConstantOp>::OpRewritePattern;
mlir::LogicalResultmatchAndRewrite(hello::ConstantOp op, mlir::PatternRewriter &rewriter)constfinal{
mlir::DenseElementsAttr constantValue = op.getValue();
mlir::Location loc = op.getLoc();
// When lowering the constant operation, we allocate and assign the constant
// values to a corresponding memref allocation.
autotensorType = op.getType().cast<mlir::TensorType>();
automemRefType = convertTensorToMemRef(tensorType);
autoalloc = insertAllocAndDealloc(memRefType, loc, rewriter);
// We will be generating constant indices up-to the largest dimension.
// Create these constants up-front to avoid large amounts of redundant
// operations.
autovalueShape = memRefType.getShape();
mlir::SmallVector<mlir::Value, 8> constantIndices;
if(!valueShape.empty()) {
for(autoi : llvm::seq<int64_t>(
0, *std::max_element(valueShape.begin(), valueShape.end())))
constantIndices.push_back(rewriter.create<mlir::arith::ConstantIndexOp>(loc, i));
}else{
// This is the case of a tensor of rank 0.
constantIndices.push_back(rewriter.create<mlir::arith::ConstantIndexOp>(loc, 0));
}
// The constant operation represents a multi-dimensional constant, so we
// will need to generate a store for each of the elements. The following
// functor recursively walks the dimensions of the constant shape,
// generating a store when the recursion hits the base case.
// [4, 3] (1, 2, 3, 4, 5, 6, 7, 8)
// storeElements(0)
// indices = [0]
// storeElements(1)
// indices = [0, 0]
// storeElements(2)
// store (const 1) [0, 0]
// indices = [0]
// indices = [0, 1]
// storeElements(2)
// store (const 2) [0, 1]
// ...
//
mlir::SmallVector<mlir::Value, 2> indices;
autovalueIt = constantValue.getValues<mlir::FloatAttr>().begin();
std::function<void(uint64_t)> storeElements = [&](uint64_tdimension"&") {
// The last dimension is the base case of the recursion, at this point
// we store the element at the given index.
if(dimension == valueShape.size()) {
rewriter.create<mlir::AffineStoreOp>(
loc, rewriter.create<mlir::arith::ConstantOp>(loc, *valueIt++), alloc,
llvm::makeArrayRef(indices));
return;
}
// Otherwise, iterate over the current dimension and add the indices to
// the list.
for(uint64_ti = 0, e = valueShape[dimension]; i != e; ++i) {
indices.push_back(constantIndices[i]);
storeElements(dimension + 1);
indices.pop_back();
}
};
// Start the element storing recursion from the first dimension.
storeElements(/*dimension=*/0);
// Replace this operation with the generated alloc.
rewriter.replaceOp(op, alloc);
returnmlir::success();
}
};
classPrintOpLowering:publicmlir::OpConversionPattern<hello::PrintOp> {
usingOpConversionPattern<hello::PrintOp>::OpConversionPattern;
mlir::LogicalResultmatchAndRewrite(hello::PrintOp op, OpAdaptor adaptor,
mlir::ConversionPatternRewriter &rewriter)constfinal{
// We don't lower "hello.print" in this pass, but we need to update its
// operands.
rewriter.updateRootInPlace(op,
[&] { op->setOperands(adaptor.getOperands()); });
returnmlir::success();
}
};
namespace{
classHelloToAffineLowerPass:publicmlir::PassWrapper<HelloToAffineLowerPass, mlir::OperationPass<mlir::ModuleOp>> {
public:
MLIR_DEFINE_EXPLICIT_INTERNAL_INLINE_TYPE_ID(HelloToAffineLowerPass)
voidgetDependentDialects(mlir::DialectRegistry ®istry)constoverride{
registry.insert<mlir::AffineDialect, mlir::func::FuncDialect, mlir::memref::MemRefDialect>();
}
voidrunOnOperation()final;
};
}
voidHelloToAffineLowerPass::runOnOperation(){
mlir::ConversionTargettarget(getContext());
target.addIllegalDialect<hello::HelloDialect>();
target.addLegalDialect<mlir::AffineDialect, mlir::BuiltinDialect,
mlir::func::FuncDialect, mlir::arith::ArithDialect, mlir::memref::MemRefDialect>();
target.addDynamicallyLegalOp<hello::PrintOp>([](hello::PrintOp op"") {
returnllvm::none_of(op->getOperandTypes(),
[](mlir::Type type"") {returntype.isa<mlir::TensorType>(); });
});
mlir::RewritePatternSetpatterns(&getContext());
patterns.add<ConstantOpLowering, PrintOpLowering>(&getContext());
if(mlir::failed(mlir::applyPartialConversion(getOperation(), target,std::move(patterns)))) {
signalPassFailure();
}
}
std::unique_ptr<mlir::Pass>hello::createLowerToAffinePass(){
returnstd::make_unique<HelloToAffineLowerPass>();
}
MLIR添加矩阵乘算法
MLIR编译:参考官方文档即可,对机器的内存大小要求比较高
每章对应的代码路径:mlir/examples/toy/Ch.. 每章对应的示例路径:mlir/test/Examples/Toy/Ch.. 每章对应的可执行文件目录:build/bin
ch1
ch1的主要内容是介绍了Toy语言和其AST,由toy语言产生AST的命令如下例:
./toyc-ch1 ../../mlir/test/Examples/Toy/Ch1/ast.toy -emit=ast
toy-ch1等可执行文件在LLVM-main/build/bin文件夹下
ch2
ch2介绍了如何定义一个Dialect(教程中的Toy Dialect定义在Ops.td中,使用的是tablegen的形式)和operations的定义
下面我们介绍如何使用ODS定义矩阵乘,MatmulOp(有关MLIR中Op VS Operation中教程有,Operation是基类,Op类是衍生类):
(1)编写Ops.td
可以仿照已有的MulOp,基本一致,因为此时类似于定义这个Op的基本结构,并没有涉及这个Op实际上应该干啥
def MatmulOp : Toy_Op<"matmul">{
let summary = "matrix
multiplication";
let description = [{
The "matmul" operation
performs multiplication between two matrixs.
}]
let arguments = (ins F64Tensor:$lhs,
F64Tensor:$rhs);//定义输入参数
let results = (outs F64Tensor);//定义返回值
let parser = [{return
::parseBinaryOp(parser,result);}];
let printer = [{return
::printBinaryOp(p,*this);}];
let builders = [
OpBuilder<(ins
"Value":$lhs,"Value":$rhs)>
];
}
(2)编写Dialect.cpp
自定义build方法,可以先试着理解一下build是在干啥,之后会出文章专门细讲:
void MatmulOp::build(mlir::OpBuilder &builder,mlir::OperationState &state,
mlir::Value
lhs,mlir::Value rhs){
state.addTypes(UnrankedTensorType::get(builder.getF64Type()));
state.addOperands({lhs,rhs});}
(3)编写MLIRGen.cpp
加入对于matmul op的解析:
if (callee == "transpose") {
if (call.getArgs().size() != 1) {
emitError(location,
"MLIR codegen encountered an error: toy.transpose "
"does
not accept multiple arguments");
return nullptr;
}
return
builder.create<TransposeOp>(location, operands[0]);
}else if(callee ==
"matmul"){
if(call.getArgs().size()!=2){
emitError(location,"MLIR
codegen encountered an error: toy.matmul"
"does not accept multiple
arguments");
return nullptr;
}
return
builder.create<MatmulOp>(location,operands[0],operands[1]);
}
此时CH2部分能实现的代码完成,可以尝试跑一下示例codegen.toy改写为:
def
multiply_transpose(a, b) {
return transpose(a) * transpose(b);
}
def main() {
var a<2, 3> = [[1, 2, 3], [4, 5,
6]];
var b<2, 3> = [1, 2, 3, 4, 5, 6];
var c = multiply_transpose(a, b);
var d = multiply_transpose(b, a);
var g = matmul(transpose(a),b);
print(g);
print(d);
}
首先需要重新编译一下代码:
在build文件夹下执行cmake --build .
然后bin文件夹下`./toyc-ch6 ../../mlir/test/Exa
mples/Toy/Ch2/codegen.toy --emit=mlir`

Ch3
Ch2主要定义了矩阵乘的基本结构,但是对于矩阵乘内部如何实现还远远不够,Ch3这里教你如何实现一些Op优化,通过使用canonicalization pass,教程中给了优化transpose和reshape,我们这里针对Matmul Op实现matmul(matmul(A,B),C) -> matmul(A,matmul(B,C))的转变
(1)修改Ops.td
def
MatmulOp:Toy_Op<"matmul",
[NoSideEffect]>{//添加NoSideEffect特性,以使优化更加彻底
let summary = "matrix
multiplication";
let description = [{
The "matmul" operation
performs multiplication between two matrixs.
}]
let arguments = (ins
F64Tensor:$lhs,F64Tensor:$rhs);
let results = (outs F64Tensor);
let parser = [{return
::parseBinaryOp(parser,result);}];
let printer = [{return
::printBinaryOp(p,*this);}];
let builders = [
OpBuilder<(ins
"Value":$lhs,"Value":$rhs)>
];
let hasCanonicalizer = 1; //启用,代表该Op需要经过canonicalization pass
}
(2)修改ToyCombine.cpp
//addstruct RepositionRedundantMatmul:public mlir::OpRewritePattern<MatmulOp>{
RepositionRedundantMatmul(mlir::MLIRContext *context)
:OpRewritePattern<MatmulOp>(context,2){}
mlir::LogicalResult
matchAndRewrite(MatmulOp
op,mlir::PatternRewriter &rewriter)const override{
mlir::Value
MatmulLhs = op.getOperands()[0];//获取第一个操作数
mlir::Value
MatmulRhs = op.getOperands()[1];
MatmulOp matmulLhsOp = MatmulLhs.getDefiningOp<MatmulOp>();
if(!matmulLhsOp)return failure();//判断第一个操作数是否依然为MatmulOp
auto BxC
= rewriter.create<MatmulOp>(op.getLoc(),matmulLhsOp.getOperands()[1],MatmulRhs);//重现创建Op
auto
AxBC = rewriter.create<MatmulOp>(op.getLoc(),matmulLhsOp.getOperands()[0],BxC);
rewriter.replaceOp(op,{AxBC});//Op替换
return success();
}};//相当于注册吧,启用canonicalization passvoid MatmulOp::getCanonicalizationPatterns(RewritePatternSet &results,MLIRContext
*context){
results.add<RepositionRedundantMatmul>(context);}
编译完后进行验证
transpose_transpose.toy:
def
transpose_transpose(x) {
return transpose(transpose(x));
}
def main() {
var a<2, 3> = [[1, 2, 3], [4, 5,
6]];
var b = transpose_transpose(a);
var c =
matmul(matmul(transpose(a),b),transpose(a));
print(c);
print(b);
}
`./toyc-ch3 ../../mlir/test/Exa
mples/Toy/Ch3/transpose_transpose.toy --emit=mlir` (这张图显示的结果的形状是进行完Ch4后,结果tensor也有了明确的形状,如果没进行Ch4,结果tensor应该是tensor<?x?xf64>)

Ch4
Ch4介绍的使用interface实现形状推导,比如之前是
(tensor<2x3xf64>, tensor<3x2xf64>) -> tensor<?x?xf64>,形状推导后是
(tensor<2x3xf64>, tensor<3x2xf64>) -> tensor<2x2xf64>,形状推到的意义我觉得是能提前知道结果形状更容易调整空间分配
(1)修改Dialect.cpp
void MatmulOp::inferShapes(){
auto
lhsShape = getOperand(0).getType().cast<RankedTensorType>().getShape();
auto
rhsShape = getOperand(1).getType().cast<RankedTensorType>().getShape();
SmallVector<int64_t,2>dims;//构造新的形状
dims.push_back(lhsShape[0]);
dims.push_back(rhsShape[1]);
getResult().setType(RankedTensorType::get(dims,getOperand(0).getType().cast<RankedTensorType>().getElementType()));}
(2)修改Ops.td
def
MatmulOp:Toy_Op<"matmul",
[NoSideEffect,DeclareOpInterfaceMethods<ShapeInferenceOpInterface>]>{
//添加了Interface
let summary = "matmul
operation";
let description = [{
matmul operation
}];
let arguments = (ins
F64Tensor:$lhs,F64Tensor:$rhs);
let results = (outs F64Tensor);
let parser = [{return
::parseBinaryOp(parser,result);}];
let printer = [{return
::printBinaryOp(p,*this);}];
let builders = [
OpBuilder<(ins
"Value":$lhs,"Value":$rhs)>
];
let hasCanonicalizer = 1;
}
实现效果Ch3中那张图有了
Ch5
Ch5主要是实现Lowering到更低级别的Affine的Dialect上,这个比上面几个要难一些,因为这里要具体规定矩阵乘的操作。
主要是修改LowerToAffineLoops.cpp文件
static void lowerOpToLoopsMatmul(Operation *op,ValueRange operands,PatternRewriter &rewriter
,LoopIterationFn processIteration){
auto
tensorType = (*op->result_type_begin()).cast<TensorType>();//获得结果类型
auto loc
= op->getLoc();
auto
memRefType = convertTensorToMemRef(tensorType);//给结果申请空间
auto
alloc = insertAllocAndDealloc(memRefType,loc,rewriter);//类似于指向结果的指针
SmallVector<int64_t,4>lowerBounds(tensorType.getRank(),0);
SmallVector<int64_t,4>steps(tensorType.getRank(),1);
//获取第一个数组的第二维或第二个数组的第一维
SmallVector<int64_t,1> dimV;
auto dim
= op->getOperand(0).getType().cast<RankedTensorType>().getShape()[1];
dimV.push_back(dim);
//构架外面的两层循环
buildAffineLoopNest(rewriter,loc,lowerBounds,tensorType.getShape(),steps,
[&](OpBuilder &nestedBuilder,Location
loc,ValueRange ivs){
//先将结果数组赋初值为0
SmallVector<Value,2>setZeroIvs(ivs); //这里 里面取消了llvm::reverse的用法,这样最后输出的结果里面不会存在0项
//所以提醒我们要注意数据的存放顺序应该保持一致
auto
loadRes = rewriter.create<AffineLoadOp>(loc,alloc,setZeroIvs);
Value valueToStore = rewriter.create<arith::SubFOp>(loc,loadRes,loadRes);
//下面这个就感觉就是将某个数以某种写顺序存在某个地方
rewriter.create<AffineStoreOp>(loc,valueToStore,alloc,llvm::makeArrayRef(setZeroIvs));
//下面开始准备最内层的循环
SmallVector<int64_t,4>lowerBounds(1,0);//这里的1就指代一层循环
SmallVector<int64_t,4>steps(1,1);
//保留上面两层循环的层次信息,以便构造最内层操作
ValueRange resultIvs=ivs;
SmallVector<Value,3>forIvs;
forIvs.push_back(ivs[0]);
forIvs.push_back(ivs[1]);
//构造最内层循环
buildAffineLoopNest(rewriter,loc,lowerBounds,dimV,steps,
[&](OpBuilder &nestedBuilder,Location
loc,ValueRange ivs){
//在这里可以集齐所需要的三层循环层次
forIvs.push_back(ivs[0]);
Value valueToAdd=processIteration(nestedBuilder,operands,forIvs);
//实现加法
auto
loadResult = nestedBuilder.create<AffineLoadOp>(loc,alloc,resultIvs);
Value valueToStore = nestedBuilder.create<arith::AddFOp>(loc,loadResult,valueToAdd);
nestedBuilder.create<AffineStoreOp>(loc,valueToStore,alloc,resultIvs);
});
});
//这里直接可以替换op
rewriter.replaceOp(op,alloc);}//
最内层循环操作struct
MatmulOpLowering:public ConversionPattern{
MatmulOpLowering(MLIRContext *ctx)
:ConversionPattern(toy::MatmulOp::getOperationName(),1,ctx){}
LogicalResult matchAndRewrite(Operation *op,ArrayRef<Value>operands,ConversionPatternRewriter &rewriter)const final{
auto loc
= op->getLoc();
lowerOpToLoopsMatmul(op,operands,rewriter,
[loc](OpBuilder &builder,ValueRange
memRefOperands,ValueRange loopIvs){
typename toy::MatmulOpAdaptor MatmulAdaptor(memRefOperands);
SmallVector<Value,2>LhsIvs,RhsIvs;
LhsIvs.push_back(loopIvs[0]);
LhsIvs.push_back(loopIvs[2]);
RhsIvs.push_back(loopIvs[2]);
RhsIvs.push_back(loopIvs[1]);
auto
loadedLhs = builder.create<AffineLoadOp>(loc,MatmulAdaptor.lhs(),LhsIvs);
auto
loadedRhs = builder.create<AffineLoadOp>(loc,MatmulAdaptor.rhs(),RhsIvs);
return
builder.create<arith::MulFOp>(loc,loadedLhs,loadedRhs);
});
return success();
}};
编译后观察结果,codegen.toy改写为:
def main() {
var a<2, 3> = [[1, 2, 3], [4, 5,
6]];
var b<2, 3> = [1, 2, 3, 4, 5, 6];
var g = matmul(transpose(a),b);
print(g);
}
执行:`./toyc-ch5 ../../mlir/test/Examples/Toy/Ch5/codegen.toy --emit=mlir-affine`
结果:
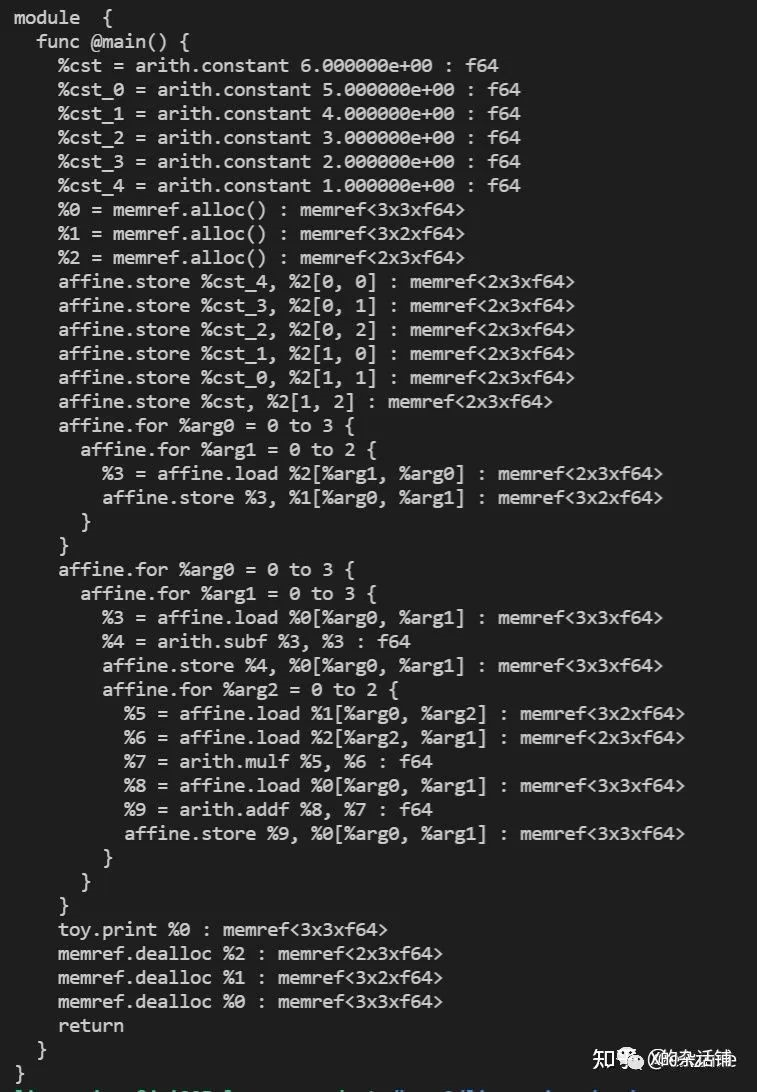
可以看到符合矩阵乘的定义
Ch6
Ch6就更进一步,lowering 到LLVM IR,然后利用LLVM的JIT机制执行,代码不需要改啥,需要你去把教程看一遍。
改写jit.toy:
def main() {
var a<2, 3> = [[1, 2, 3], [4,
5, 6]];
var b<3, 5> = [[1, 2, 3, 4,
5],[1,2,3,4,5],[1,2,3,4,5]];
var c = matmul(a, b);
print(c);
}
执行:`./toyc-ch6 ../../mlir/test/Examples/Toy/Ch6/jit.toy --emit=mlir-llvm `化为LLVM IR
执行:`./toyc-ch6 ../../mlir/test/Examples/Toy/Ch6/jit.toy --emit=ji` 可以看到矩阵乘的执行结果:

但是目前遇到一个问题,当加上优化(-opt)后,执行会出错:
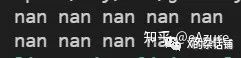
参考文献链接
mlir-hello: https://github.com/Lewuathe/mlir-hello
ODS: https://mlir.llvm.org/docs/OpDefinitions/
https://mp.weixin.qq.com/s/g9Hl4h1k2a0KsB_XjZvi4g
https://mp.weixin.qq.com/s/TdA8YkeNeEIoMdzbspc18g