背景
应用的启动速度严重影响开发效率、发布和回滚时长。由于历史和性能的原因,快手的应用会依赖一些包含实现的jar包,通过各种隐式地依赖传递,会在一些应用中富集。以快手的一个大型项目为例,WEB-INF/lib目录有1.6GB,包含62.4w个类,com.kuaishou包下有40w个类,最终加载的bean个数1w多个。过多的依赖,会严重拖慢应用的启动速度。
本文会先通过火焰图等工具,对启动的时间做一个分析,然后针对主要的问题逐个解决。
启动的时候做了哪些事情?
火焰图可以以调用栈的形式,展示各个方法在采样期间的时间占比。通过火焰图,再结合代码我们就可以清楚应用启动期间干了哪些事情,从而有针对性的去做优化。同时jvm自身也会暴露一些perf数据,可以通过jcmd来获取(jcmd <PID> PerfCounter.print)。
本次的工程是传统的spring mvc工程,采用tomcat进行部署,使用async-profiler或者idea的cpu profiler来获取火焰图。启动一次之后,就能得到如下的火焰图:
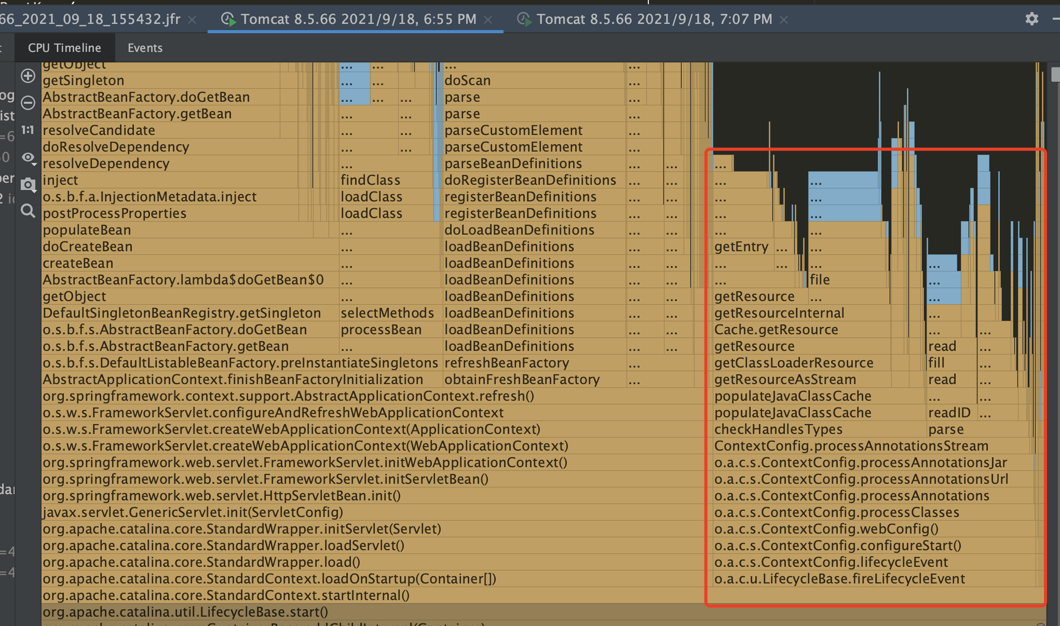
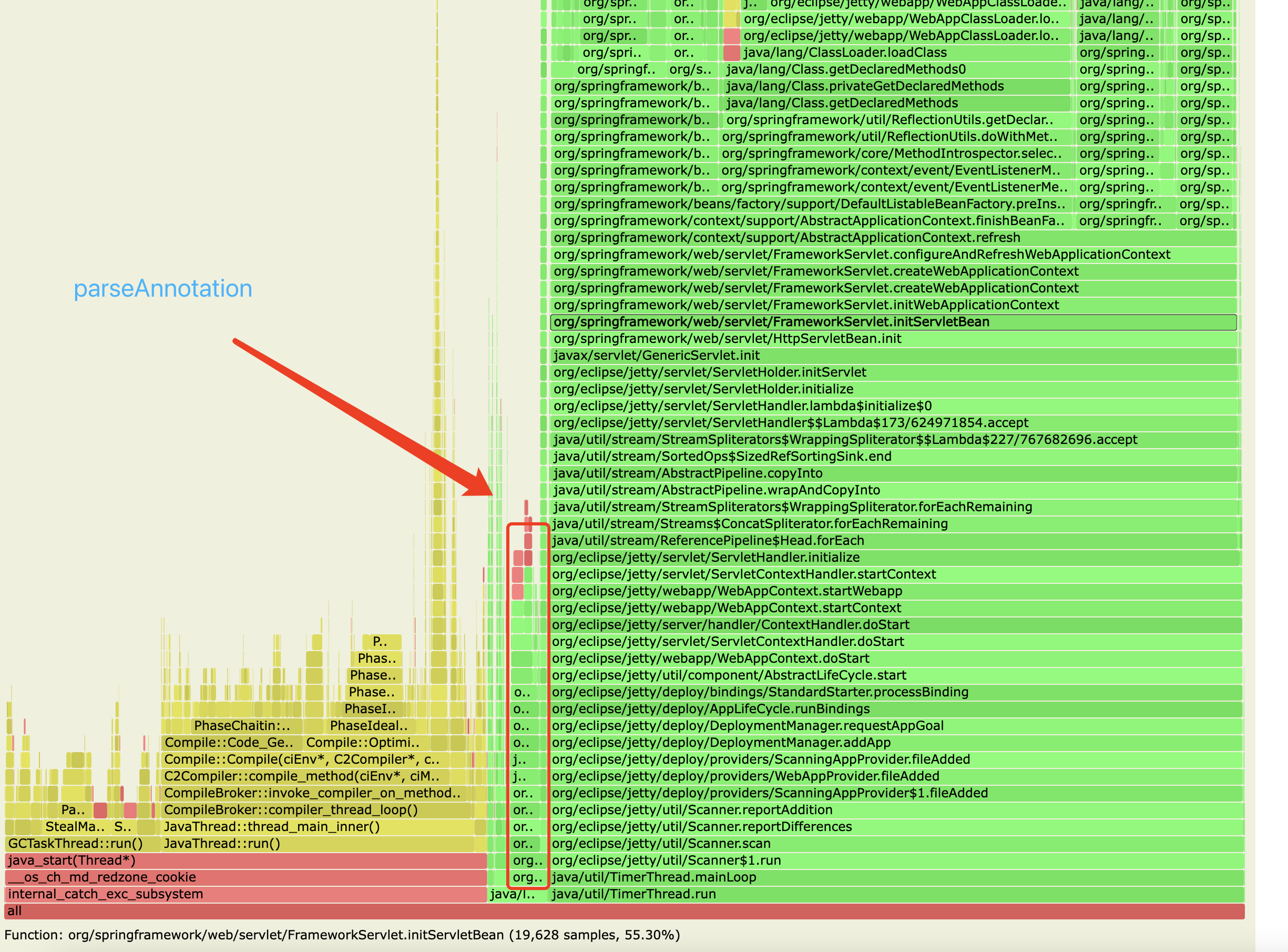
火焰图的左侧,是spring mvc的Servlet初始化的过程;右侧则是Servlet容器处理class的过程,占比还比较大。
启动完成之后,使用jcmd获取一些perf数据,重点关注下类加载的数据:
sun.cls.appClassBytes=405982541
sun.cls.appClassLoadCount=71069
sun.cls.appClassLoadTime=132769706902 (132s )
sun.cls.appClassLoadTime.self=60457989227appClassLoadCount 7w+,appClassLoadTime已经2min+了,类加载也是个大头。
类加载过程
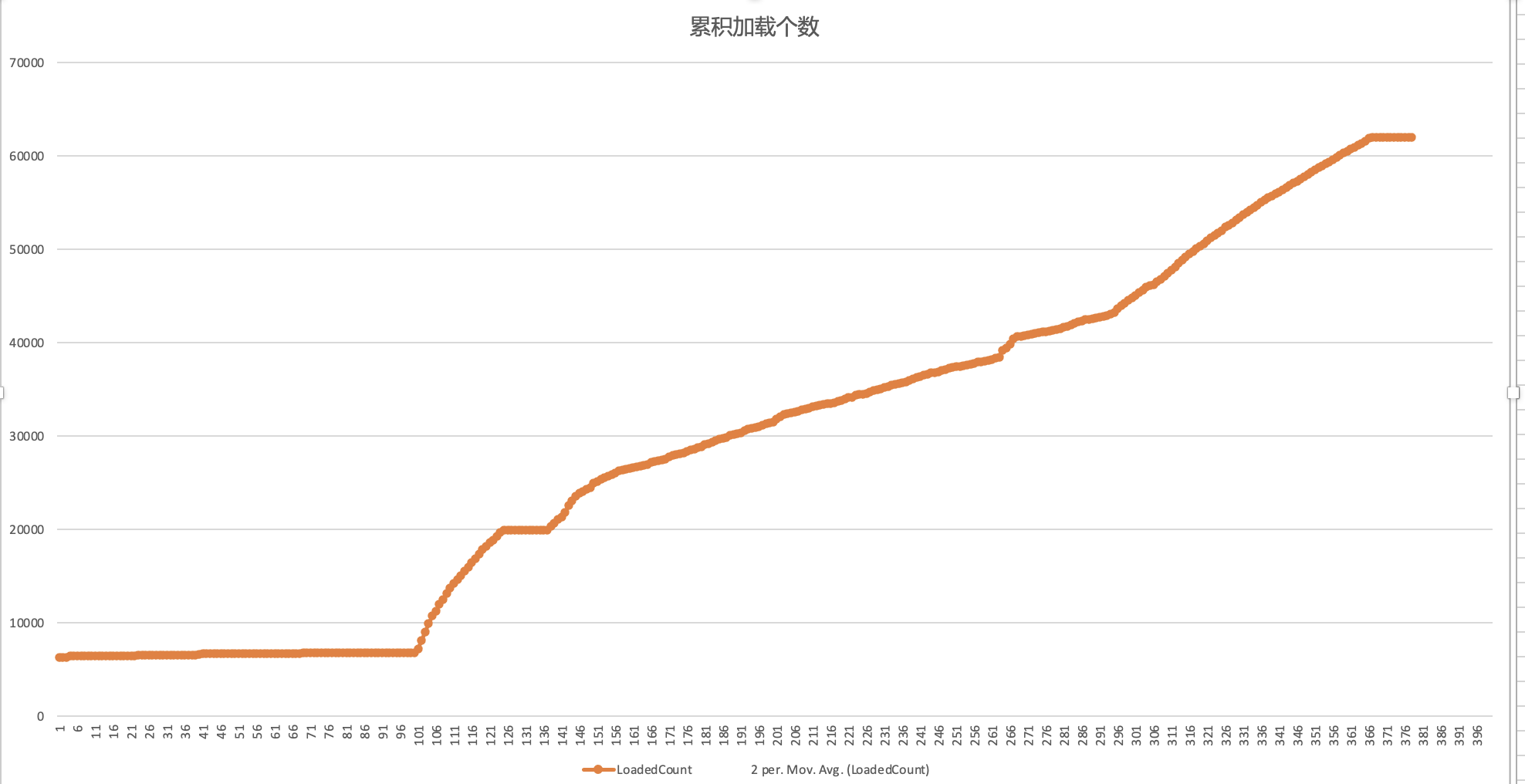
应用启动的过程,会伴随着大量的类加载(启动完成大概7w+),下图就反映了启动过程中不同时间点的类加载个数:
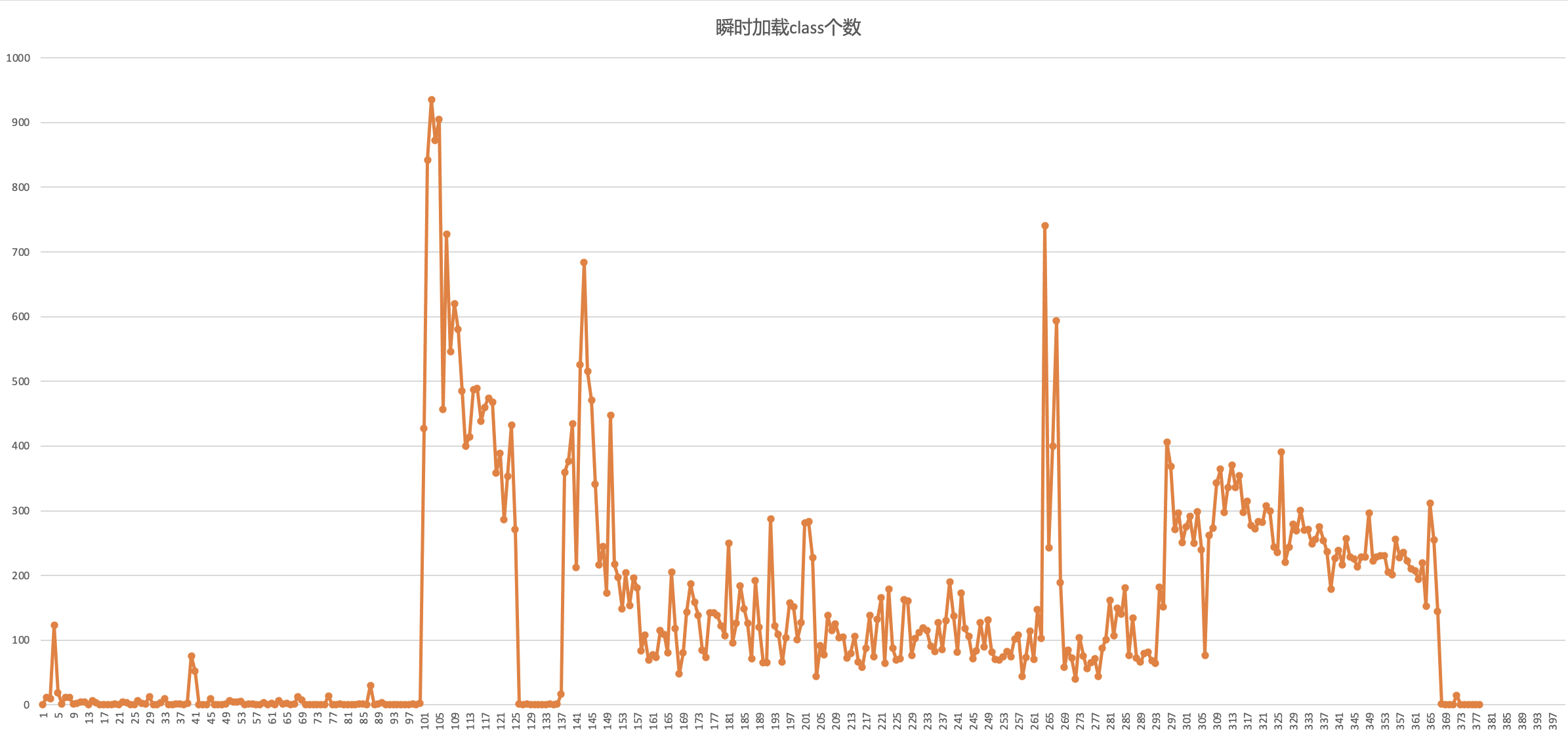
累积加载类个数:
Servlet容器扫描过程
从火焰图上看,扫描这一块大概占了1/3的时间。这是容器层做的扫描,主要是Servlet规范规定的。
需要servlet容器扫描的有以下特性:
-
之前的规范引入的,需要扫描的:
- TLD scanning, (Discovery of tag libraries. Scans for Tag Library Descriptor files, META-INF/*/.tld). 主要是定义了jsp标签和处理类的映射关系
-
Servlet 3.0引入的特性:
-
SCI (javax.servlet.ServletContainerInitializer),通过SPI加载 META-INF/services/javax.servlet.ServletContainerInitializer.
web容器启动的时候会通知SCI,可以使用编程的方式注册servlet、filter、listener等。可以和@HandlesTypes配合使用,容器会扫描HandlesTypes指定的接口或注解的实现类,作为参数传入onStartup接口。
public interface ServletContainerInitializer { public void onStartup(Set<Class<?>> c, ServletContext ctx) throws ServletException; } -
Web fragments (web module deployment descriptor fragments)加载 META-INF/web-fragment.xml
是web.xml的逻辑分区,用法跟web.xml一样,可以定义在jar包里
-
Resources of a web application bundled in jar files (META-INF/resources/*)
-
Annotations that define components of a web application (@WebServlet etc.)
-
Annotations that define components for 3-rd party libraries initialized by an SCI (arbitrary annotations that are defined in @HandlesTypes annotation on a SCI class)
-
大部分扫描都只是读取META-INF下对应文件加载的,速度一般不慢。注解扫描是最耗时的,因为每个class文件都需要被读取、解析然后获取注解信息。在普通的应用中,也许并不耗时,但是在62.4w个类这么大规模下,耗时就很可观了。tomcat并没有采用类加载的方式,而是解析class文件,底层使用的是apache的BCEL(Apache Commons BCEL™ – Home)处理class的字节码。这一步在测试中发现,大约耗时100s左右。
Spring 容器初始化过程
占比最大的一块,就是spring容器初始化这一部分,我们大量的业务bean都会在这一步初始化。可以把火焰图放大下:

主要矛盾,就是红框中的这五块,从左至又主要是:
- org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#initializeBean(java.lang.Object, java.lang.String)
- 主要是HandlerInterceptor的加载过程,包含controller的各种初始化
- org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#populateBean
- populate bean的过程,主要包含依赖的注入,依赖的bean的初始化
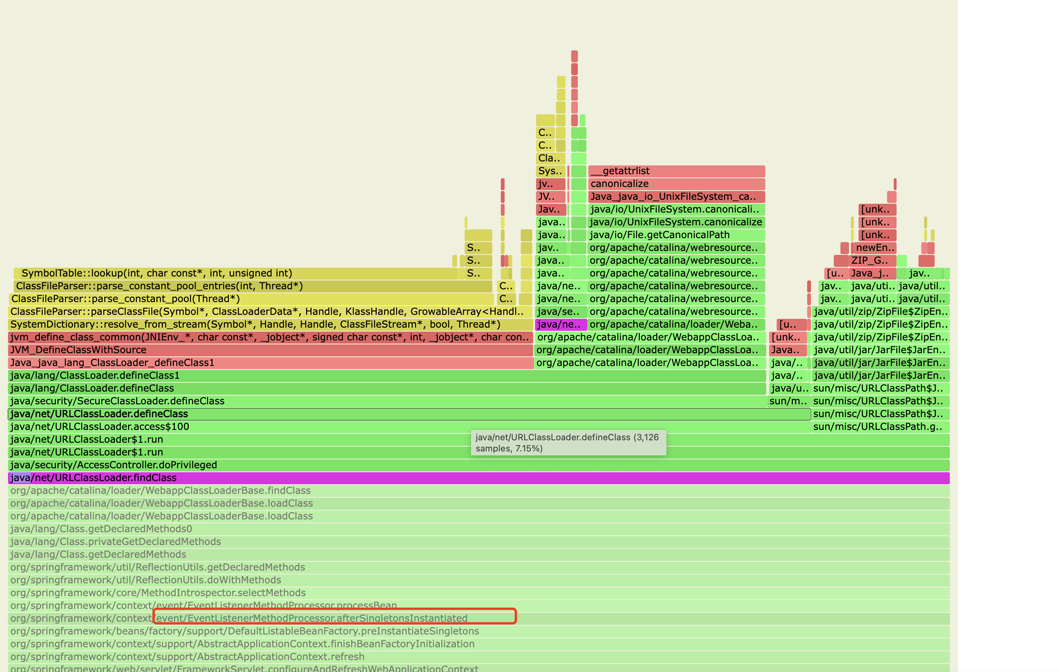
- org.springframework.context.event.EventListenerMethodProcessor#afterSingletonsInstantiated
- 初始化EventListener,会查找所有的bean(包含lazy的),获取方法上的注解(会触发入参、出参等类的加载)
- org.springframework.context.support.AbstractApplicationContext#invokeBeanFactoryPostProcessors
- 主要是Java Config的扫描加载过程
- org.springframework.web.context.support.XmlWebApplicationContext#loadBeanDefinitions(org.springframework.beans.factory.support.DefaultListableBeanFactory)
- xml配置的扫描和bean的加载过程
如何优化
最好的优化就是控制项目的规模,控制依赖的传递,避免类路径上有大量无用的依赖,缩小扫描的范围。这些如果都没有办法做到的话,只能根据实际的情况做针对性的优化了。
类加载优化
如果能优化类加载的速度,无异于釜底抽薪。
类加载过程
我们告诉classloader要加载某个类,他是如何找到类的二进制文件呢?其实没有特别高深的算法,就是挨个去jar包里找。
// sun.misc.URLClassPath#findResource
/**
* Finds the resource with the specified name on the URL search path
* or null if not found or security check fails.
*
* @param name the name of the resource
* @param check whether to perform a security check
* @return a <code>URL</code> for the resource, or <code>null</code>
* if the resource could not be found.
*/
public URL findResource(String name, boolean check) {
Loader loader;
for (int i = 0; (loader = getLoader(i)) != null; i++) {
URL url = loader.findResource(name, check);
if (url != null) {
return url;
}
}
return null;
}默认的,每个jar包会对应一个JarLoader,findResource操作就是getJarEntry,如果存在对应的JarEntry,就相当于找到了对应的类。
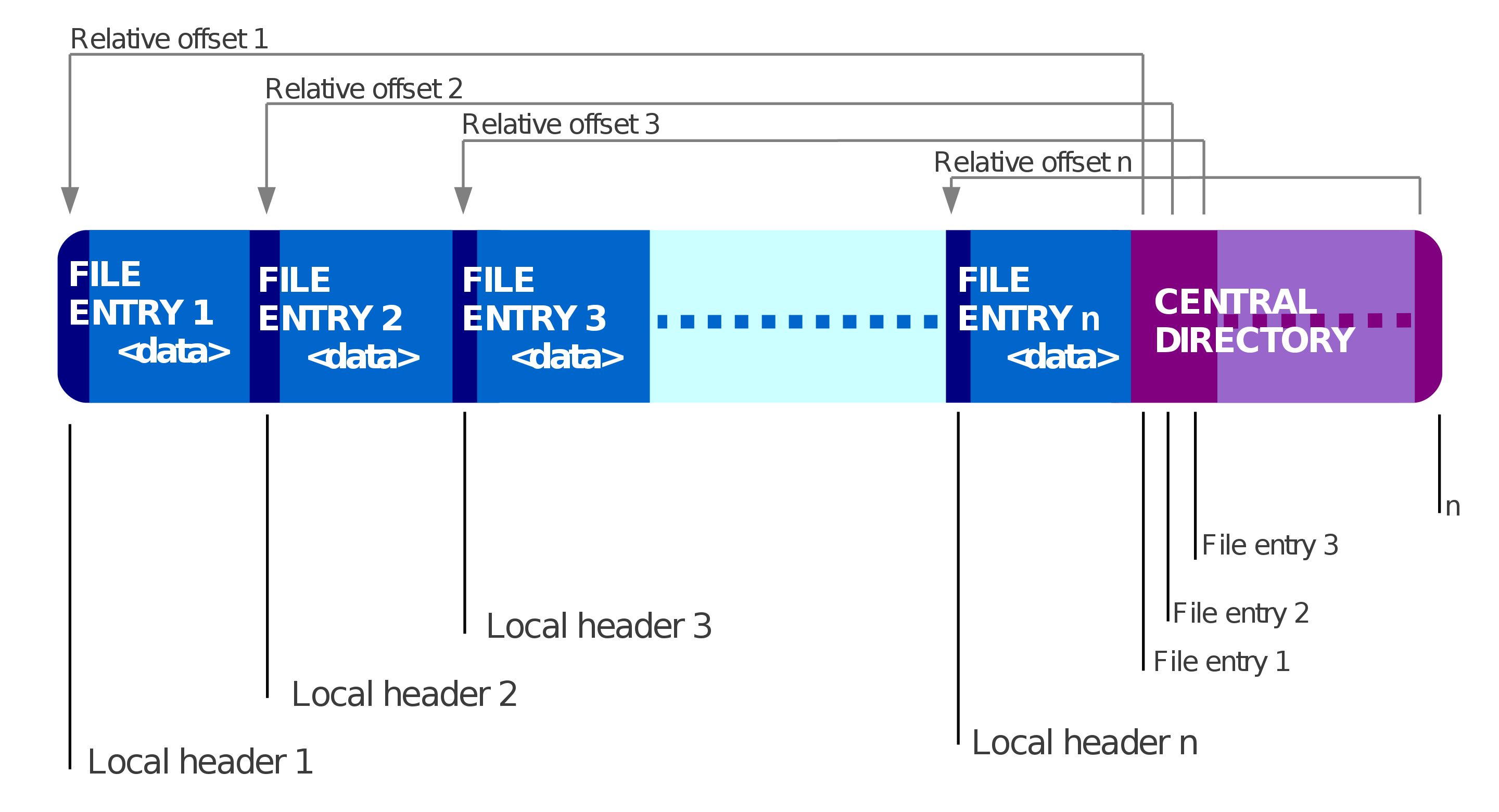
jar文件,本质上是zip文件,会在central directory记录所有的entry,所以getJarEntry本质上也不算耗时。但是项目膨胀地过大时,这里可能就是瓶颈。我们的项目中加载了7w+的类,每个类都要走一遍getJarEntry的操作,相当于二重循环了。
for class in ClassesToLoad
for jar in Jars
getJarEntryJar Index技术
受《探究 Java 应用的启动速度优化》这篇文章的启发,里面提到了Jar Index的技术,这看起来是一个非常不错的技术。
Since 1.3, JarIndex is introduced to optimize the class searching process of class loaders for network applications, especially applets.
This directory information is stored in a simple text file named INDEX.LIST in the META-INF directory of the root jar file. When the classloader loads the root jar file, it reads the INDEX.LIST file and uses it to construct a hash table of mappings from file and package names to lists of jar file names.
Jar Index技术的思想是搞一个ROOT JAR。ROOT JAR就是包含一个INDEX.LIST的文件的jar,这个文件就是索引文件,索引文件记录了每个entry和jar包的映射关系。同时要保证这个JAR优先加载。这样classloader就能用到索引,方便的定位class所在的jar包。这项技术在jdk1.3时就引入了,初衷是解决java applet的加载速度问题(优先加载root jar,加载类时就知道类所在jar包的大概范围,这样就不用下载所有的jar包了)。
Jar Index技术看起来非常服务我们的业务场景,但是过于古老,应用的时候需要解决一下问题:
-
编译时生成ROOT JAR和INDEX.LIST,只需修改maven-war-plugin即可;
-
tomcat这边需要通过自定义类加载器,将类加载委托给URLClassLoader
- 需要修改conf/context.xml,使用自定义的loader
- 并且需要将自定义的classloader所在的jar包丢到tomcat的lib目录;
- 在自定义的class loader中,优先加载ROOT Jar
-
使用INDEX.LIST之后,getResources只返回一个资源的bug问题
- Bug ID: JDK-8150615 URLClassLoader.getResources only returns one match from multiple JAR files mentioned in an JAR index
- 这个问题比较致命,spring扫描bean就是依赖getResources("com.kuaishou")来进行的
- 可以在自定义的class loader中进行绕过(比如维护两个URLClassLoder,一个包含ROOT JAR,一个不包含)
- 有能力定制jdk的,可以自行修改下
感谢效能团队@刘冬的支持,会对maven-war-plugin做修改,并对tomcat的docker镜像做定制。后续会在流水线的编译选项上增加一个是否使用klib的开关,此功能目前还在灰度当中。
Jar Index加速效果
本地测试find class resource 时间对比:
-
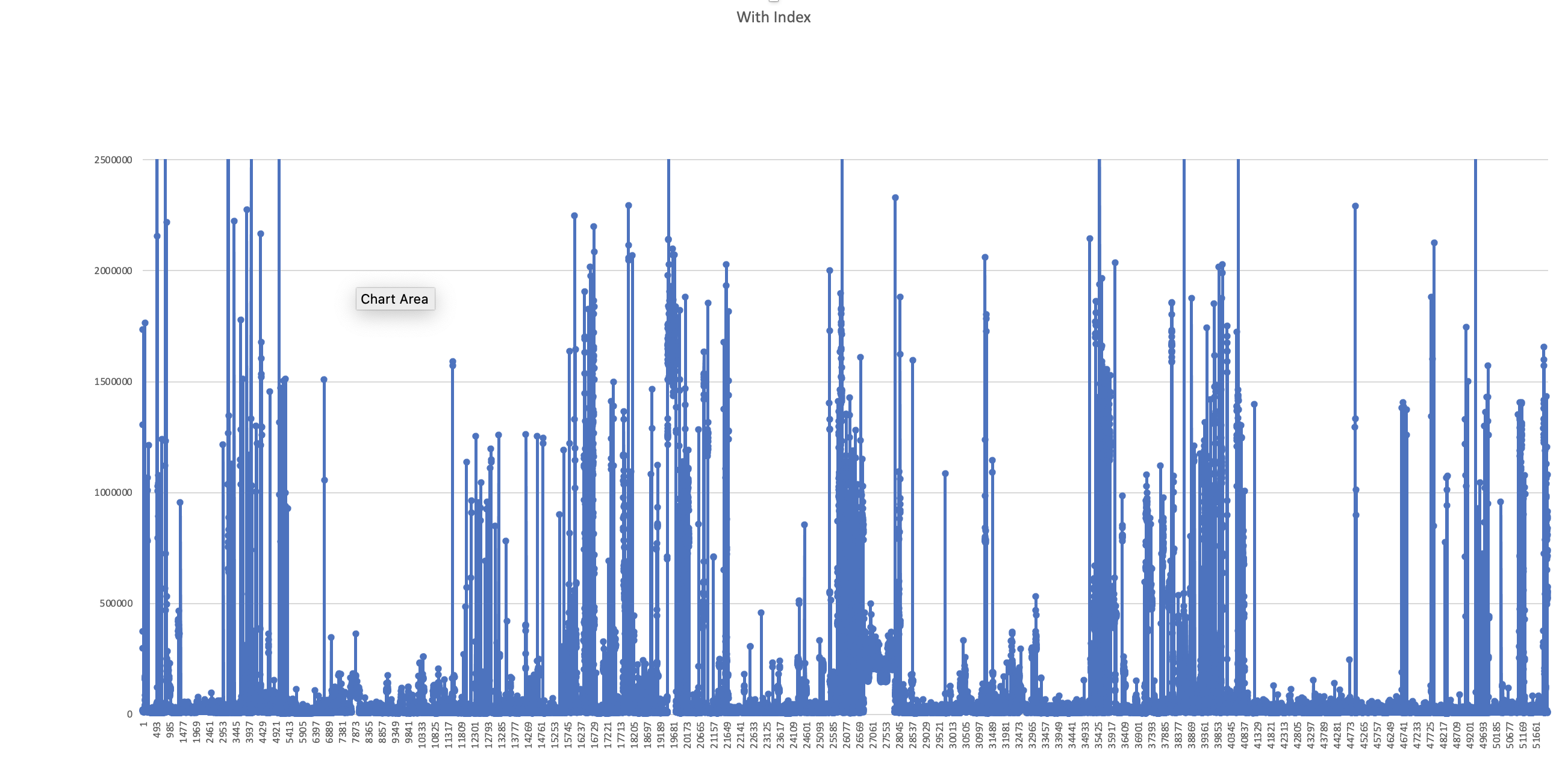
使用INDEX.LIST,波动是因为要初始化loader和index。
总时间4s, 52109个class (纵坐标——类加载用时,单位:nanoTime;横坐标——时间)
-
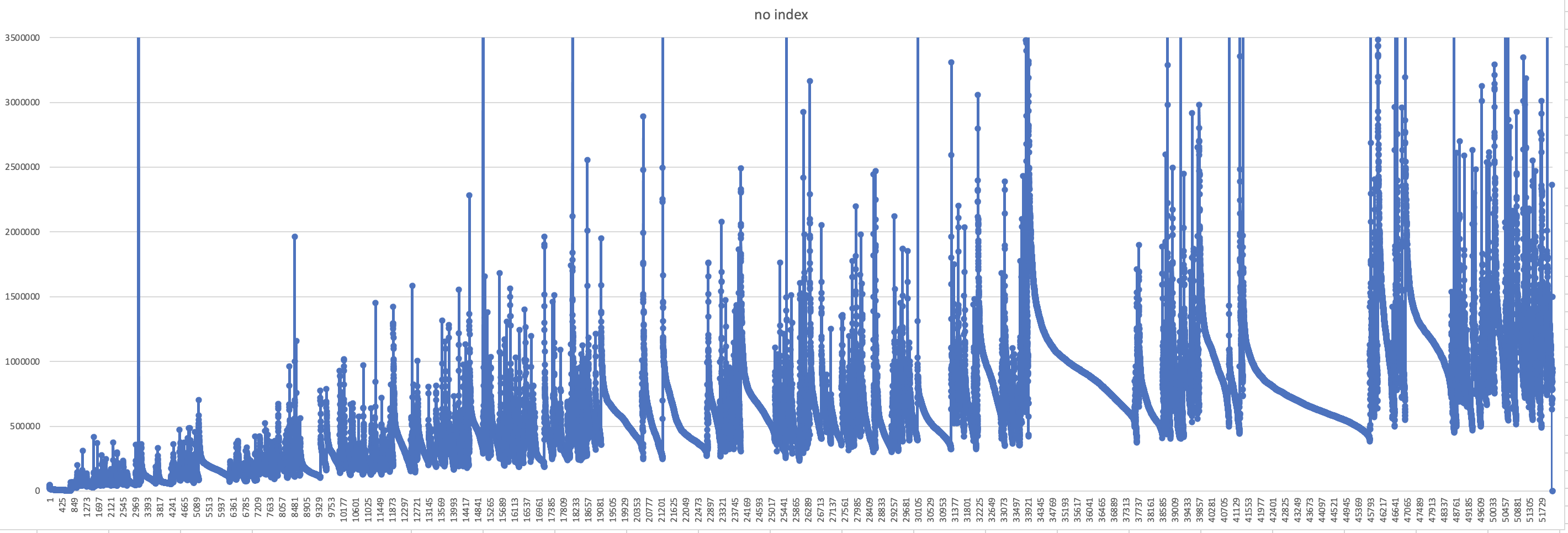
正常加载,class所在的loader的越靠后,时间越长(遍历的jar包越多)。
总时间32s, 52109个class(纵坐标——类加载用时,单位:nanoTime,横坐标——loader index)
Spring初始化过程中EventListenerMethodProcessor也被优化了,EventListenerMethodProcessor占整体的比例变小,findClassInternal函数中defineClass和getClassLoaderResource的比例也发生了明显的变化。
火焰图对比:
不使用JAR INDEX:

使用JAR INDEX:
物理机测试kuaishou-api启动时间,使用Jar Index技术,可以让启动时间从170s,下降至90s左右,降幅80s。
PerfAgent
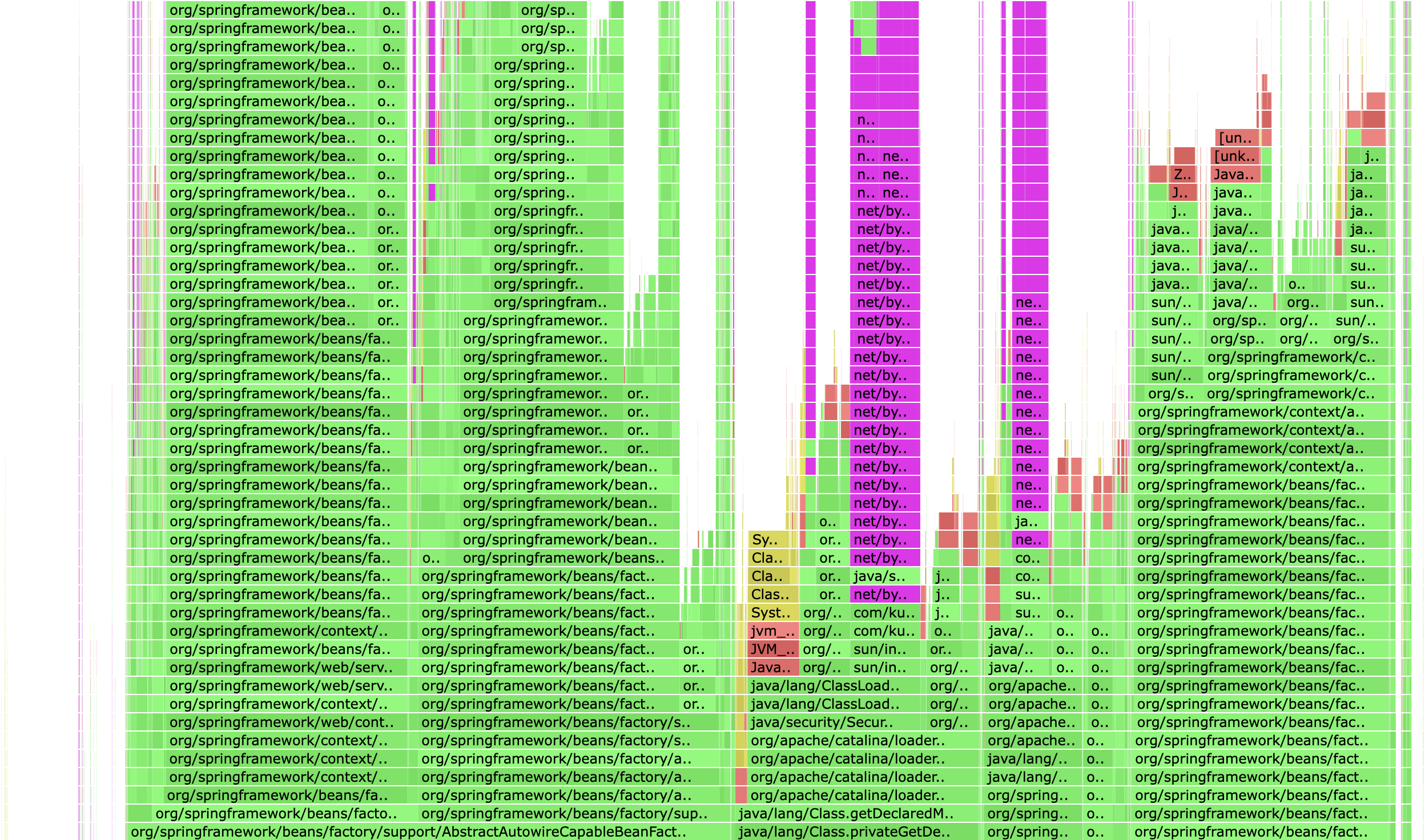
PerfAgent支持在方法上打上注解(@Perf,@Trace),然后收集对应的执行时间。这个功能没有依赖Spring的AOP,使用的是字节码技术,底层是ByteBuddy。ByteBuddy对有注解的类做了增强,因此每次加载类都会走ByteBuddy的判断逻辑,加载的类较多时(7w+),性能影响就比较大了。
kuaishou-api项目中,ByteBuddy的sample占总数的11.91%。涉及到类加载的都会增加一些额外的耗时。
关闭PerfAgent
如果没有用到@Perf、@Trace相关的功能,还是建议关闭。
-
感谢infra团队@董刘,已经为PerfAgent增加了开关,配置jvm参数
-DdisablePerfAgent=true,即可关闭。可以在服务树上统一配置,这样子树继承都会生效。 -
如果项目比较少,可以直接删掉对应的Listener
<listener> <listener-class>com.kuaishou.framework.perf.processor.PerfAgentServletContextListener</listener-class> </listener>
kuaishou-api项目,线上关闭PerfAgent之后,启动耗时下降至少1min+。
Servlet容器扫描优化
关闭扫描
如果没有用到Servlet对应的注解和SCI,可以直接关闭tomcat的Servlet的扫描。
-
metadata-complete
Setting metadata-complete="true" disables scanning your web application and its libraries for classes that use annotations to define components of a web application (Servlets etc.).
设置为true,tomcat就不处理注解形式声明的Servlet和filter,也不会处理META-INF/web-fragments。
-
absolute-ordering
The metadata-complete option is not enough to disable all of annotation scanning. If there is a SCI with a @HandlesTypes annotation, Tomcat has to scan your application for classes that use annotations or interfaces specified in that annotation.
The element specifies which web fragment JARs (according to the names in their WEB-INF/web-fragment.xml files) have to be scanned for SCIs, fragments and annotations. An empty element configures that none are to be scanned.
只设置metadata-complete="true",还是有可能触发类的扫描。SCI类上可以有@HandlerTypes注解,注解里可以设置需要处理的接口或者注解,容器需要找出所有实现了接口或者注解的类,作为参数传递给SCI。
absolute-ordering是为了解决扫描的顺序问题,也是扫描的白名单。如果设置为空,就不会加载SCI等组件,也不会触发@HandlerTypes的处理逻辑。配置示例:
<web-app metadata-complete="true" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://xmlns.jcp.org/xml/ns/javaee" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd" version="3.1"> <absolute-ordering />
如果不能关闭
并行化
tomcat9也已经支持并行扫描了,升级配置下即可
| 参数名称 | 含义 |
|---|---|
| parallelAnnotationScanning | When set to true annotation scanning will be performed using the utility executor. It will allow processing scanning in parallel which may improve deployment type at the expense of higher server load. If not specified, the default of false is used. |
配置示例:
<!-- conf/context.xml -->
<Context parallelAnnotationScanning="true">
<!-- Default set of monitored resources. If one of these changes, the -->
<!-- web application will be reloaded. -->
<WatchedResource>WEB-INF/web.xml</WatchedResource>
<WatchedResource>${catalina.base}/conf/web.xml</WatchedResource>
<!-- Uncomment this to disable session persistence across Tomcat restarts -->
<!--
<Manager pathname="" />
-->
</Context>换个Servlet容器
tomcat底层使用的是apache的BCEL,性能比ASM差点。可以使用基于ASM扫描的Jetty,都开启并行处理的情况下,jetty看起来性能更好一些。
火焰图对比:
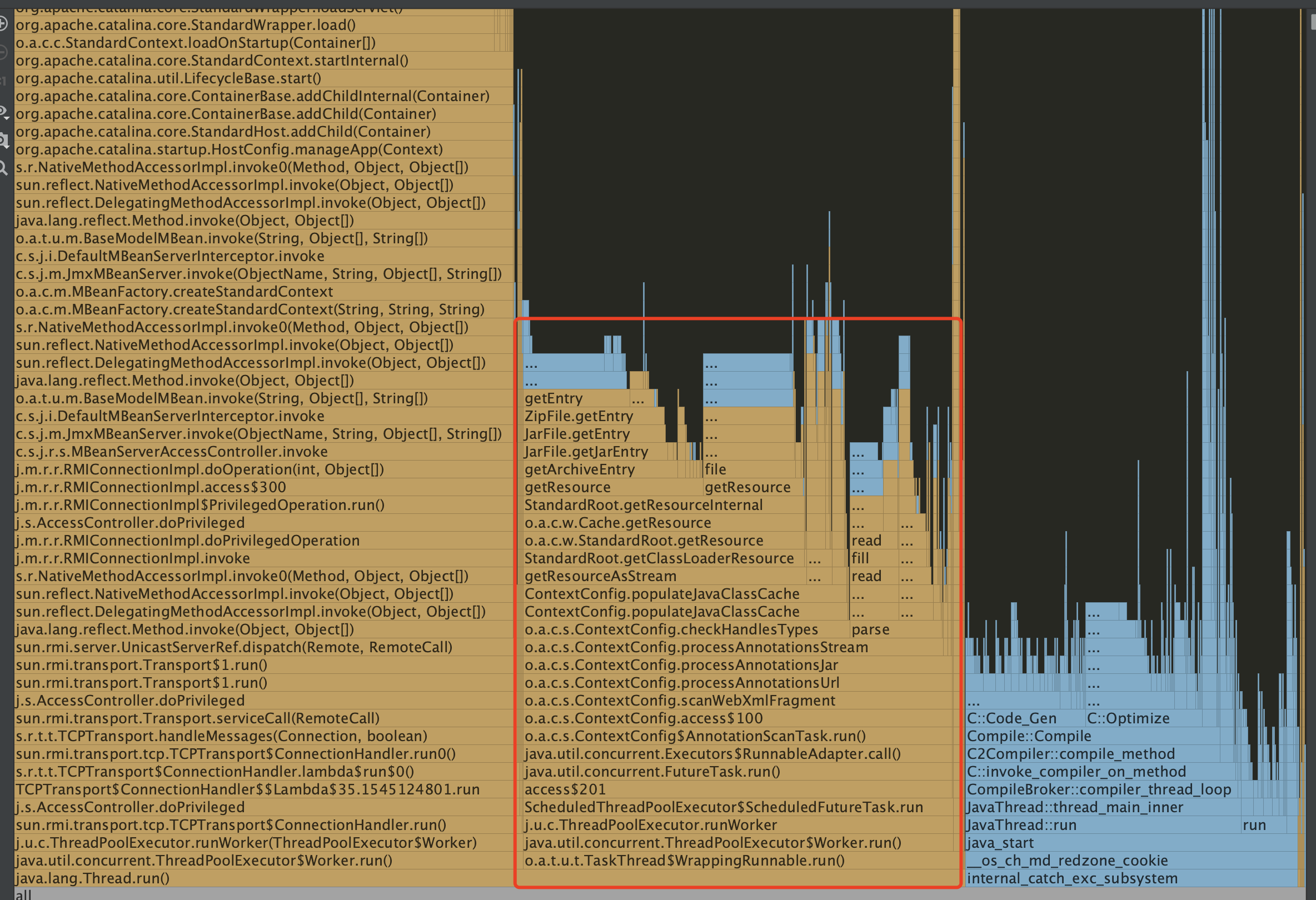
Jetty9开启并行扫描注解的火焰图
tomcat9开启并行化扫描的火焰图:
Spring boot embedded tomcat已经默认关闭了
Spring boot embedded tomcat 默认禁用了SCI和注解形式的Servlet组件的加载(Embedded Tomcat does not honor ServletContainerInitializers · Issue #321 · spring-projects/spring-boot)
但是,Spring boot也提供了解决方案。他提供了@ServletComponentScan注解,可以指定扫描的package范围,然后将扫描到的@WebServlet等的实现通过编程的方式,向ServletContext注册。这样扫描就从Servlet容器这一层,被提升到了Spring这一层,用的逻辑跟扫描bean是一样的。
Spring容器初始化过程
initializeBean和populateBean
这一块是硬骨头,主要和Spring容器里bean的数目相关,初始化时又会根据依赖关系拉起许多相关的bean。
我们的项目虽然是代码在一起,但是部署的时候又分为不同的集群(历史原因未拆分)。也就是说,有些bean可能根本不会用到,但是还是会被Spring加载初始化。
针对这个实际的场景,我们的优化方案就是将不需要的bean给lazy化,通过上线前的预热,触发真正需要的bean加载。@姚远通过BeanFactoryPostProcessor实现了bean的默认lazy化。经过优化,启动完成之后实际初始化的bean只有1000多个,总共加载的bean 1w多个(包含lazy),启动耗时降低1.103min。
EventListenerMethodProcessor
实测过程中,发现这一步触发了2w多个类的加载。
这一部分的优化在类加载部分已经提及,除了优化类加载没有好的方式。即使将bean lazy化也无法解决,spring项目上已经有issue提及这个问题:EventListenerMethodProcessor defeats lazy factory beans · Issue #22293 · spring-projects/spring-framework
优化后的火焰图中,这一部分的占比仍然十分大:
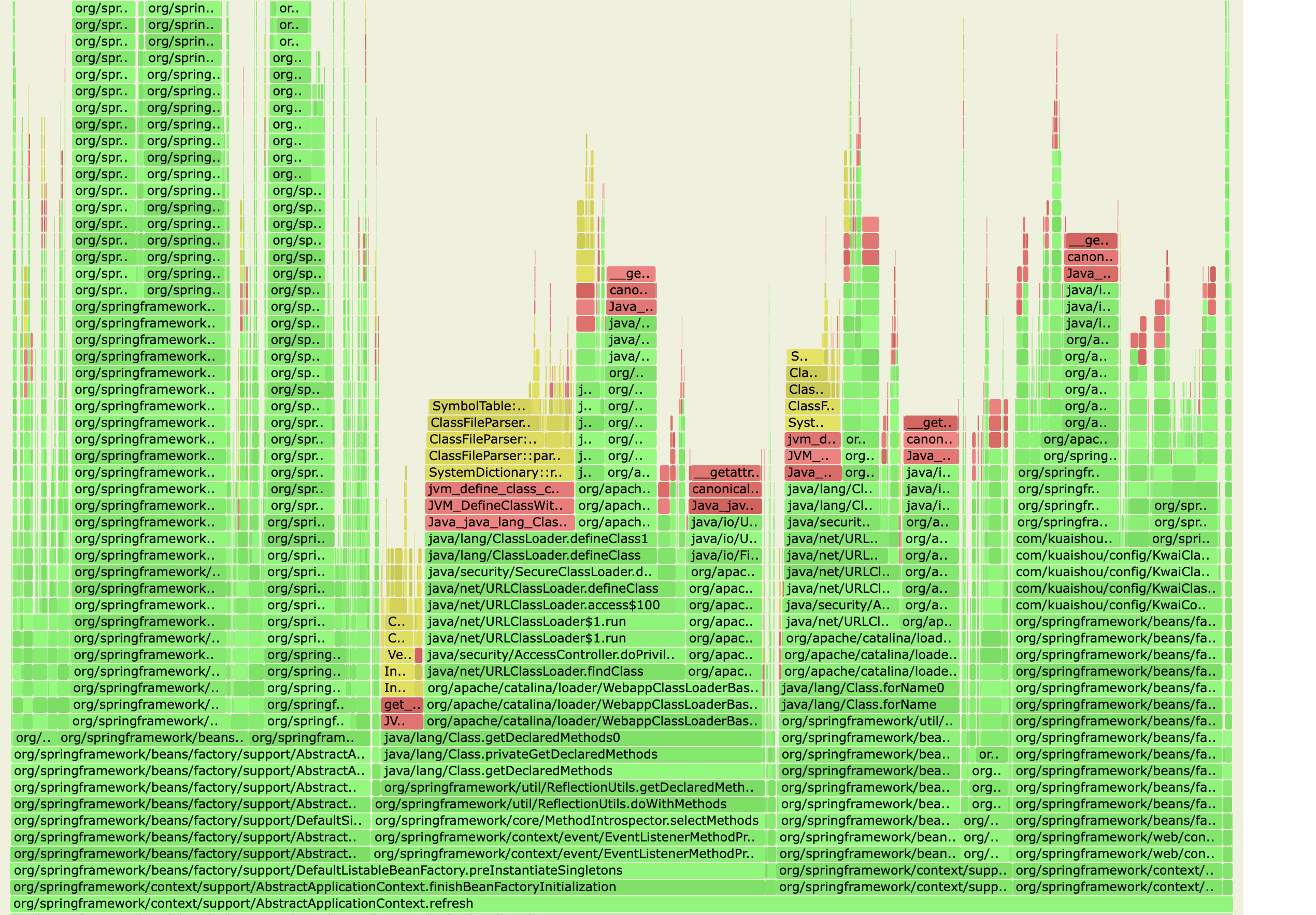
可以通过覆盖Spring默认的bean,然后定制EventListenerMethodProcessor的逻辑,跳过Lazy Bean的扫描或者直接白名单(感谢infra团队@董刘、@刘世龙的支持,会增加一些开关,稍后上线)。
对应的火焰图:
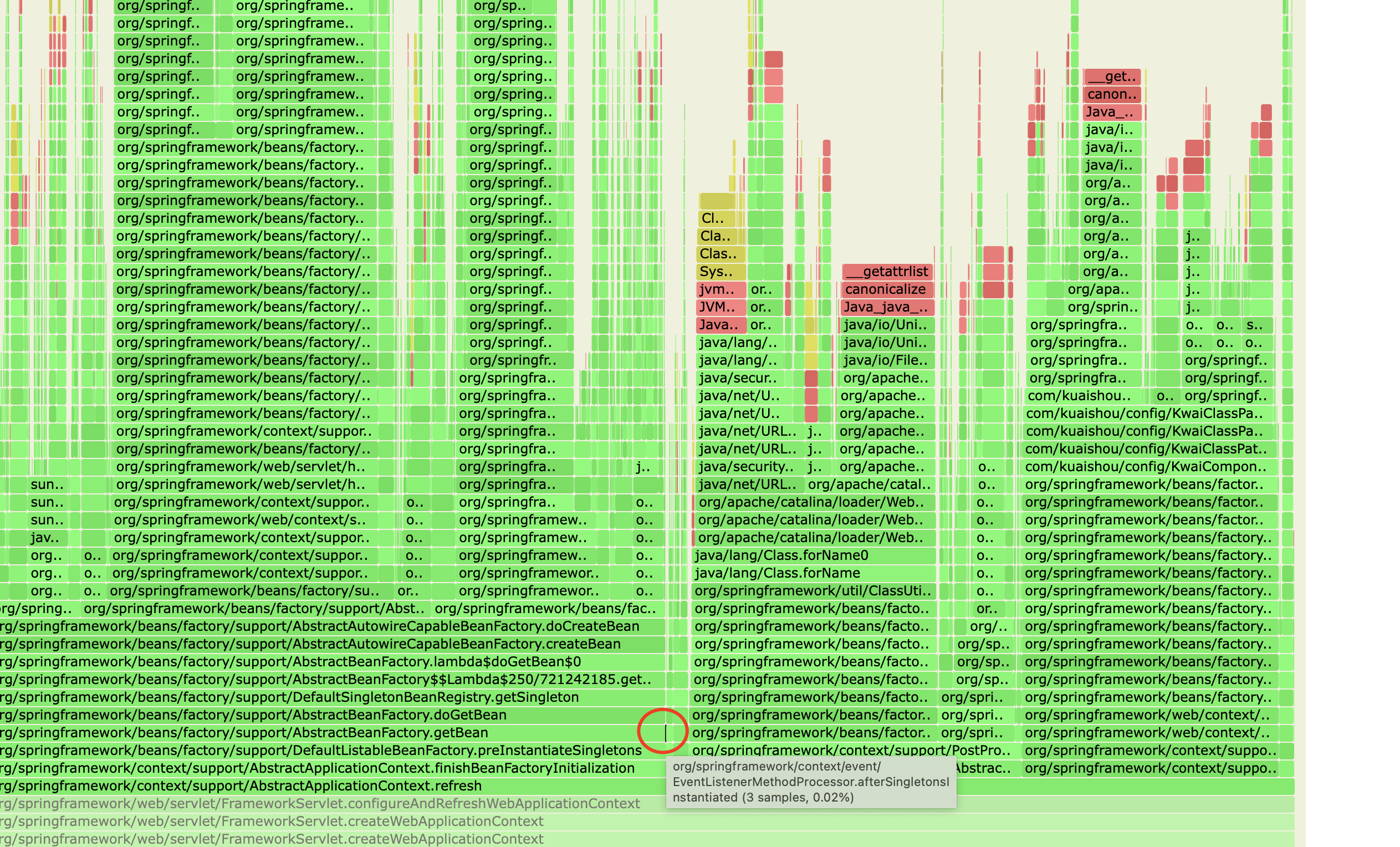
kuaishou-api中,大部分bean都lazy化了,所以直接干掉了一座大山。这一步大概也40s左右,和优化classloader的时间有叠加。
Bean的扫描和加载过程
这一部分的优化对应火焰图里左右边的两块,底层走的扫描逻辑是一致的。
首先看下spring扫描bean的过程:
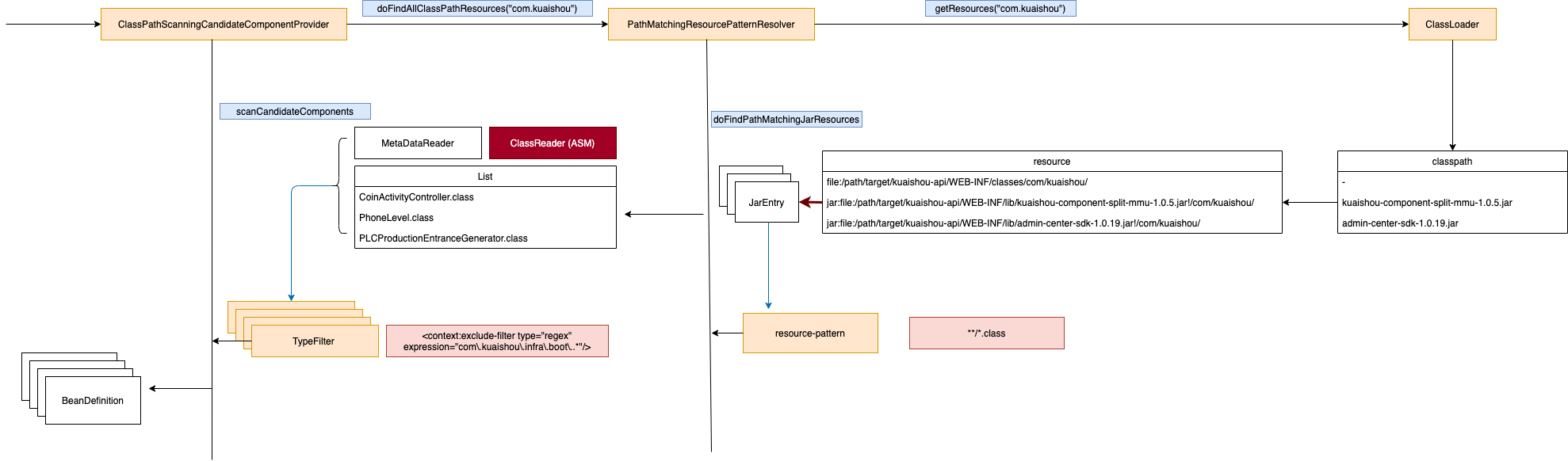
Spring借助classloader提供的getResources("com.kuaishou")功能,获取class path下所有包含com.kuaishou的Resource。然后根据用户提供的resource-pattern(默认是**/*.class)过滤出目标资源。接下来再过一层scanner中定义的TypeFilter(按注解、正则等过滤),最终返回符合要求的BeanDefinition。Scanner这一层支持按注解扫描,所以需要解析class文件获取注解信息,这一层Spring用的是ASM读取的类信息。同时注解会有继承关系,也需要加载注解类,获取所有的基类。
这一层的扫描和Servlet容器的扫描十分类似,只不过spring是按照package扫描的,我们的项目配置的扫描范围是com.kuaishou,com.kuaishou包下有40w类,比Servlet容器扫描的62.4w个类少了很多。我们经过分析发现,扫描的大量类中有许多Grpc自动生成的类,占比非常可观(30w左右)。通过修改Spring源码的方式,跳过Grpc自动生成的类的扫描,时间可以下降40s左右。
Spring Context Indexer技术
Spring大概也意识到了启动速度慢的问题,Spring-context-indexer是Spring官方出品的优化方案。
主要思想是编译期通过javac的AnnotationProcessor去处理spring bean相关的注解,生成一个index文件(存放在META-INF/spring.components),在启动的时候扫描所有jar包里的这个文件,直接从index文件定位到对应的bean,避免了大量读取和解析大量的类。
INDEX文件示例:
#
#Fri Oct 08 16:45:38 CST 2021
com.lightks.protobuf.horizon.simple.HorizonSimpleServiceGrpc=javax.annotation.Generated
com.lightks.protobuf.trade.refund.material.KrpcTradeRefundServiceGrpc=javax.annotation.Generated
com.lightks.biz.course.service.impl.CourseFeedInfoRpcClientServiceImpl=org.springframework.stereotype.Component
com.lightks.protobuf.course.simpleinfo.KrpcCourseBaseServiceGrpc=javax.annotation.Generated
com.lightks.biz.course.service.impl.CourseSimpleInfoLocalCacheServiceImpl=org.springframework.stereotype.Component
com.lightks.client.CourseSearchClient=org.springframework.stereotype.Component
com.lightks.biz.course.service.impl.CourseStreamDisplayServiceImpl=org.springframework.stereotype.Component加载的时候,直接走index即可,相当于是走了白名单。
这个Index技术,让扫描bean的过程可以直接精准定位,而且没有bean的jar包增多是不影响扫描的速度的。
Spring Context Indexer落地
公司的root pom中已经集成了生成index文件的jar包,编译时会自动生成META-INF/kuaishou.components文件。快手主站的kuaishou-api项目,依赖中大于3M的jar包,且包含com.kuaishou目录的,基本都已经包含kuaishou.components文件。
Spring默认的Indexer扫包时存在一些问题,不能直接用。我们自定义了Scanner相关的逻辑,通过Spring的自定义标签触发相应逻辑的加载,实现了渐进式地切换到index文件。线上的效果来看,启动加速也有1min左右。
感谢infra团队@董刘、@刘世龙的支持,从源码层面修改对应的逻辑,Spring项目和KsBoot项目都能够获得收益(进行中)。
获取启动时火焰图
参考doc: 启动时火焰图
JDK新特性——AppCDS测试
参考doc:AppCDS启动加速验证
总结
通过禁止Servlet容器扫描、Jar Index加速类加载、关闭PerfAgent、Lazy化bean、优化EventListenerMethodProcessor扫描以及Spring Context Indexer等优化手段,我们的启动时间从6min下降至1min左右,极大地提高了研发、部署以及回滚止损的效率。
项目过大时,对各个组件的压力都是非比寻常的,日常实践中需要尽力避免这种巨无霸的项目,最好能够进行垂直拆分、微服务化。