单向链表与项目实战
单链表
单链表是一种链式存取的数据结构,用一组地址任意的存储单元存放线性表中的数据元素。链表中的数据是以结点来表示的,每个结点的构成:元素(数据元素的映像)+ 指针(指示后继元素存储位置),元素就是存储数据的存储单元,指针就是连接每个结点的地址数据。
以“结点的序列”表示线性表称作线性链表(单链表),单链表是链式存取的结构。链接方式存储的线性表简称为链表(Linked List)。
链表的具体存储表示为:
- 用一组任意的存储单元来存放线性表的结点(这组存储单元即可以是连续的,也可以是不连续的)
- 链表中结点的逻辑次序和物理次序不一定相同。为了能正确表示结点间的逻辑关系,在存储每个结点值的同时,还必须存储指示其后继结点的地址(或位置)信息(称为指针pointer)或链(link)。
| data | next |
|---|
-
结点结构:
data域——存放结点值的数据域
next域——存放结点的直接后继的地址(位置)的指针域(链域)
链表通过每个结点的链域将线性表的n个结点按其逻辑顺序链接在一起,每个结点只有一个链域的链表称为单链表(Single Linked List)
-
头指针head和终端结点
单链表中每个结点的存储地址是存放在其前驱结点next域中,而开始结点无前驱,故应设头指针head指向开始结点。链表由头指针唯一确定,单链表可以用头指针的名字来命名。
终端结点无后继,故终端结点的指针域为空,即NULL。
-
C语言结点结构的定义
typedef char DataType;//假设结点的数据域类型为字符 typedef struct node{//结点类型定义 DataType data;//结点的数据域 struct node *next;//结点的指针域 }ListNode; typedef ListNode *LinkList; ListNode *p; LinkList head;
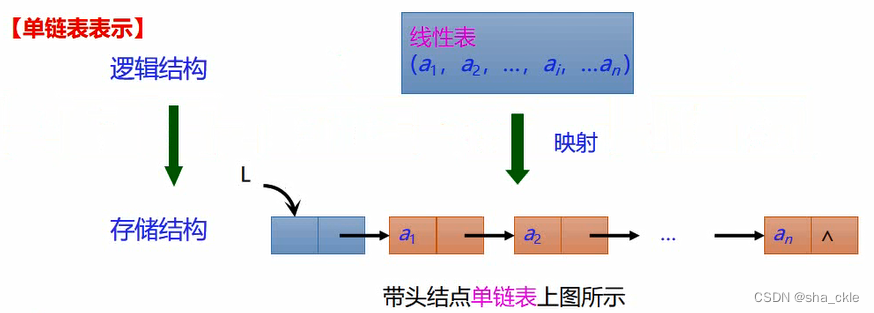
单链表增加一个头结点的优点如下:
-
第一个结点的操作和表中其他结点的操作相一致,无需进行特殊处理。
-
无论链表是否为空,都有一个头结点,因此空表和非空表的处理也就统一了。
-
插入结点s操作:
- s->next = p->next;
- p->next = s;
-
删除结点操作:
- p->next = p->next->next;
项目实战案例
#include "stdafx.h"
#include<stdio.h>
#include<stdlib.h>
#incldue<string.h>
//定义结点类型:数据域、指针域
struct sNode{
int data;
struct sNode *next;
};
//创建单链表(表头)
struct sNode *CreateListFunc()
{
struct sNode *headNode = (struct sNode*)malloc(sizeof(struct sNode));
headNode->next = NULL;
return headNode;
}
//生成单链表结点
struct sNode*CreateNodeFunc(int data)
{
//生成新的结点
struct sNode *newNode = (struct sNode*)malloc(sizeof(strucr sNode));
//初始化新结点数据域和指针
newNode->data = data;
newNode->next = NULL;
return newNode;
}
//打印输出链表中的结点(遍历结点)
void PrintListFunc(struct sNode *headNode)
{
struct sNOde *pTemp = headNode->next;
while(pTemp){
printf("%d\t",pTemp->data);
pTemp = pTemp->next;
}
}
//插入结点
void InsertNodeHead(struct sNode *headNode, int data)
{
struct sNode *insretNode = CreateNodeFunc(data);//调用创建新结点的函数
insretNode->next = headNode->next;
headNode->next = insretNode;
}
//删除结点
void DelteNodeFunc(struct sNode *headNode, int posData)
{
struct sNode *posNode = headNode->next;
struct sNode *posNodeFront = headNode;
if(posNode == NULL)
print("\n单链表为空.\n\n");
else
{
while(posNode->data != posData)
{
posNodeFront = posNode;
posNode = posNodeFront->next;
if(posNode == NULL)
{
print("\n无法找到指定的位置.\n");
return;
}
}
posNodeFront->next = posNode->next;
free(posNode);
}
}
int _tmain(int argc, _TCHAR* argv[])
{
//创建一个链表list
struct sNode *list = CreateListFunc();
print("\n【单链表操作(插入\删除\输出)】\n");
PrintListFunc(list);//打印输出链表
printf("初始化单链表操作:\n");
InsertNodeHead(list,55);
InsertNodeHead(list,66);
InsertNodeHead(list,77);
InsertNodeHead(list,88);
InsertNodeHead(list,99);
PrintListFunc(list);
//删除单链表中的结点操作
print("\n删除单链表中的结点操作:\n");
DeleteNodeFunc(list,77);
printListFunc(list);
printf("\n");
return 0;
}
双向链表与项目实战
双向链表
双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。一般我们都构造双向循环链表。
在线性表的链式存储结构中,每个物理结点增加一个指向后继结点的指针域和一个指向前驱结点的指针域——>双链表。
双链表的优势:
1. 从任一结点出发可以快速找到其前驱结点和后继结点
2. 从任一结点出发可以访问其他结点。
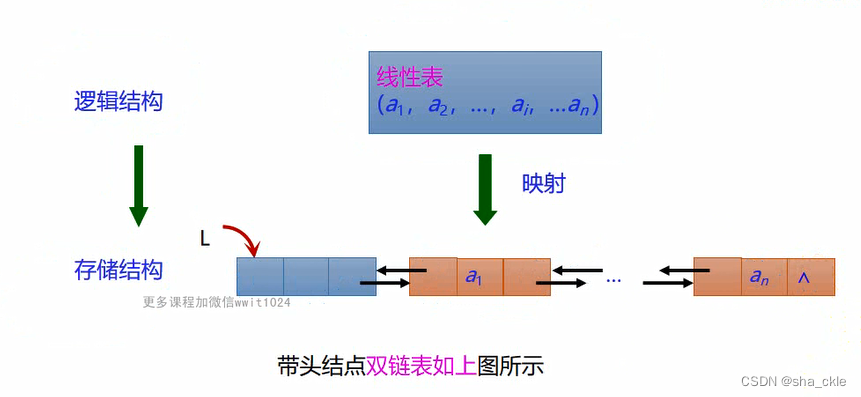
双链表的定义方法和单链表类型,其结点类型DLinkNode定义如下:
typedef struct DNode //双链表结点类型
{
ElemType data;
struct DNode *prior; //指向前驱结点
struct DNode *next; //指向后继结点
}DLinkNode;
- 双向链表插入操作:在*P结点之后插入结点*s
- s->next = p -> next;
- p->next->prior = s;
- s->prior = p;
- p->next = s;
- 双向链表删除操作:删除*p结点之后的一个结点
- p->next->next->piror = p;
- p->next = p->next->next
项目实战
#include"stdafx.h"
#include<stdio.h>
#include<stdlib.h>
//定义双向链表结点
typedef struct DLNode
{
int iNum;//数据域
struct DLNode *piror;
struct DLNode *next;
}DLNodes, *PDLNodes;
//插入结点(头插法)
void list_insert_head(PDLNodes *pphead, PDLNode *pptail, int i)
{
PDLNodes pnew;
pnew = (PDLNode)calloc(1, sizeof(DLNode));
pnew->iNum = i;
if(*pptail == NULL)//如果链表为空
{
*pphead = pnew;
*pptail = pnew;
}
else
{
pnew->next = *pphead;//新节点的next成员指向原有链表头
(*pphead)->prior = pnew; //新结点的prior指向原有链表头
*pphead = pnew;//新结点称为新的链表头
}
}
//打印输出双向链表结点
void lise_print_func(PDLNode phead, PDLNode ptail)
{
PDLNode pcur = phead;//将头指针给当前指针pcur
printf("\n顺序输出双向链表的所有结点:\n");
while(pcur != NULL)
{
printf("%d\t", pcur->iNum);
pcur = pcur->next;
}
pcur = ptail;//将尾指针赋给当前指针pcur
printf("\n逆序输出双向链表的所有结点:\n");
while(pcur != NULL)
{
printf("%d\t", pcur->iNum);
pcur = pcur->prior;
}
}
//删除结点
void list_delete_func(PDLNodes *pphead, PDLNodes *pptail, int i)
{
PDLNodes pcur = *pphead;
PDLNodes pbefore = *pphead;
if(NULL == *pptail)//证明链表为空
{
printf("\n双向链表为空");
}
else if(i == (*pphead)->iNum) //如果要删除第一个结点(此时可能只剩下一个结点)
{
(*pphead)->next->prior = (*pphead)->prior;//下一个结点的piror指向原有头结点的prior
*pphead = (*pphead)->next;//头指针要指向下一个结点
free(pcur);//释放原有头结点的内存
if(&pphead == NULL) //如果删除之后链表为空
{
*pptail = NULL;
}
}
else//如果不等于第一个结点
{
while(NULL != pcur) //如果pcur没有走出最后一个结点
{
if(i == pcur->iNum)
{
pcur = pcur->next;
pbefore->next = pcur;
pcur->prior = pbefore;
return ;
}
else
{
pbefore = pcur;
pcur = pcur->next;
}
}
if(NULL == pcur)//如果执行到最后
{
printf("\n证明你要删除的数据结点不存在");
}
}
}
//查找结点
void list_find_func(PDLNodes *pphead, PDLNode **pptail ,int i)
{
PDLNode pcur = *pphead;
PDLNode pbefore = *pptail;
if(NULL == *pptail)//证明双向链表为空
{
printf("\n双向链表为空\n");
}
else
{
while(NULL != pcur) //只要不是最后
{
if(i == pcur->iNum)
{
printf("查询成功:你要查找的数据存在.\n");
return;
}
else
{
pbefore = pcur;
pcur = pcur->next;
}
}
if(NULL == pcur)//执行到最后
{
printf("证明你要查找的数据结点不存在\n");
}
}
}
int _tmain(int argc, _TCHAR* argv[])
{
int i;
PDLNode phead = NULL;
PDLNode ptail = NULL;
//插入结点
printf("\n请输入你要插入的结点:");
while(scanf("%d", &i) != EOF)
{
//调用插入结点函数
list_insert_head(&phead, &ptail, i);
}
//输出操作
list_print_func(phead, ptail);
//删除结点
printf("\n请输入你要删除结点的数据:");
while(scanf("%d",&i) != EOF)
{
//调用删除结点的函数
list_delete_func(&phead, &ptail, 4);
printf("\n删除之后链表的结果为:");
list_print_func(phead, ptail);
}
//查找结点
printf("\n请输入要查找的结点:");
while(scanf("%d", &i) != EOF)
{
//调用查找函数
lise_find_func(phead, ptail, i);
}
return 0;
}
循环链表与项目实战
循环链表
循环单链表:将表中尾结点的指针域改为指向表头结点,整个链表形成一个环。由此从表中任一结点出发均可找到链表中其他结点。
循环双链表:形成两个环
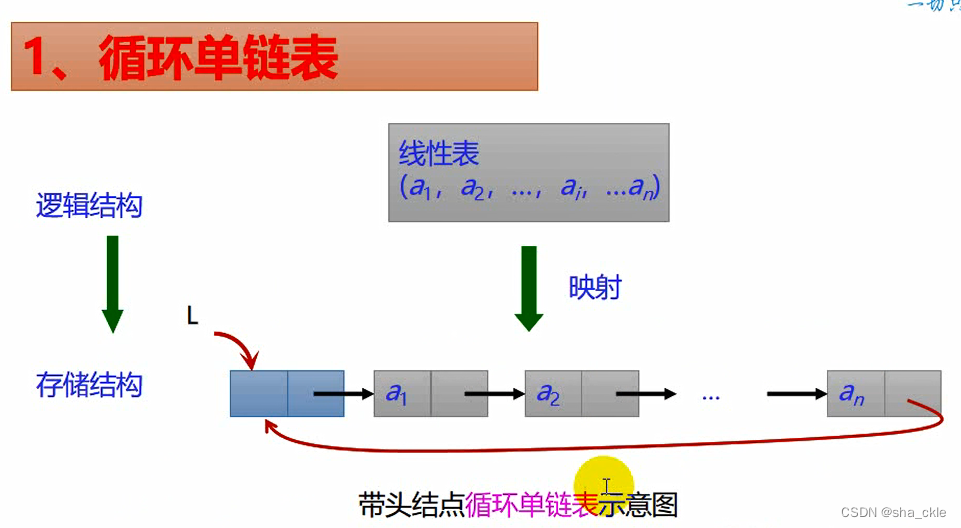
与非循环单链表相比,循环单链表
- 链表中没有空指针域
- p所指结点为尾结点的条件:p->next == L
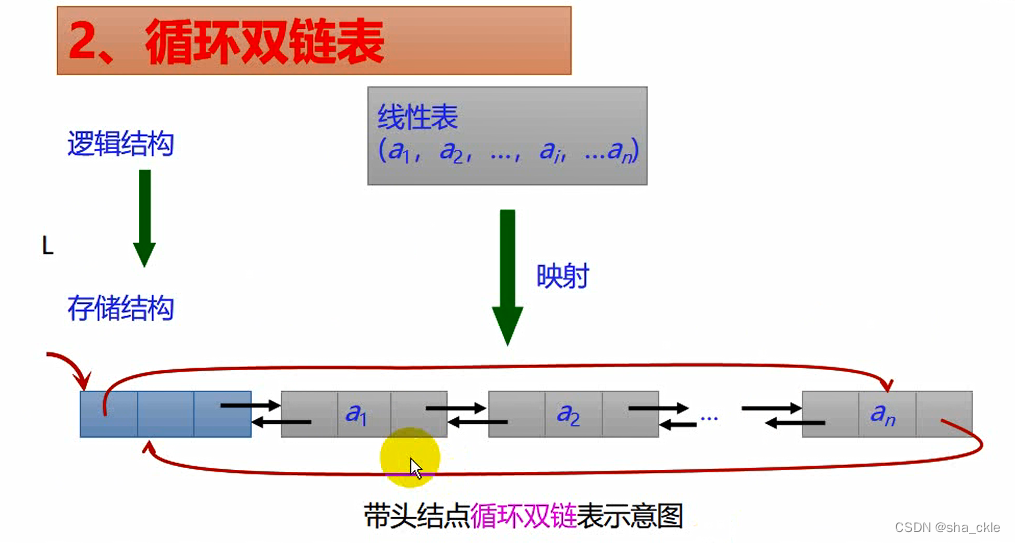
与非循环双链表相比,循环双链表:
- 链表中没有空指针域
- p所指结点为尾结点的条件:p->next == L
- 一步操作即L->prior可以找到尾结点
项目实战
#include"stdafx.h"
#include<stdio.h>
#include<stdlib.h>
#define ERROR 0
#define OK 1
typedef int ElemType;
//定义结点
typedef struct CLinkNode
{
ElemType data;
struct CLinkNode *next;
}CLinkNode, *CLinkList;
//初始化循环链表
int InitClinkList(CLinkList *list)
{
if(NULL == list)
{
return ERROR;
}
int data = 0;
CLinkList *target = NULL;
ClinkList *head_node = NULL;
printf("请输入结点数据,0代表初始化结束\n");
while(1)
{
scanf("%d", &data);
if(0 == data)
{
break;//退出循环标志
}
if(NULL == *list)
{
CLinkList *head = (CLinkList*)malloc(sizeof(CLinkNode));
if(head == NULL)//分配结点空间失败
exit(0);
*list = head;//链表指向头结点
CLinkNode *node = (CLinkNde*)malloc(sizeof(CLinkNode));
if(node == NULL)
exit(0);
node->data = data;
node->next = head;
head->next = node;
}
else
{
for(target = (*list)->next; target->next != *list; target = target->next);
head_node = target->next;
CLinkNode *node = (CLinkNode*)malloc(sizeof(CLinkNode));
if(node == NULL)
exit(0);
node->data = data;
node->next = head_node;
target->next = node;//将新节点插入尾部
}
}
return OK;
}
//输出循环链表结点数据
int ShowCLinkListFunc(CLinkList list)
{
if(list == NULL)
return ERROR;
CLinkNode *target = NULL;
printf("\n循环链表结束元素数据如下:\n");
for(target = list-> next; target != list; target = target->next)
printf("%d\t", target->data);
printf("\n");
return OK;
}
int InsertCLinkListFunc(CLinkList list, int loc, ElemType data)
{
if(list == NULL || loc < 1)
return ERROR;
int i = 1;
CLinkNode *node = list;
while(node->next != list && i < loc)
{
node = node->next;
i++;
}
if(loc == i)
{
CLinkNode *new_node = (CLinkNode*)malloc(sizeof(CLinkNode));
if(new_node == NULL)
exit(0);
new_node->data = data;
new_node->next = node->next;//新结点指针域,指向前驱结点的后继结点
node->next new_node;//将新节点插入到链表
}
else
{
return ERROR;
}
return OK;
}
void DelteCLinkList(CLinkList list, int loc, ElemType *data)
{
if(list == NULL || loc < 1)
return ERROR;
int i = 1;
CLinkNode *node = list;
while(node->next != list && i < loc)
{
node = node->next;
i++;
}
if(i == loc && node->next != list)
{
CLinkNode *del_node = node->next;//第loc结点位置
*data = del_node->data;//返回删除结点的数据域
node->next = del_node->next;
free(del_node);//释放结点空间
}
}
int _tmain(int argc, _TCHAR* argv[])
{
int iFlags = 0;
CLinkList list = NULL;
while(1)
{
printf("*******************\n");
printf("*******************\n");
printf("*1.初始化循环链表 *\n");
printf("*2.插入结点元素 *\n");
printf("*3.删除结点元素 *\n");
printf("*******************\n");
printf("*******************\n");
printf("请输入选择操作项:");
scanf("%d", &iFlags);
if(iFlags == 0)
break;
if(iFlags == 1)
{
list = NULL:
InitClinkList(&list);
ShowCLinkListFucc(list);
}
if(iFlags == 2)
{
int loc = 0;
int data = 0;
printf("请输入要插入元素的位置和数据:\n");
scanf("%d", &loc);
scand("%d", &data);
//调用插入结点操作
InsertCLinkListFunc(list, loc, data);
ShowCLinkListFucc(list);
}
if(iFlags == 3)
{
int loc = 0;
int data = 0;
printf("请输入要删除元素的位置:\n");
scanf("%d", &loc);
//调用插入结点操作
DelteCLinkList(list, loc);
ShowCLinkListFucc(list);
}
}
return 0;
}
栈与队列
栈的基础知识
- 栈定义:只能在表的一端(栈顶)进行插入和删除运算的线性表。
- 逻辑结构:与线性表相同,仍为一对一关系。
- 存储结构:用顺序表或链栈存储均可,但以顺序栈更常见。
- 运算规则:只能在栈顶运算,且访问结点时依照后进先出(LIFO)或先进后出(FILO)的原则。
- 实现方式:关键是编写入栈和出栈函数,具体实现依顺序栈和链栈的不同而不同基本操作有入栈、出栈、读栈顶元素值、建栈、判断栈满、栈空等。
栈的表示和操作
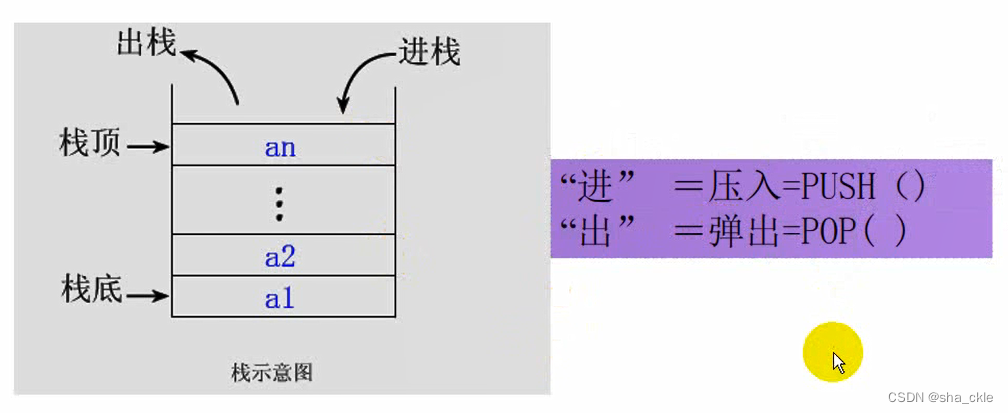
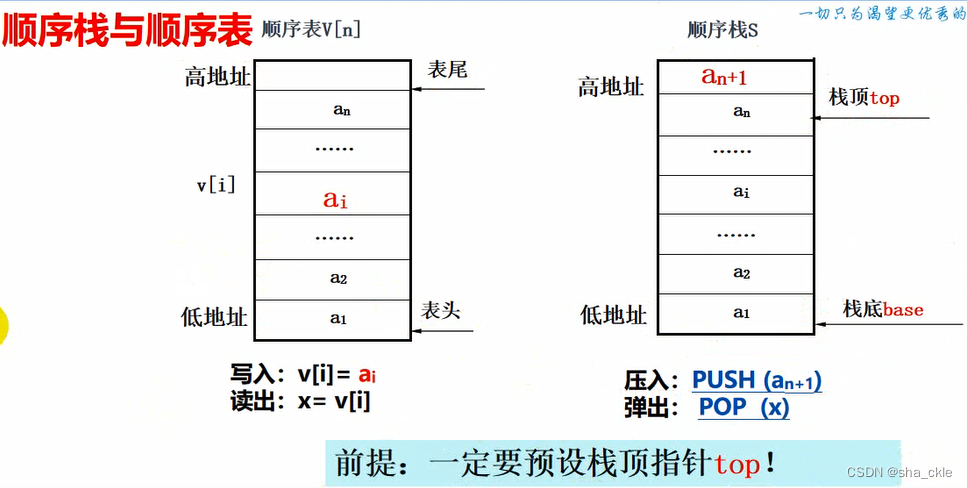
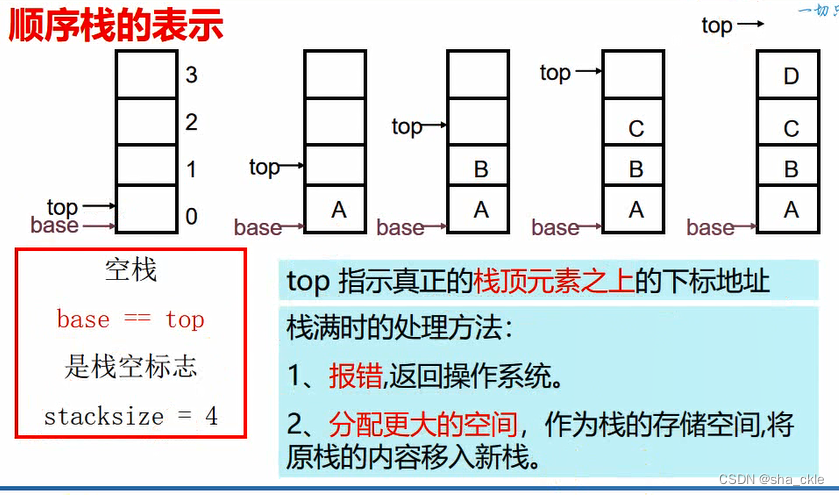
顺序栈的表示:
define MAXSIZE 100
typedef struct
{
SElemType *base;
SElemType *top;
int stacksize;
}SqStack;
顺序栈初始化
- 构造一个空栈
- 步骤:
- 分配空间并检查空间是否分配失败,若失败则返回错误
- 设置栈底和栈顶指针 s.top = s.base;
- 设置栈大小
Status InitStack(SqStack &s)
{
S.base = new SElemType[MAXSIZE];
if(!S.base)
return OVERFLOW;
S.top = S.base;
S.stackSize = MAXSIZE;
return OK;
}
判断顺序栈是否为空
bool StackEmpty(SqStack S)
{
if(S.top == S.base)
return true;
else
return false;
}
求顺序栈的长度
int StackLength(SqStack S)
{
return S.top - S.base;
}
清空顺序栈
Statuw ClearStack(SqStack S)
{
if(S.base)
S.top = S.base;
return OK;
}
销毁顺序栈
Statuw DestoryStack(SqStack &S)
{
if(S.base)
{
delete S.base;
S.stacksize = 0;
S.base = S.top = NULL;
}
return OK;
}
顺序栈进栈
-
判断是否栈满,若满则出错
-
元素e压入栈顶
-
栈顶指针加1
Status Push(SqStack &s, SElemType e)
{
if(S.top - S.base == S.stacksize)//栈满
reutrn ERROR;
*S.top++ = e;//*S.top = e; S.top++;
return OK;
}
顺序栈出栈
- 判断是否栈空,若空则出错
- 获取栈顶元素e
- 栈顶指针减1
Status Pop(SqStack &s, SElemType &e)
{
if(S.top == S.base)//栈空
return ERROR;
e = *--S.top;
return OK;
}
取顺序栈栈顶元素
- 判断是否为空栈,若空则返回错误
- 否则通过栈顶指针获取栈顶元素
Status GetTop(SqStack S, SElemType &e)
{
if(S.top == S.base)
return ERROR;
e = *(S.top - 1);
return OK;
}
#include<iosteam>
using namespce std;
#define MAX_SIZE 8//数组大小
//定义栈类型
struct sStack{
int top;
int iStack[MAX_SIZE];
};
typedef struct sStack Stack;
//初始化栈
void InitStackFunc(Stack *sPtr)
{
sPtr->top = 0;
}
//判断栈是否已经满
bool StackFullFunc(Stack *sPtr)
{
if(sPtr->top < MAX_SIZE)
return false;
else
return true;
}
//判断栈是否为空
bool StackEmptyFunc(Stack *sPtr)
{
if(sPtr->top == 0)
return true;
else
return false;
}
//获取栈顶元素的值
int GetStackTopFunc(Stack *sPtr)
{
return sPtr->iStack[sPrt->top -1];
}
//入栈
void PushStackFunc(Stack *sPtr, int items)
{
if(StackFullFunc(sPtr))
cout << "栈已满,不能入栈" << endl;
else
{
sPtr->iStack[sPtr->top] = items;
sptr->top++;
}
}
//出栈
int PopFunc(Stack *sPtr)
{
if(StackEmptyFunc(sPtr))
{
cout << "栈为空,不能进行出栈!" << endl;
return -1;
}
else
return sPtr->iStack[--sPtr->top];
}
//求栈长度
int StackSizeFunc(Stack *sPtr)
{
if(sPtr->top == 0)
return 0;
else
return sPtr->top;
}
//清空栈
void ClearStackFunc(Stack *sPtr)
{
sPtr->top = 0;
}
int main()
{
Stack *sPtr = (Stack*)malloc(sizeof(Stack));
//初始化栈
InitStackFunc(sPtr);
PushFunc(sPtr, 100);
PushFunc(sPtr, 90);
PushFunc(sPtr, 80);
PushFunc(sPtr, 70);
PushFunc(sPtr, 60);
PushFunc(sPtr, 50);
PushFunc(sPtr, 40);
PushFunc(sPtr, 30);
PushFunc(sPtr, 20);
PushFunc(sPtr, 10);
//出栈
cout << "获取当前栈顶元素的值为:" << GetStackTopFunc(sPtr) << endl;
cout << "当前栈顶指针为:" << sPtr->top << endl;
cout << "获取当前栈长度为:" << stackSizeFunc(sPtr) << endl;
cout << "栈顶出队:" << PopFunc(sPtr) << endl;
cout << "获取当前栈长度为:" << stackSizeFunc(sPtr) << endl;
ClearStackFunc(sPtr);
cout << "清空栈之后的长度为:" << stackSizeFunc(sPtr) << endl;
return 0;
}
队列的基本知识
队列是一种先进先出(FIFO)的线性表,在表一端插入,在另一端删除。
- 定义:只能在表的一端(队尾)进行插入,在另一端(队头)进行删除运算的线性表。
- 逻辑结构:与线性表相同,仍为一对一关系。
- 存储结构:用顺序队列或链对村粗均可。
- 运算规则:先进先出(FIFO)。
- 实现方式:关键是编写入队和出队函数,具体实现顺序队或链对的不同而不同。
栈、队列与一般线性表的区别:
栈、队列是一种特殊(操作受限)的线性表,区别:仅在与运算规则不同。
| 一般线性表 | 栈 | 队列 | |
|---|---|---|---|
| 逻辑结构 | 一对一 | 一对一 | 一对一 |
| 存储结构 | 顺序表、链表 | 顺序栈、链栈 | 顺序队、链队 |
| 运算规则 | 随机、顺序存取 | 后进先出 | 先进先出 |
队列的表示和操作
队列的抽象数据类型
ADT Queue{
数据对象:D = {ai|ai ∈ ElemSet , i = 1, 2, 3, ..., n, n ≥ 0}
数据关系:R1= {<ai-1, ai>|ai-1, ai ∈ D, i = 1, 2, 3, ..., n}约定a1端为队列头,an端为队列尾
}
ADT Queue{
1. InitQueue(&Q) //构造空队列
1. DestroyQueue(&Q) //销毁队列
1. ClearQueue(& S) //清空队列
1. QueueEmpty(S) //判空,空——TRUE
1. QueueLength(Q) //取队列长度
1. GetHead(Q, &e) //取对头元素
1. EnQueue(&Q, e) //入队列
1. DeQueue(&Q, &e) //出队列
1. QueueTraverse(Q, visit()) //遍历
}ADT Queue
队列的顺序表示——用以为数组base[M]
define M 100 //最大队列长度
Typedef struct{
QElemType *base;//初始化的动态分配存储空间
int front; //头指针
int rear; // 尾指针
}SqQueue;
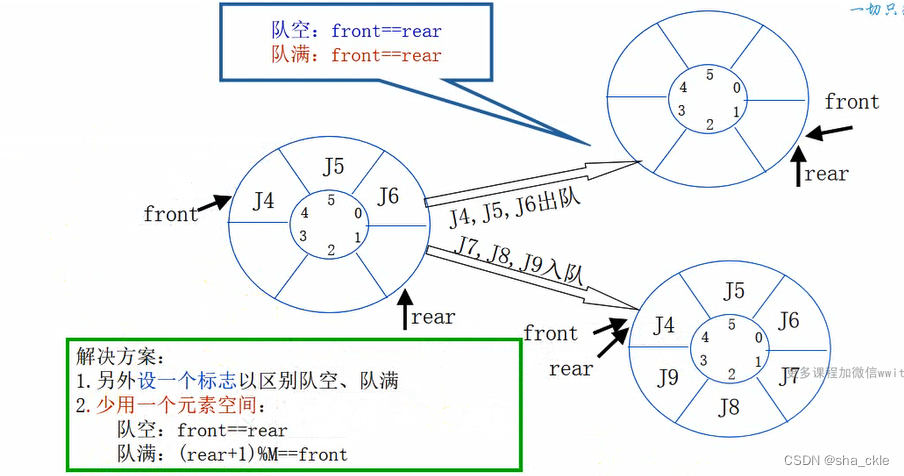
空队标志:front == rear;
入队:base[rear++] = x;
出队:x = base[front++];
存在的问题:设大小为M
front = 0 rear = M时,再入队——真溢出
front ≠ 0 rear = M时,再入队——假溢出
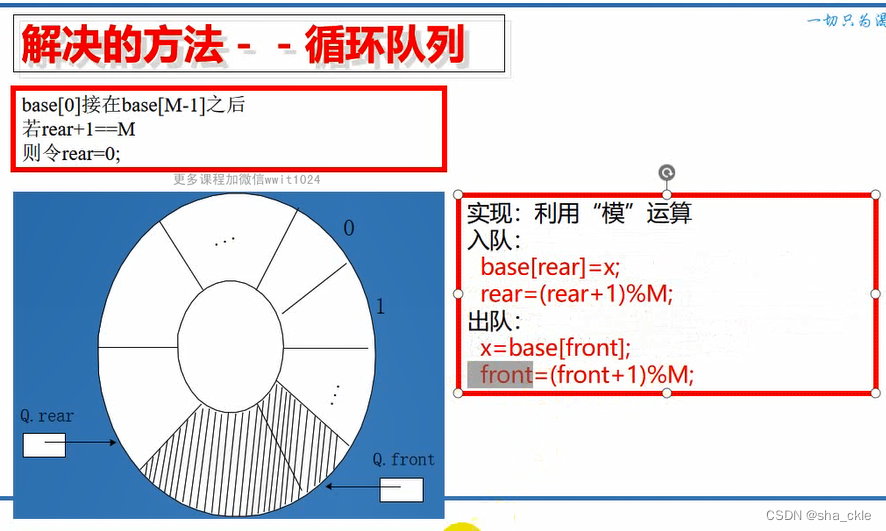
#include"stdafx.h"
#include<stdio.h>
#include<stdlib.h>
#define true 1
#define false 0
typedef struct queue{
int Elem[100];
int rear;
int front;
}*SQueue,Queue;
void EnEmpty(SQueue ptr);
int IsEmpty(SQueue ptr);
void EnEmpty(SQueue ptr)
{
ptr->front = 0;
prt->rear = -1;
printf("OK");
}
int IsEmpty(SQueue ptr)
{
if(ptr->rear == -1 || ptr->front - 1 == ptr->rear)
return true;
else
return false;
}
void GetFrontFunc(SQueue ptr)
{
if(IsEmpty(ptr))
printf("该队列不存在.\n");
else
printf("队列元首元素为:%d\n",ptr->Elem[ptr->front])
}
void InsertQueue(SQueue ptr)
{
int num, i = 0; record = 0;
printf("请输入您想要插入队列的元素个数:");
scanf("%d", &num);
for(i ; i < num ; i++)
{
printf("输入第%d个元素", i + 1);
if(++ptr->rear <= 9)
{
if(ptr->rear == ptr->front && record == 1)
{
printf("数据溢出!\n");
exit(1);
}
else if(ptr->rear == ptr->front)
{
record++;
}
scanf("%d",ptr->Elem[ptr->rear]);
}
else
{
ptr->rear -= 0;
scanf("%d",&ptr->Elem[ptr->rear];
if(ptr->rear == ptr->front)
{
printf("数据溢出!\n");
exit(1);
}
}
}
}
//出队
void DeleteQueue(SQueue ptr)
{
if(IsEmpty(ptr))
{
printf("该队列不存在.\n");
ptr->front = 0;
}
else
{
printf("队列为:");
do
{
printf("%d——>",ptr->Elem(ptr->front));
prt->front++;
}while(!IsEmpty(ptr));
printf("\n");
}
}
int _tmain(int argc, _TCHAR* argv[])
{
int input;
SQueue ptr;
ptr = (SQueue)malloc(sizeof(Queue));
ptr->front = 0;
ptr->rear = -1;
while(1)
{
printf("1.插入队列\n");
printf("2.获取队列\n");
printf("3.退出队列\n");
scanf("%d", &input);
switch(input)
{
case 1:
InsertQueue(ptr);
break;
case 2:
DeleteQueue(ptr);
break;
case 3:
exit(0);
default:
printf("Input Error.\n");
break;
}
}
return 0;
}
树与二叉树遍历算法
数与二叉树基础知识
逻辑结构:
- 集合——数据元素键除“同属一个集合”外,无其他关系
- 线性结构——一个对一个,如线性表、栈、队列
- 属性结构——一个对多个,如树
- 图形结构——多个对多个,如图
【树和二叉树的定义】
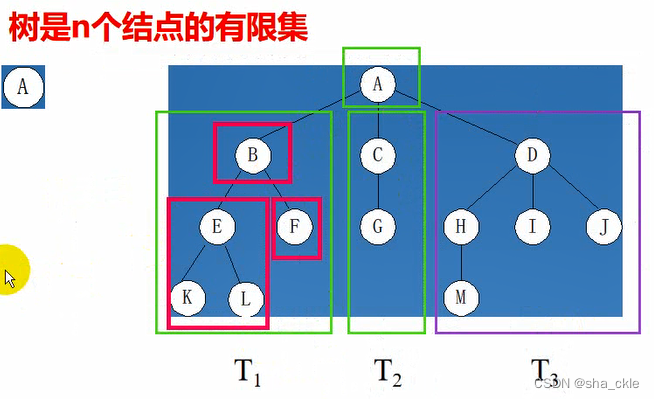
树的定义:树(tree)是n(n≥0)个结点的有限集,它或是空树(n = 0);或是非空树,对于非空树T:1. 有且仅有一个称之为根的结点;2. 除根节点以外的其余结点可分为m(m>0)个互不相交的有限集T1、T2、...、Tm,其中每一个集合本身又是一棵树,并且称为根的子树(SubTree)。
【基本术语】
根——即根结点(没有前驱)
叶子——即终端结点(没有后继)
森林——指m颗不相交的树的集合(例如删除A后的子树个数)
有序树——结点各子树从左至右有序,不能互换(左为第一)
无序数——结点各子树可互换位置
双亲——即上层的那个结点(直接前驱)
孩子——即下层结点的子树的根(直接后继)
兄弟——同一双亲下的同层结点(孩子之间互称兄弟)
堂兄弟——即双亲位于同一层的结点(但并非同一双亲)
祖先——即从根到该结点所经分支的所有结点
子孙——即该结点下层子树中的任一结点
结点——即树的数据元素
结点的度——结点挂接的子树数
结点的层次——从根到该结点的层数(根结点算第一层)
终端结点——即度为0的结点,即叶子
分支结点——即度不为0的结点(也称为内部结点)
树的度——所有结点度中的最大值
树的深度(或高度)——指所有结点中最大的层数
【二叉树的定义】
二叉树(Binary Tree)是n(n≥0)个结点所构成的集合,它或为空树(n = 0);或为非空树,对于非空树T:
1. 有且仅有一个称之为根的结点;
1. 除根节点以外的其余结点分为两个互不相交的子集T1和T2,分别称为T的左子树和右子树,且T1和T2本身又都是二叉树。
普通树(多叉树)若不转化为二叉树,则运算很难实现。
为何要重点研究每结点最多只有两个“叉”的树?
- 二叉树的结构简单,规律性最强;
- 可以证明,所有的树都能转为唯一对应的二叉树,不失一般性。
【二叉树基本特点】
- 结点的度小于等于2
- 有序树(子树有序,不能颠倒)
【二叉树的基本操作】
-
CreateBiTree(&T, definition)
初始条件:definition给出二叉树T的定义
操作结果:按definition构造儿叉树T。
-
PreOrderTraverse(T)
初始条件:二叉树T存在
操作结果:先序遍历T,对每个结点访问一次
-
InOrderTraverse(T)
初始条件:二叉树T存在
操作结果:中序遍历T,对每个结点访问一次
-
PostOrderTraverse(T)
初始条件:二叉树T存在
操作结果:后序遍历T,对每个结点访问一次
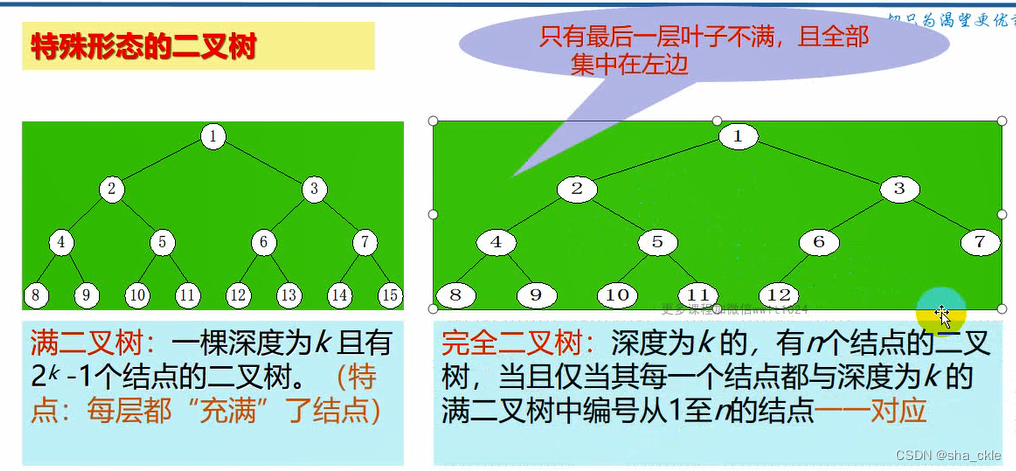
【特殊形态的二叉树】
【二叉树的顺序存储】
实现:按满二叉树的几点层次编号,依次存放二叉树中的数据元素。
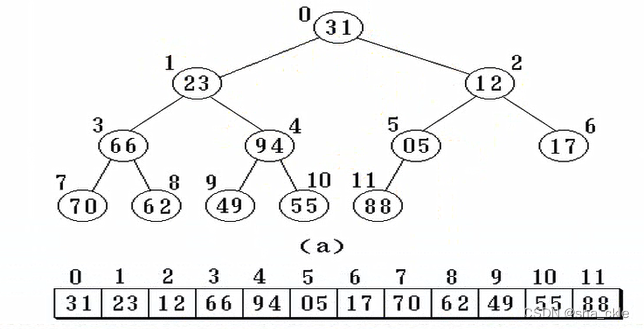
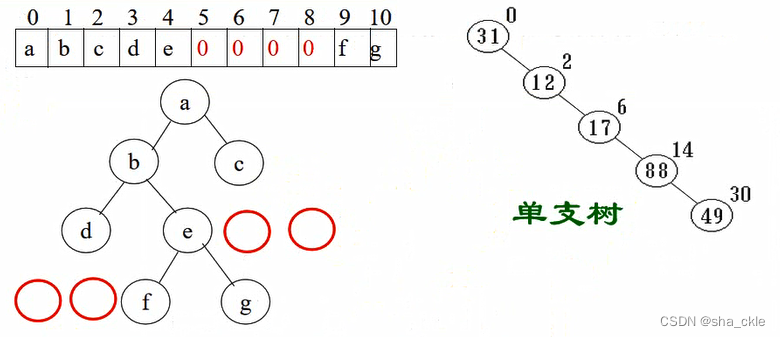
特点:结点间关系蕴含在其存储位置中,浪费空间,适于存满二叉树和完全二叉树。
二叉树的链式存储:
| lchild | data | rchild |
|---|
| lchild | data | parent | rchild |
|---|
二叉链表:
typedef struct BiNode{
TElemTypr data;
struct BiNode *lchild, *rchild;//左右孩子指针
}BiNode, *BiTree;
三叉链表
typedef struct TriTNode{
TelemType data;
struct TriTNode *lchild, *parent, *rchild;
}TriTNode, *TriTree;
二叉树(前中后)序算法
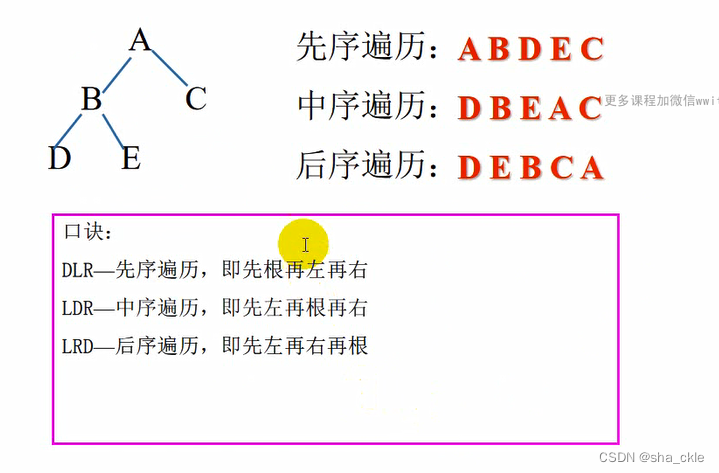
遍历的算法实现——先序遍历
若二叉树为空,则空操作
否则
- 访问根节点(D)
- 前序遍历左子树(L)
- 前序遍历右子树(R)
遍历的算法实现——中序遍历
若二叉树为空,则空操作
否则
- 中序遍历左子树(L)
- 访问根节点(D)
- 中序遍历右子树(R)
遍历的算法实现——后序遍历
若二叉树为空,则空操作
否则
- 后序遍历左子树(L)
- 后序遍历右子树(R)
- 访问根节点(D)
#include"stdafx.h"
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
//定义数据元素类型
#define ElemType char
//定义二叉树结点类型
typedef struct BiTNode{
ElemType data;//数据域
struct BiTNode *lchild, *rchild;//左右孩子指针
}BITNode, *PBiTree;
//输出结点数据元素
void DispElemFunc(BITNode *elem)
{
printf("%c\t",elem->data);
}
//创建二叉树
void CreateBTree(PBiTree *pt)
{
*pt = (PITNode*)malloc(sizeof(BITNode));//A
(*pt)->data = 'A';
(*pt)->lchild = (PITNode*)malloc(sizeof(BITNode));//B
(*pt)->lchild->data = 'B';
(*pt)->rchild = (PITNode*)malloc(sizeof(BITNode));//C
(*pt)->rchild->data = 'C';
(*pt)->lchild->lchild = (PITNode*)malloc(sizeof(BITNode));//D
(*pt)->lchild->lchild->data = 'D';
(*pt)->lchild->rchild = (PITNode*)malloc(sizeof(BITNode));//E
(*pt)->lchild->rchild->data = 'E';
(*pt)->rchild->lchild = (PITNode*)malloc(sizeof(BITNode));//F
(*pt)->rchild->lchild->data = 'F';
(*pt)->rchild->rchild = (PITNode*)malloc(sizeof(BITNode));//G
(*pt)->rchild->rchild->data = 'G';
(*pt)->lchild->lchild->lchild = NULL;
(*pt)->lchild->lchild->rchild = NULL;
(*pt)->lchild->rchild->lchild = NULL;
(*pt)->lchild->rchild->rchild = NULL;
(*pt)->rchild->lchild->lchild = NULL;
(*pt)->rchild->lchild->rchild = NULL;
(*pt)->rchild->rchild->lchild = NULL;
(*pt)->rchild->rchild->rchild = NULL;
}
//使用递归调用算法——先序遍历
void POrderTrav(PBiTree pt)
{
if(pt)
{
DispElemFunc(pt);
POrderTrav(pt->lchild);
POrderTrav(pt->rchild);
}
}
//使用递归调用算法——中序遍历
void MOrderTrav(PBiTree pt)
{
if(pt)
{
MOrderTrav(pt->lchild);
DispElemFunc(pt);
MOrderTrav(pt->rchild);
}
}
//使用递归调用算法——后序遍历
void AOrderTrav(PBiTree pt)
{
if(pt)
{
AOrderTrav(pt->lchild);
AOrderTrav(pt->rchild);
DispElemFunc(pt);
}
}
int _tmain(int argc, _TCHAR* argv[])
{
//调用构造二叉树函数
PBiTree pTree;
CreateBTree(&pTree);
printf("\n先序遍历:");
POrderTrav(pTree);
printf("\n");
printf("\n中序遍历:");
MOrderTrav(pTree);
printf("\n");
printf("\n后序遍历:");
AOrderTrav(pTree);
printf("\n");
}