目录
flask之信号,flask-script,sqlalchemy介绍和快速使用,创建操作数据表
昨日回顾
# 1 local对象
并发编程中的一个对象 它可以保证多线程并发访问数据
本质原理是:不同的线程 操作的是自己的数据
不支持协程
# 2 自己定义local 支持线程和协程
# 注意点一:
try:
# 只要解释器没有装greenlet 这句话就会报错
# 一旦装了 有两种情况 使用了协程和没用协程 无论使用不使用 用getcurrent都能拿到协程id号
from greenlet import getcurrent as get_ident
except Exception as e:
from threading import get_ident
# 注意点二:重写类的 __setattr__ 和 __getattr__
对象.属性 取值 不存在会触发 __getattr__
对象.属性 设置值 不存在会触发 __setattr__
# 注意点三:由于重写了__setattr__ 和 __getattr__
类内部使用 self.storage 会递归
使用类调用对象的方法 它就是普通函数 有几个值传几个值
object.__setattr__(self, 'storage', {})
等同于:self.storage={}
等价于:setattr(self, 'storage', {}) 也会递归
# django flask 同步框架 部署的时候 使用uwsgi部署 uwsgi是进程线程架构 并发量不高
# 可以通过uwsgi+gevent 部署成异步程序
今日内容详细
1 信号
# Flask框架中的信号基于blinker(安装这个模块) 其主要就是让开发者可以在flask请求过程中定制一些用户行为 flask和django都有
# 观察者模式 又叫发布-订阅(Publish/Subscribe) 23种设计模式之一
pip install blinker
# 信号:signial 翻译过来的 并发编程中学过 信号量Semaphore
# 比如:用户新增一条记录 就记录一下日志
方案一:在每个增加后 都写一行代码---> 后期要删除 比较麻烦
方案二:使用信号 写一个函数 绑定内置信号 只要程序执行到这 就会执行这个函数
# 内置信号:flask少一些 django多一些
request_started = _signals.signal('request-started')
# 请求到来前执行
request_finished = _signals.signal('request-finished')
# 请求结束后执行
before_render_template = _signals.signal('before-render-template')
# 模板渲染前执行
template_rendered = _signals.signal('template-rendered')
# 模板渲染后执行
got_request_exception = _signals.signal('got_request_exception')
# 请求执行出现异常时执行
request_tearing_down = _signals.signal('request_tearing_down')
# 请求执行完毕后自动执行(无论成功与否)
appcontext_tearing_down = _signals.signal('appcontext_tearing_down')
# 应用上下文执行完毕后自动执行(无论成功与否)
appcontext_pushed = _signals.signal('appcontext_pushed')
# 应用上下文push时执行
appcontext_popped = _signals.signal('appcontext_popped')
# 应用上下文pop时执行
message_flashed = _signals.signal('message_flashed')
# 调用flask在其中添加数据时 自动触发
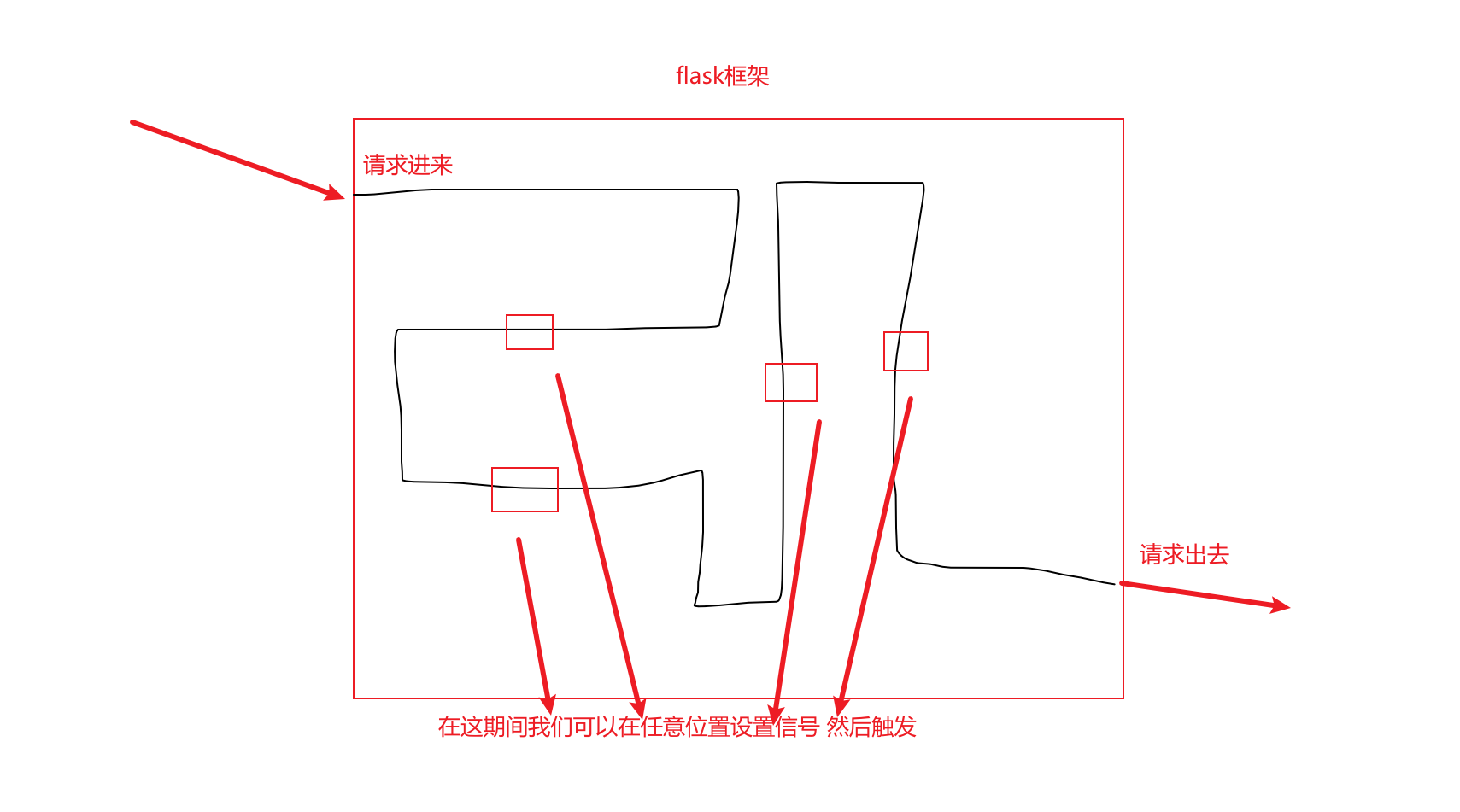
# 使用内置信号的步骤
1 写一个函数
2 绑定内置信号
3 等待被触发
# 自定义信号
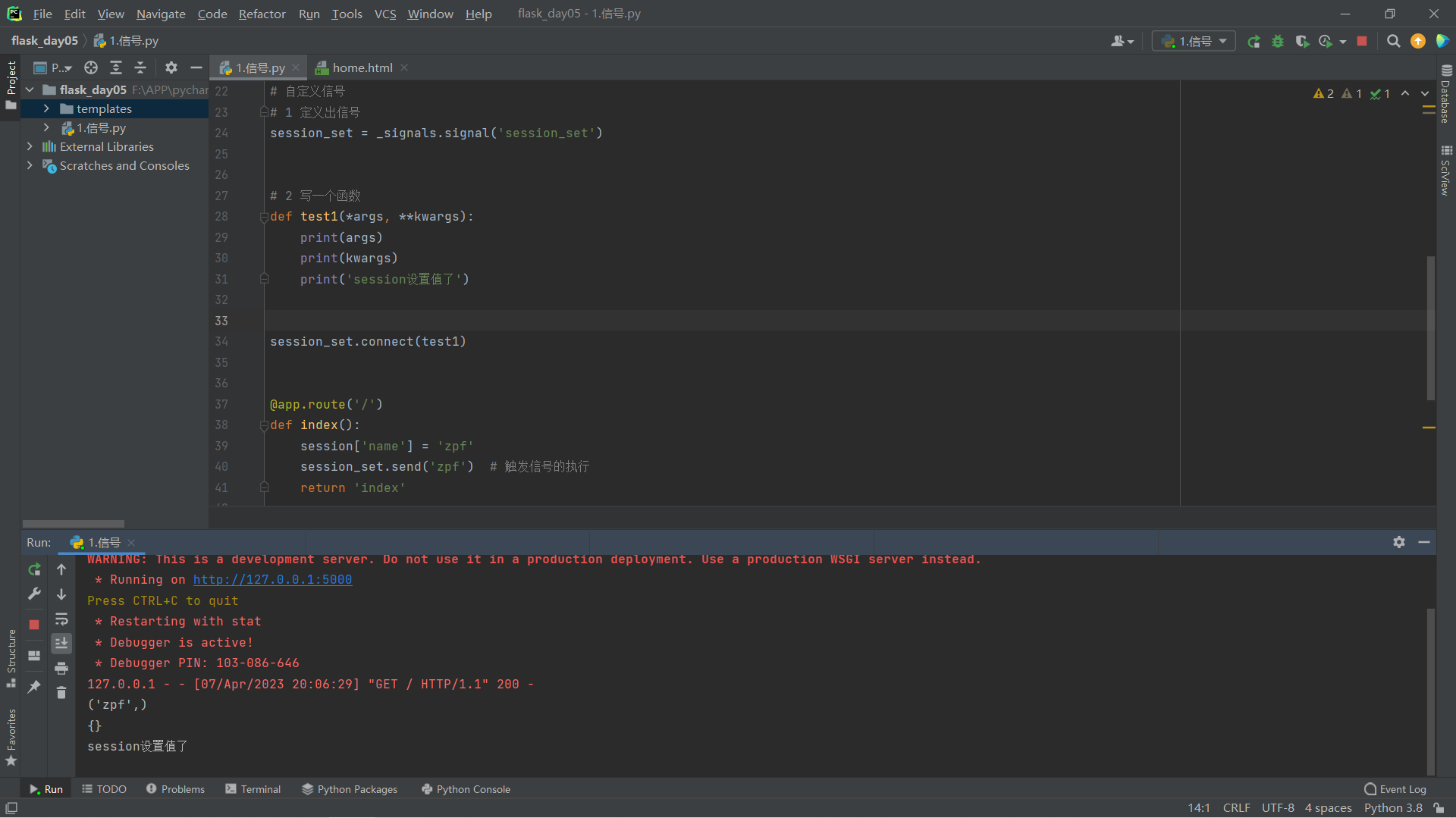
# 1 定义出信号
session_set = _signals.signal('session_set')
# 2 写一个函数
def test1(*args, **kwargs):
print(args)
print(kwargs)
print('session设置值了')
session_set.connect(test1)
@app.route('/')
def index():
session['name'] = 'zpf'
session_set.send('zpf') # 触发信号的执行
return 'index'
# django中使用信号
https://www.cnblogs.com/liuqingzheng/articles/9803403.html
1.2 django信号
Model signals
pre_init # django的model执行其构造方法前 自动触发
post_init # django的model执行其构造方法后 自动触发
pre_save # django的model对象保存前 自动触发
post_save # django的model对象保存后 自动触发
pre_delete # django的model对象删除前 自动触发
post_delete # django的model对象删除后 自动触发
m2m_changed # django的model对象中使用m2m字段操作第三张表(add remove clear)前后 自动触发
class_prepared # 程序启动时 检测已注册的app中的model类 对于每一个类 自动触发
Management signals
pre_migrate # 执行migrate命令前 自动触发
post_migrate # 执行migrate命令后 自动触发
Request/request signals
request_started # 请求到来前 自动触发
request_finished # 请求结束后 自动触发
got_request_exception# 请求异常后 自动触发
Database Wrappers
connection_created # 创建数据库连接时 自动触发
# django中使用内置信号
# 1 写一个函数
def callBack(*args, **kwargs):
print(args)
print(kwargs)
# 2 绑定信号
# 方式一
post_save.connect(callBack)
# 方式二
from django.db.models.signals import pre_save
from django.dispatch import receiver
@receiver(pre_save)
def my_callback(sender, **kwargs):
print("对象创建成功")
print(sender)
print(kwargs)
# 3 等待触发
2 flask-script
# django中 有命令
python manage.py runserver
......
# flask启动项目 像django一样 通过命令启动
# Flask版本和Flask_Script版本对应关系
Flask==2.2.2
Flask_Script==2.0.3
# 借助于:flask-script实现
-安装:pip3.8 install flask-script
-修改代码:
from flask_script import Manager
manager=Manager(app)
manager.run()
-用命令启动
python manage.py runserver
# 自定制命令
# 1 简单自定制命令
@manager.command
def custom(arg):
# 命令的代码,比如:初始化数据库, 有个excel表格,使用命令导入到mysql中
print(arg)
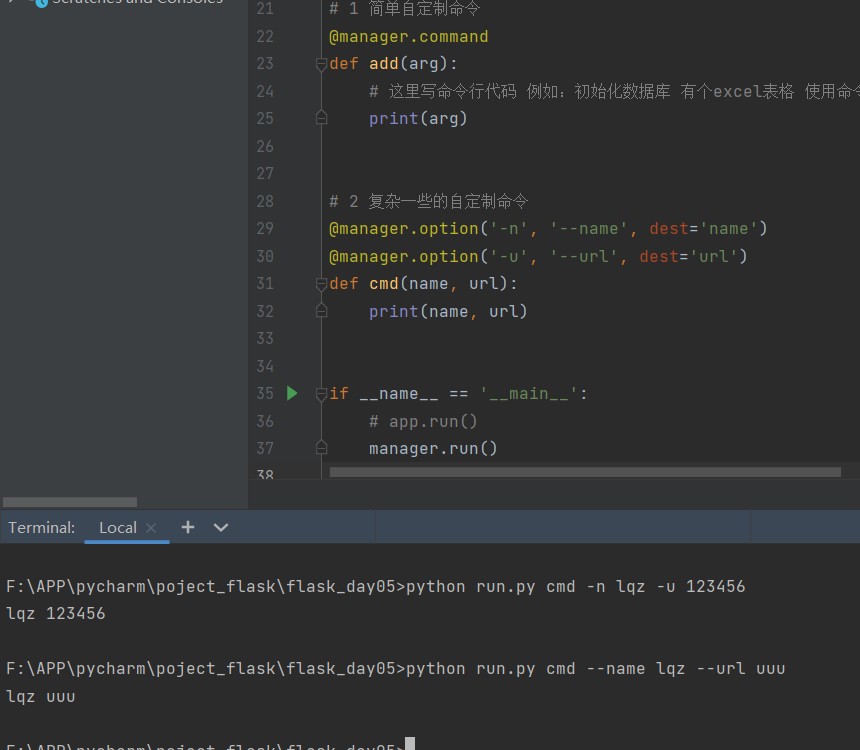
# 2 复杂一些的自定制命令
@manager.option('-n', '--name', dest='name')
@manager.option('-u', '--url', dest='url')
def cmd(name, url):
# python run.py cmd -n lqz -u xxx
# python run.py cmd --name lqz --url uuu
print(name, url)
# 扩展:django中如何自定制命令
3 sqlalchemy快速使用
# flask 中没有orm框架 对象关系映射 方便我们快速操作数据库
# flask fastapi中用sqlalchemy居多
# SQLAlchemy是一个基于Python实现的ORM框架 该框架建立在 DB API之上 使用关系对象映射进行数据库操作 简言之便是:将类和对象转化成SQL 然后使用数据API执行SQL并获取执行结果
# 安装
pip install sqlalchemy
# 了解
SQLAlchemy本身无法操作数据库 其鄙俗依赖pymysql等第三方插件
pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
更多:http://docs.sqlalchemy.org/en/latest/dialects/index.html
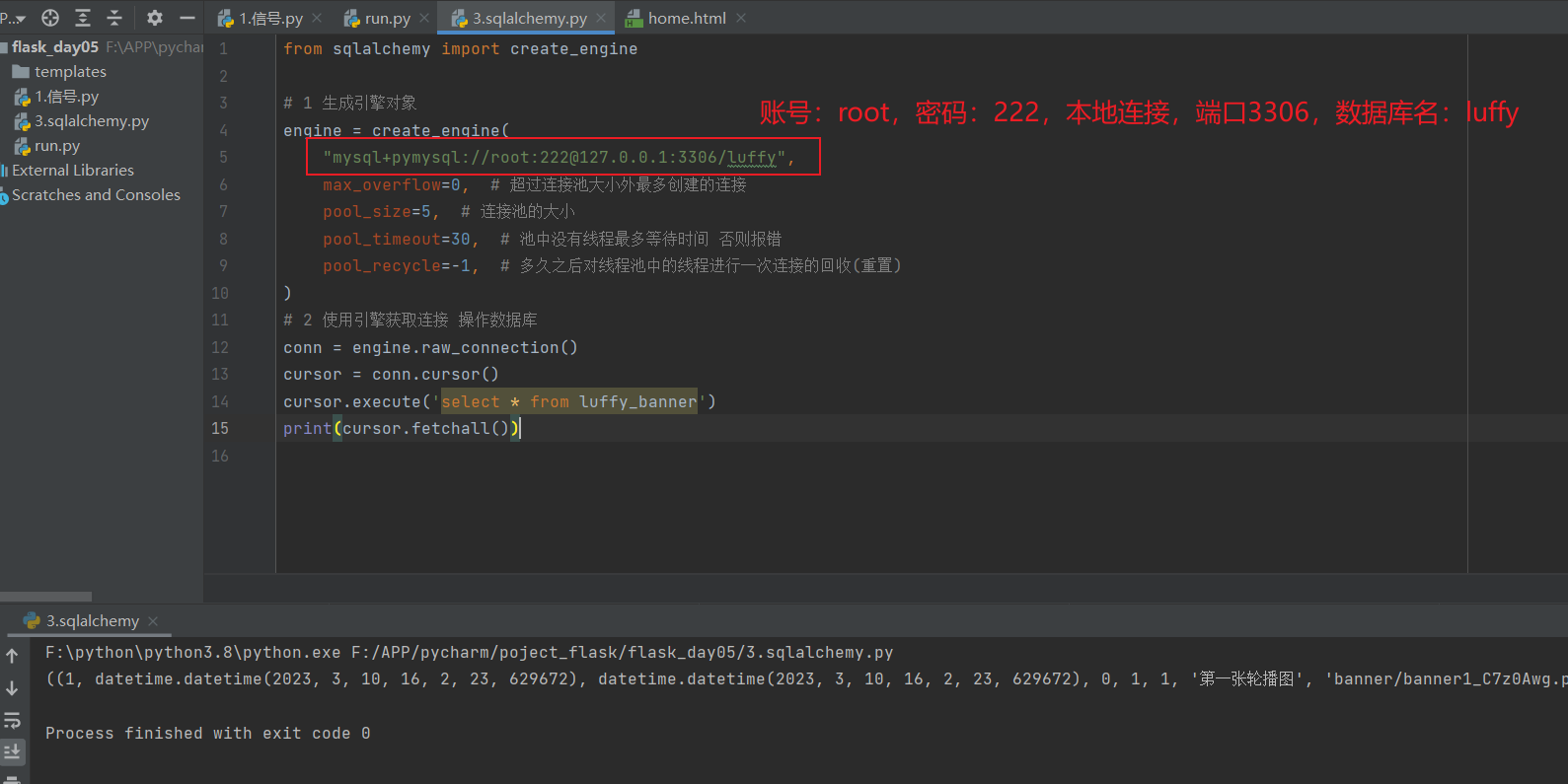
from sqlalchemy import create_engine
# 1 生成引擎对象
engine = create_engine(
"mysql+pymysql://root:222@127.0.0.1:3306/luffy",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池的大小
pool_timeout=30, # 池中没有线程最多等待时间 否则报错
pool_recycle=-1, # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
# 2 使用引擎获取连接 操作数据库
conn = engine.raw_connection()
cursor = conn.cursor()
cursor.execute('select * from luffy_banner')
print(cursor.fetchall())
4 使用sqlalchemy创建操作数据库
import datetime
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index
# 1 执行declarative_base 得到一个类
Base = declarative_base()
# 2 继承生成的Base类
class User(Base):
# 3 写字段
id = Column(Integer, primary_key=True) # 生成一列 类型是Integer 主键
name = Column(String(32), index=True, nullable=False) # name列varchar32 设置为普通索引 不可为空
email = Column(String(32), unique=True)
ctime = Column(DateTime, default=datetime.datetime.now)
# datetime.datetime.now不能加括号 家里括号 以后永远是当前时间
extra = Column(Text, nullable=True)
# 4 写表名 如果不写以类名为表名
__tablename__ = 'users' # 数据库表名称
# 5 建立联合索引 联合唯一
__table_args__ = (
UniqueConstraint('id', 'name', name='uix_id_name'), # 联合唯一
Index('ix_id_name', 'name', 'email'), # 索引
)
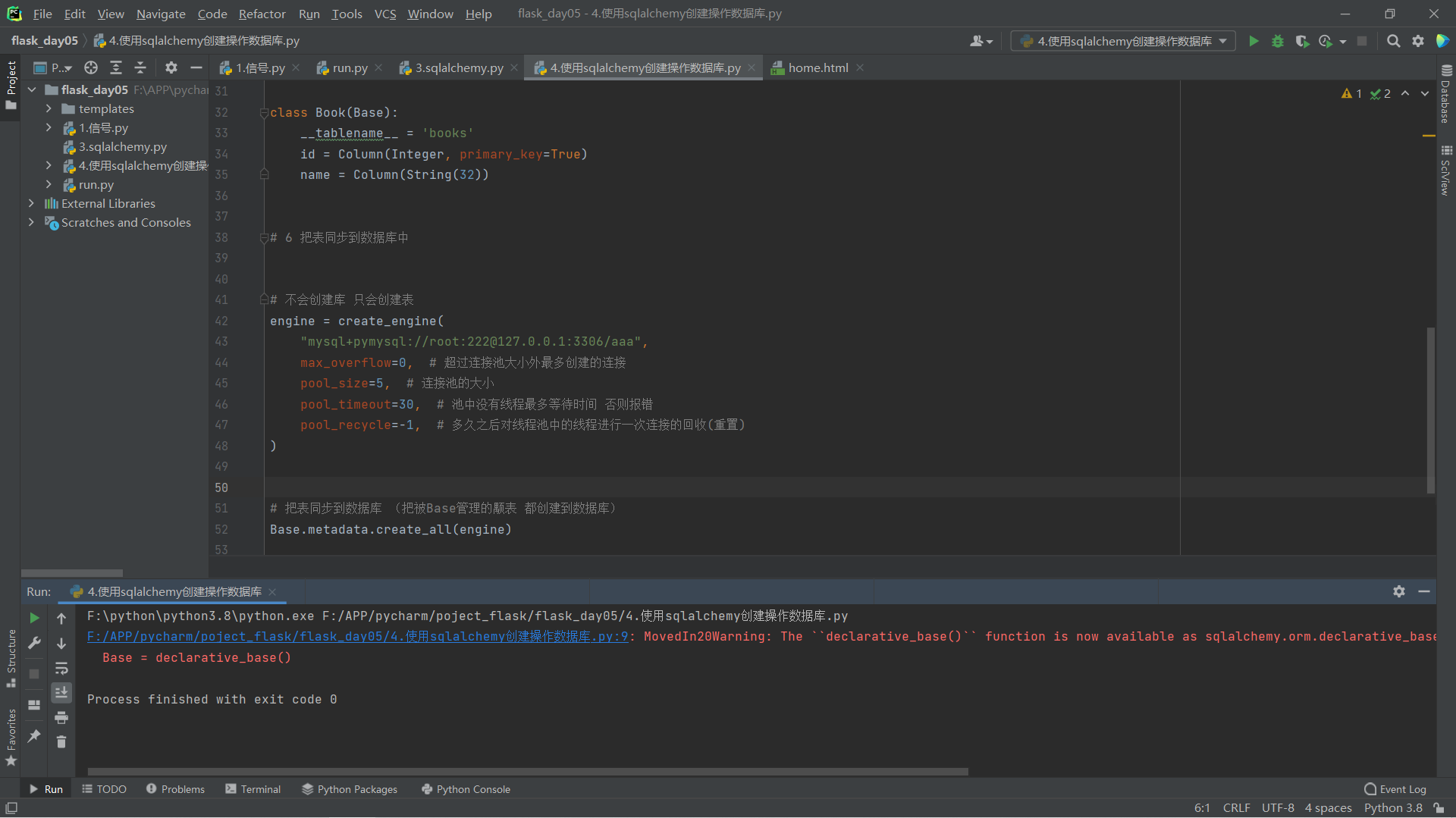
class Book(Base):
__tablename__ = 'books'
id = Column(Integer, primary_key=True)
name = Column(String(32))
# 6 把表同步到数据库中
# 不会创建库 只会创建表
engine = create_engine(
"mysql+pymysql://root:222@127.0.0.1:3306/aaa",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池的大小
pool_timeout=30, # 池中没有线程最多等待时间 否则报错
pool_recycle=-1, # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
# 把表同步到数据库 (把被Base管理的颙表 都创建到数据库)
Base.metadata.create_all(engine)
# 把所有表删除
# Base.metadata.drop_all(engine)
'''数据库aaa需要自己手动创建'''
补充
1 什么是猴子补丁 有什么用途
# python中的猴子补丁指的是在程序运行的过程之中去动态的更改属性的一种语法 因为python中变量或者说是对象的数据类型是根据值来动态赋予的 那么猴子补丁就是基于这个特点去实现属性更改的语法
# 猴子补丁的说法也是因为一开始它被叫做Guerrilla Patch 而Guerrilla的发音个gorllia是有点相似的 所以就这么一直的称呼这个语法
# 猴子补丁的作用:猴子补丁就是动态的去更改属性 它的实现一般就是用在类里面
# 下发实例中fun()函数的内容和功能假定是核心的 是无法去更改的 那么想要去让他实现不同的功能就可以再创建一个函数来实现它 因为参数self指向的都是类本身 所以它们之间是可以互相赋值的
# 最后monkey()函数变为了fun()函数的属性 这样调用fun()就相当于是调用了monkey()

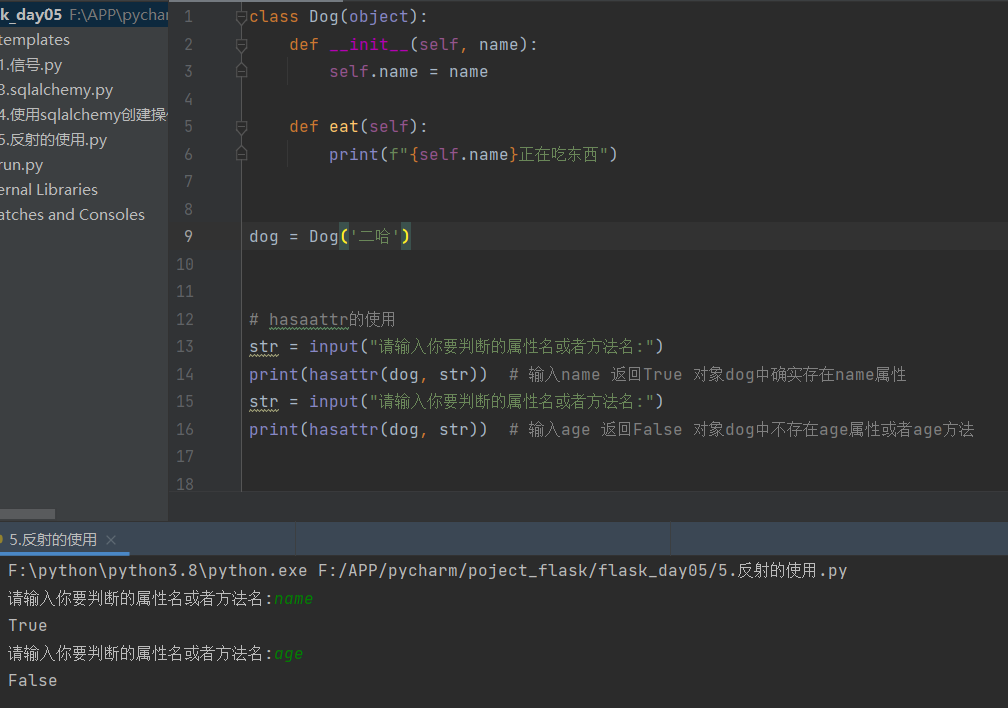
2 什么是反射 python中如何使用反射
'''
反射的定义:主要是应用于类的对象上 在运行时 将对象中的属性和方法反射出来
使用场景:可以动态的向对象中添加属性和方法 也可以动态的调用对象中的方法或者属性
反射的常用方法:
1 hasaattr(0bj, str)
判断输入的str字符串在对象obj中是否存在(属性或者方法) 存在返回True 否则返回False
2 getattr(obj, str)
将按照输入的str字符串在对象obj中查找 如找到同名属性 则返回该属性;如找到同名方法 则返回该方法的引用
想要调用此方法得使用getattr(obj, str)()进行调用
如果未找到同名的属性或者方法 则抛出异常
3 setattr(obj, name, value)
name为属性名或者方法名 value为属性值或者方法的引用
1) 动态添加属性 setattr(对象名,属性名,属性值)
2) 动态添加方法 首先定义一个方法 再使用setattr(对象名,想要定义的方法名,所定义方法)
4 delattr(obj, str)
将你输入的字符串str在对象obj中查找 如找到同名属性或者方法就进行删除
'''
class Dog(object):
def __init__(self, name):
self.name = name
def eat(self):
print(f"{self.name}正在吃东西")
dog = Dog('二哈')
# hasaattr的使用
# str = input("请输入你要判断的属性名或者方法名:")
# print(hasattr(dog, str)) # 输入name 返回True 对象dog中确实存在name属性
# str = input("请输入你要判断的属性名或者方法名:")
# print(hasattr(dog, str)) # 输入age 返回False 对象dog中不存在age属性或者age方法
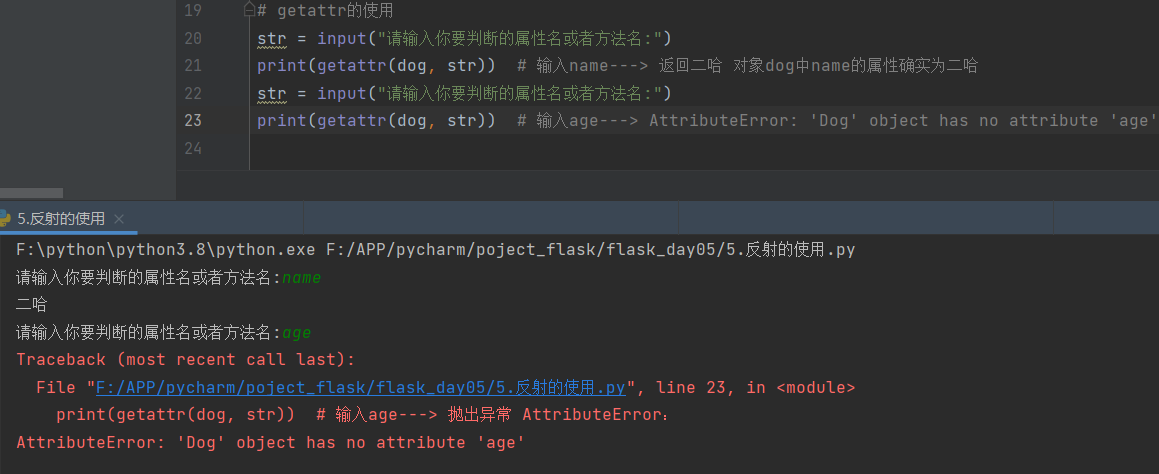
# getattr的使用
# str = input("请输入你要判断的属性名或者方法名:")
# print(getattr(dog, str)) # 输入name---> 返回二哈 对象dog中name的属性确实为二哈
# str = input("请输入你要判断的属性名或者方法名:")
# print(getattr(dog, str)) # 输入age---> AttributeError: 'Dog' object has no attribute 'age'
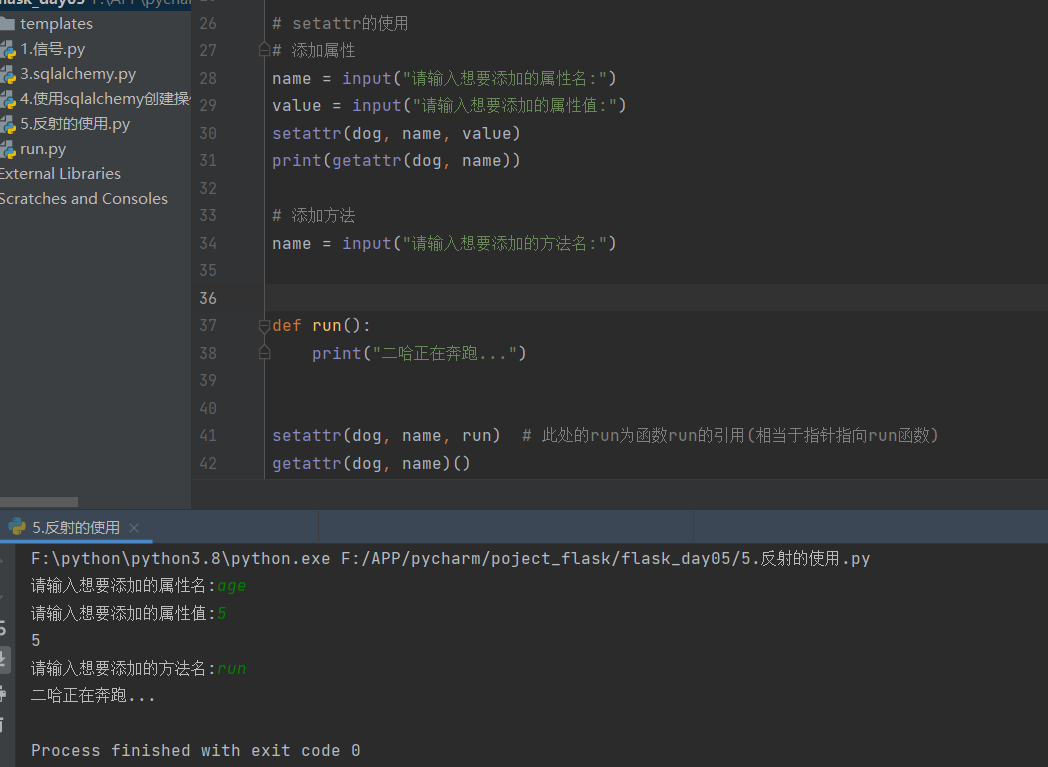
# setattr的使用
# 添加属性
# name = input("请输入想要添加的属性名:")
# value = input("请输入想要添加的属性值:")
# setattr(dog, name, value)
# print(getattr(dog, name))
#
# # 添加方法
# name = input("请输入想要添加的方法名:")
#
#
# def run():
# print("二哈正在奔跑...")
#
#
# setattr(dog, name, run) # 此处的run为函数run的引用(相当于指针指向run函数)
# getattr(dog, name)()
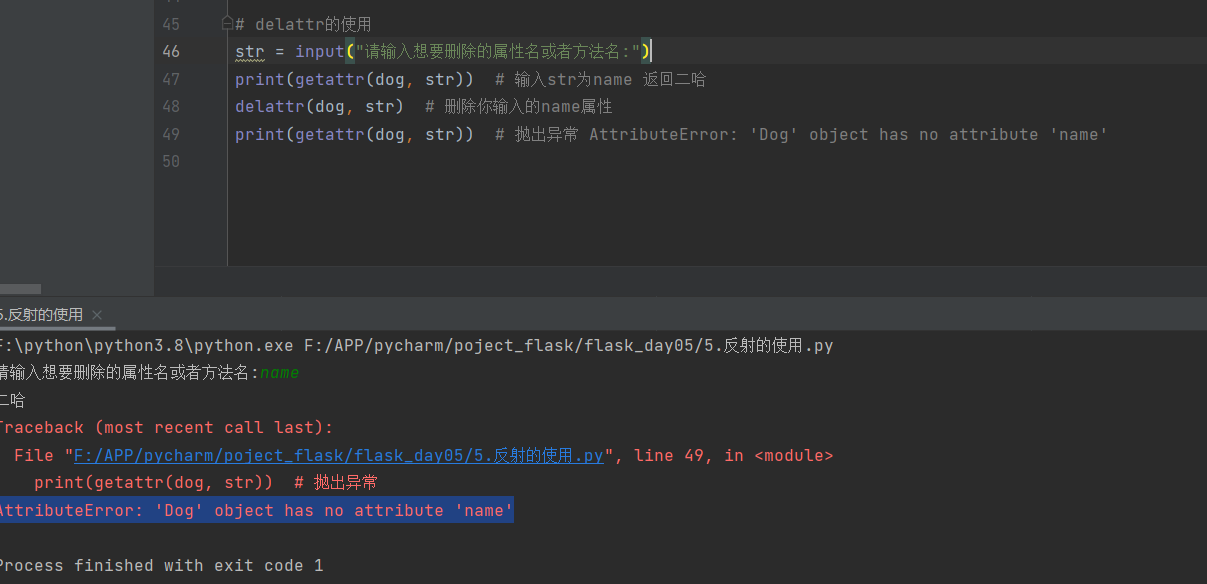
# delattr的使用
str = input("请输入想要删除的属性名或者方法名:")
print(getattr(dog, str)) # 输入str为name 返回二哈
delattr(dog, str) # 删除你输入的name属性
print(getattr(dog, str)) # 抛出异常 AttributeError: 'Dog' object has no attribute 'name'
3 http和https区别
# 1 http和https的介绍
超文本传输协议HTTP协议被用于Web浏览器和网站服务器之间传递信息 HTTP协议以明文方式发送内容 不提供任何方式的数据加密 如果攻击者截取了Web浏览器和网站服务器之间的传输报文 就可以直接读懂其中的信息 因此HTTP协议不适合传输一些敏感信息 比如:信用卡号 密码等支付信息
为了解决HTTP协议的这一缺陷 需要使用另一种协议:安全套接字层超文本传输协议HTTPS 为了数据传输的安全 HTTPS在HTTP的基础上加入了SSL/TLS依靠证书来验证服务器的身份 并为浏览器和服务器之间的通信加密
HTTP:是互联网上应用最为广泛的一种网络协议 是一个客户端和服务端请求和应答的标准(TCP) 用于从WWW服务器传输超文本到本地浏览器的传输协议 它可以使浏览器更加高效 使网络传输减少
HTTPS:是以安全为目标的HTTP通道 简单讲师HTTP的安全版 即HTTP下加入SSL层 HTTPS的安全基础是SSL 因此加密的详细内容就需要SSL
HTTPS协议的主要作用可以分为两种:一种是建立一个信息安全通道 来保证数据传输的安全;另一种就是确认网站的真实性
# 2 HTTP和HTTPS有什么区别?
HTTP协议传输的数据都是未加密的 也就是明文 因此使用HTTP协议传输隐私信息不安全 为了保证这些隐私数据能加密传输 于是网景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密 从而诞生了HTTPS。简单来说HTTPS协议是由SSL+HTTP协议构建的可进行加密传输,身份认证的网络协议 要比HTTP协议安全
HTTPS和HTTP的区别主要如下:
1 https协议需要ca申请证书 一般免费证书较少 因而需要一定费用
2 http是超文本传输协议 信息是明文传输 https则是具有安全性的ssl加密传输协议
3 http和https使用的是完全不同的连接方式 用的端口也不一样 前者是80 后者是443
4 http的连接很简单 是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输,身份认证的网络协议 比http协议安全
------------------分割线---------------------
# 3 HTTPS的工作原理
我们都知道HTTPS能够加密信息 以免敏感信息被第三方获取 所以很多银行网站或电子邮箱等等安全级别较高的服务都会采用HTTPS协议

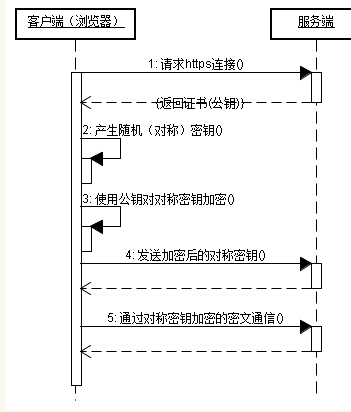
客户端在使用HTTPS方式与Web服务器通信时有以下几个步骤 如图所示
(1) 客户使用https的URL访问Web服务器 要求与Web服务器建立SSL连接
(2) Web服务器收到客户端请求后 会将网站的证书信息(证书中包含公钥)传送一份给客户端
(3) 客户端的浏览器与Web服务器开始写上SSL连接的安全等级 也就是信息加密的等级
(4) 客户端的浏览器根据双方同意的安全等级 建立会话秘钥 然后利用网站的公钥将会话秘钥加密 并传送给网站
(5) Web服务器利用自己的私钥解密出会话秘钥
(6) Web服务器利用会话秘钥与客户端之间的通信
# 4 HTTPS的优点
尽管HTTPS并非绝对安全 掌握根证书的机构 掌握加密算法的组织同样可以进行中间人形式的攻击 但HTTPS仍是现行架构下最安全的解决方案 主要有以下几个好处:
(1) 使用HTTPS协议可认证用户和服务器 确保数据发送到正确的客户机和服务器
(2) HTTPS协议是由SSL+HTTP协议构建的可进行加密传输,身份认证的网络协议 要比http协议安全 可防止数据在传输过程中不被窃取,改变 确保数据的完整性
(3) HTTPS是现行架构下最安全的解决方案 虽然不是绝对安全 但它答复增加了中间人攻击的成本
(4) 谷歌曾在2014年8月份调整搜索引擎算法 并称"比起同等HTTP网站 采用HTTPS加密的网站在搜索结果中的排名将会更高"
# 5 HTTPS的缺点
虽然说HTTPS有很大的优势 但其相对来说 还是存在不足之处:
(1) HTTPS协议握手阶段比较费时 会使页面加载时间延长近50% 增加10%到20%的耗电
(2) HTTPS连接缓存不如HTTP高效 会增加数据开销和功耗 甚至已有的安全措施也会因此而受到影响
(3) SSL证书需要钱 功能越强大的证书费用越高 个人网站 小网站没有必要一般不会用
(4) SSL证书通常需要绑定IP 不能在同一IP上绑定多个域名 IPV4资源不可能支撑这个消耗
(5) HTTPS协议的加密范围比较有限 在黑客攻击,拒绝服务攻击,服务器劫持等方面几乎起不到什么作用。最关键的 SSL证书的信用链体系并不安全 特别是在某些国家可以控制CA根证书的情况下 中间人攻击一样可行
# 6 http切换到https
如果需要将网站从http切换到https到底该如何实现呢?
这里需要将页面中所有的链接 例如js css 图片等链接都由http改为https。例如:http://www.baidu.com改为https://www.baidu.com
BTW 这里虽然将http切换为https 还是建议保留http。所以我们在切换的时候可以做http和https的兼容 具体实现方式是 去掉页面链接中的http头部 这样就可以自动匹配http头和https头。例如:将http://www.baidu.com改为//www.baidu.com。然后当用户从http入口访问页面时 页面就是http 如果用户是从https的入口进入访问页面 页面就是https的。