在java.util.concurrent包中,我们经常会使用ReentrantLock,CyclicBarrier等工具类,但是我们往往对其内部的实现原理却并不知晓。
本篇文章主要对上述工具类的核心实现AQS进行剖析,分析原理可以让我们学习到大神的代码设计思维。
文章将从一下几个方面分析:
1.AQS是什么?
AbstractQueuedSynchronizer类就是我们通常说的AQS,抽象的队列同步器。
其实我们学过操作系统原理都知道,所谓的同步,指的是多线程场景下通过某种机制,保证某段代码执行是线程独享的,
我们把这段代码叫同步块,而把这种机制叫同步。
在JAVA中,传统的方式是使用synchronized关键字来实现同步,那么其底层是基于C++实现的ObjectMonitor。
今天我们讨论的AQS是JDK1.5之后,提供的一个能实现同步功能的抽象类。
通过该类的注释,我们可以了解到其内部采用了FIFO队列的数据结构来实现,互斥场景的资源申请和释放的实现如下所示:
Acquire: while (!tryAcquire(arg)) { enqueue thread if it is not already queued; possibly block current thread; } Release: if (tryRelease(arg)) unblock the first queued thread;
而tryAquire()和tryRelease()方法都是需要子类去实现的。
换句话说,如果要使用AQS,那么只需要继承,然后实现如下方法来自定义资源获取和释放的逻辑就行了。

FIFO队列的节点使用内部类Node来描述:
static final class Node { // 节点状态 volatile int waitStatus; // 上一个节点 volatile Node prev; // 下一节点 volatile Node next; // 需要排队的线程 volatile Thread thread; }
其他代码我先省略。
public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java.io.Serializable { // 双向链表头节点 private transient volatile Node head; // 双向链表为节点 private transient volatile Node tail; // 资源 private volatile int state; }
2.申请互斥资源的源码分析。
2.1 分析acquire()方法的逻辑
public final void acquire(int arg) { if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) selfInterrupt(); }
tryAcuire()方法可以理解成获取资源,由子类实现,我们不关注。
我把代码写成下面这样,可能好理解一些:
public final void acquire(int arg) { if(tryAcquire(arg)) { return; } Node n = addWaiter(Node.EXCLUSIVE); if(acquireQueued(n, arg)) selfInterrupt(); }
public final void acquire(int arg) { // 如果获取资源成功,直接返回 if(tryAcquire(arg)) { return true; } // 未获取到资源,将自己封装成一个node添加到队列尾部 Node n = addWaiter(Node.EXCLUSIVE); // 有点复杂,下面慢慢分析 if(acquireQueued(n, arg)) { // 自我中断 先不关注。 selfInterrupt(); } }
起码,我们应该知道一点,该方法一旦返回了,那么就意味着可以进入同步块代码执行了。
2.2 分析addWaiter()方法
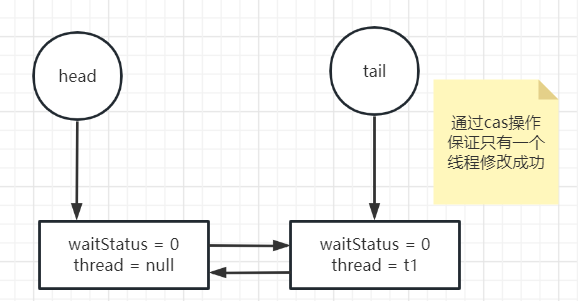
private Node addWaiter(Node mode) { // 以互斥模式创建一个node,waitStatus是0 Node node = new Node(Thread.currentThread(), mode); // 其实该段代码跟下面的enq方法差不多 Node pred = tail; // 如果该队列已经有为节点 if (pred != null) { // 当前node上一个node指向为尾节点 node.prev = pred; // cas修改尾节点 if (compareAndSetTail(pred, node)) { pred.next = node; return node; } } // 死循环保证添加成功 enq(node); return node; } private Node enq(final Node node) { for (;;) { Node t = tail; if (t == null) { // Must initialize // 如果当前队列没有节点,创建一个虚拟节点作为头和尾,该节点的thread == null, waitStatus是0 // 通过cas操作保证只有一个线程修改成功 if (compareAndSetHead(new Node())) tail = head; } else { node.prev = t; if (compareAndSetTail(t, node)) { t.next = node; return t; } } } }
其实上述方法就是保证了并发情况下node一定能正确加入到node中,而且如果是空链表,会增加一个虚拟的head节点。
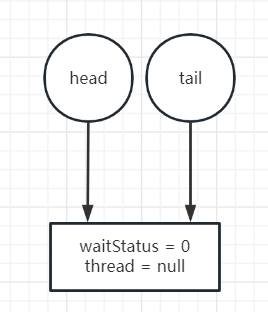
图解一下:
(创建head虚拟节点)
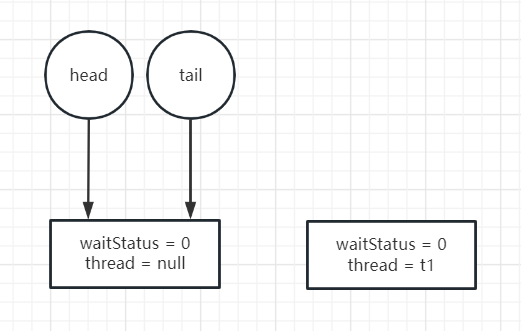
将新节点指向tail
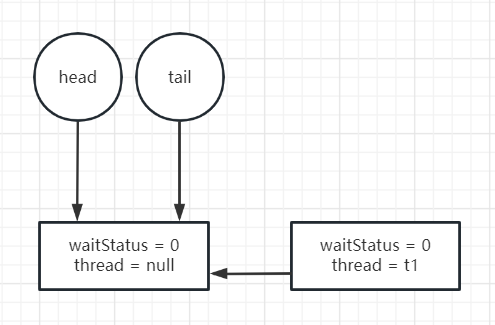
通过cas操作修改tail指向新节点
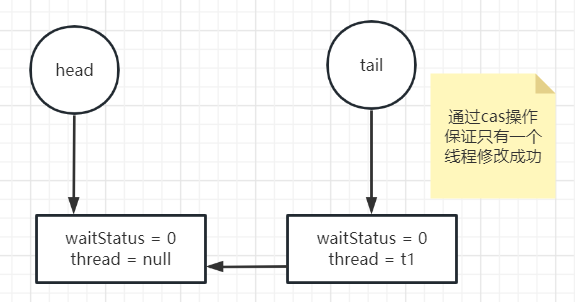
如果修改成功,将修改前的tail的next指向新节点
2.3 分析aquireQueued方法
// 看这个方法的时候我建议不要关注其中的临时变量 // 我们只要知道,这个方法里面有个死循环,不管怎样,只有return了,才能执行业务中定义的同步代码块。 final boolean acquireQueued(final Node node, int arg) { boolean failed = true; try { boolean interrupted = false; for (;;) { final Node p = node.predecessor(); if (p == head && tryAcquire(arg)) { setHead(node); p.next = null; // help GC failed = false; // 唯一的返回点 return interrupted; } if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) interrupted = true; } } finally { if (failed) cancelAcquire(node); } } // 我把代码改写成下面这样 可能会好理解一些 final boolean acquireQueued(final Node node, int arg) { boolean failed = true; try { boolean interrupted = false; for (;;) { final Node p = node.predecessor(); // 只有前继节点是head的时候具有获取资源的资格,如果获取成功则直接将当前node设置成head if (p == head && tryAcquire(arg)) { // 可能在排队后未阻塞前执行,也可能在阻塞被唤醒后执行 setHead(node); p.next = null; // help GC failed = false; // 唯一的返回点 return interrupted; } // 判断是否该阻塞自己 if (!shouldParkAfterFailedAcquire(p, node)){ continue; } // 进行阻塞,并且在被唤醒之后返回线程的中断状态 if(!parkAndCheckInterrupt()) { continue; } interrupted = true; } } finally { // 先别关注。 if (failed) cancelAcquire(node); } }
总之,一旦该方法返回了,就意味着线程获取资源成功了。
下面图解获取资源成功后,做的修改:
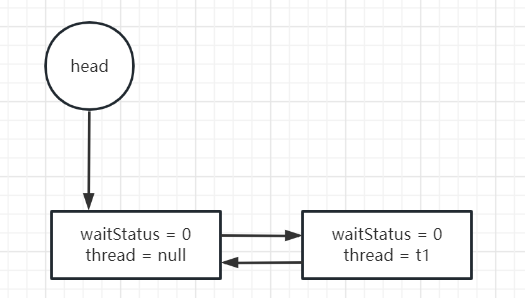
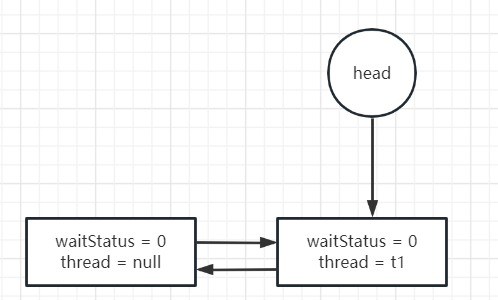
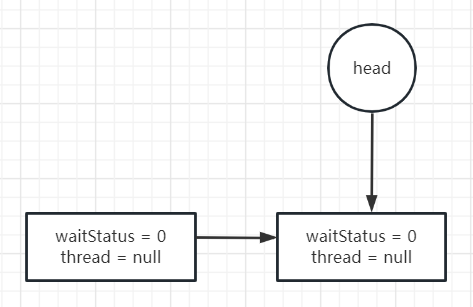
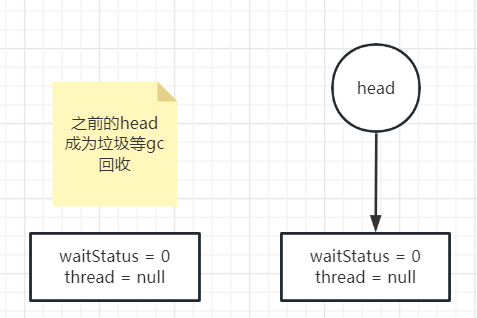
当然这里的waitStatus不一定是0。
2.4 分析shouldParkAfterFailedAcquire()方法
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) { int ws = pred.waitStatus; // 如果上一节点状态是-1,直接返回true if (ws == Node.SIGNAL) // 返回,并触发外层阻塞线程 return true; if (ws > 0) { // 如果上一个节点状态大于0,其实就是1表示被取消了 // 往前找waitStatus正常的节点 do { node.prev = pred = pred.prev; } while (pred.waitStatus > 0); pred.next = node; } else { // cas修改上一个节点为状态为-1 compareAndSetWaitStatus(pred, ws, Node.SIGNAL); } // 返回进入下一个循环 return false; }
其实逻辑很简单,就是修改自己的prev指向往前寻找的有效节点,并在阻塞前,将prev指向的有效节点waitStatus设置为-1。
问题来了?这个代码没有并发问题吗?
do { node.prev = pred = pred.prev; } while (pred.waitStatus > 0); pred.next = node;
答案是没有并发问题,因为每个节点都是往前寻找,理论上讲每个线程遍历的节点不一样。
我们来图解一下这个循环修改的过程:
假设线程A(waitStatus = 0),线程B(waitStatus = 1),线程C(waitStatus = 0 为当前线程)
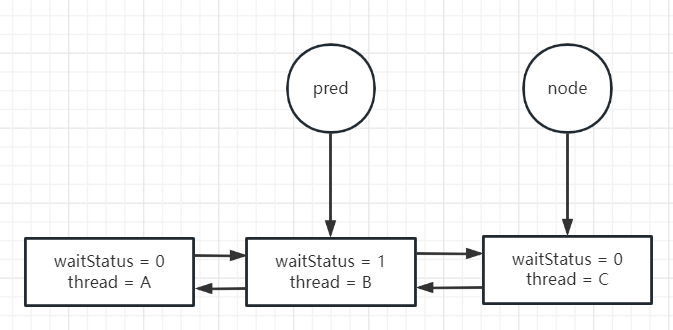
下图标识了循环往前探测并修改引用关系
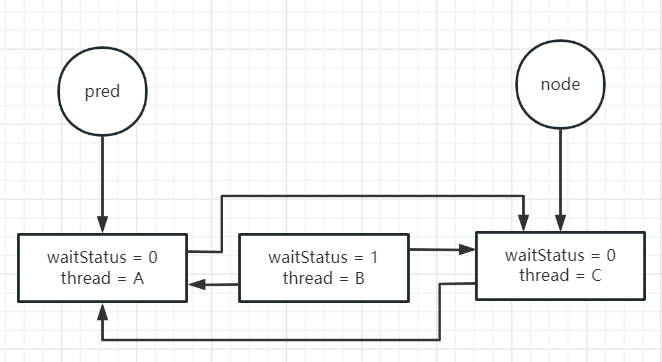
下图就是修改了pred节点的waitStatus = -1 (下一次循环到来的时候)
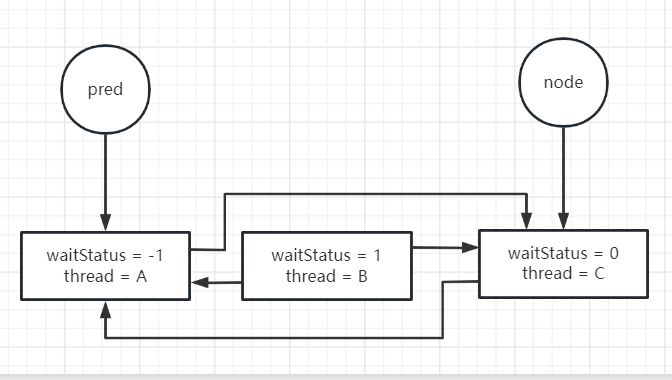
此时中间线程B的节点其实没有引用再指向他了。
如果成功修改线程A的waitStatus为-1之后,下一次循环到来,该方法就返回了true,线程就阻塞了。
其实看到这里,我们可以将虚拟的head节点就当做是正在使用资源的线程表示(个人观点哈)。
互斥资源申请的源码分析就结束了。
做一个小总结:
public final void acquire(int arg) { // 如果争抢资源成功直接返回直接业务的同步代码块 if (tryAcquire(arg)) { return; } // 循环+cas保证向队列中添加当前线程的node成功 Node n = addWaiter(Node.EXCLUSIVE); // 死循环,争抢资源,或者阻塞,或者唤醒之后继续争抢资源,直到抢资源成功后返回。 if(acquireQueued(n, arg)) { selfInterrupt(); } // 未被中断的抢到资源 }
3.释放互斥资源的源码分析。
我们直接分析release()方法:
public final boolean release(int arg) { if (tryRelease(arg)) { // 一旦释放资源,此处就需要考虑并发问题了 Node h = head; // head节点是虚拟节点,不可能是取消状态所以这里的判断可以理解为 // 头结点不为空而且头结点的waitStatus = -1执行unparkSuccessor方法 if (h != null && h.waitStatus != 0) unparkSuccessor(h); // h == null 或者 h.waitStatus = 0说明没有后继节点需要唤醒, // 如果此时正好head后面一个node正在试图修改head的状态改成-1是能改成功的 // 但是由于之前分析的acquireQueued方法是一个死循环,哪怕head被修改成-1, // 但是由于该循环会先抢锁所以也就不存在线程改了状态会park的问题。 // h == null说明并无线程参与竞争 return true; } return false; }
其实关键就是unparkSuccessor()方法
private void unparkSuccessor(Node node) { // 进入该方法说明资源已经被释放了。 int ws = node.waitStatus; // 如果ws小于0,修改为0 if (ws < 0) compareAndSetWaitStatus(node, ws, 0); // 传入node就是head // s指向head下一节点 Node s = node.next; // 如果没有后继节点说明有线程已经抢到资源 // 如果后继节点被取消了 if (s == null || s.waitStatus > 0) { // 假设没有节点需要唤醒 s = null; // 从后往前找,找到距离head最近的节点唤醒 for (Node t = tail; t != null && t != node; t = t.prev) if (t.waitStatus <= 0) s = t; } if (s != null) LockSupport.unpark(s.thread); }
其实执行该方法的时候是存在并发的情况的。
我理解这个地方从后往前找是为啥呢?能不能从前往后找?
这个问题,我也不知道。。。。