第一:豆瓣电影信息的爬取
1.分析源码
page页面:https://www.douban.com/doulist/3936288/

关键源码截图:
外部div:

<div class="bd doulist-subject">
<div class="doulist-video-items">
<span class="title">播放全片</span>
<a class="doulist-video-item" target="_blank" href="https://v.qq.com/x/cover/1o29ui77e85grdr.html?ptag=newdouban.movie"><span class="icon-circle"><img src="https://img1.doubanio.com/f/movie/f3c173002946c88386e659caef9842e97c19d273/pics/movie/video-qq.png" /></span> 腾讯视频</a>
<a class="doulist-video-item" target="_blank" href="https://m.bilibili.com/bangumi/play/ss28274?bsource=doubanh5"><span class="icon-circle"><img src="https://img1.doubanio.com/f/movie/f536fe0ea1cbb0914658ae803125d078351f9047/pics/movie/video-bilibili.png" /></span> 哔哩哔哩</a>
<a class="doulist-video-item" target="_blank" href="http://v.youku.com/v_show/id_XMjgwNDkwNzE2.html?tpa=dW5pb25faWQ9MzAwMDA4XzEwMDAwMl8wMl8wMQ&refer=esfhz_operation.xuka.xj_00003036_000000_FNZfau_19010900"><span class="icon-circle"><img src="https://img1.doubanio.com/f/movie/886b26a83d18bc60de4ee1daac38145f03c88792/pics/movie/video-youku.png" /></span> 优酷视频</a>
<a href="javascript:;" class="more-video-item"><img src="https://img1.doubanio.com/f/sns/e2ebb96e1a69c9d9ab686fdf1fda829f43aa1116/pics/sns/ic_circle_more@2x.png" /> 更多</a>
<div class="video-items-other">
<a target="_blank" href="https://www.douban.com/link2/?url=http%3A%2F%2Fwww.iqiyi.com%2Fv_19rra0h3wg.html%3Fvfm%3Dm_331_dbdy%26fv%3D4904d94982104144a1548dd9040df241&subtype=9&type=online-video"><span class="icon-circle"><img src="https://img1.doubanio.com/f/movie/7c9e516e02c6fe445b6559c0dd2a705e8b17d1c9/pics/movie/video-iqiyi.png" /></span> 爱奇艺视频</a>
</div>
</div>
内部div:
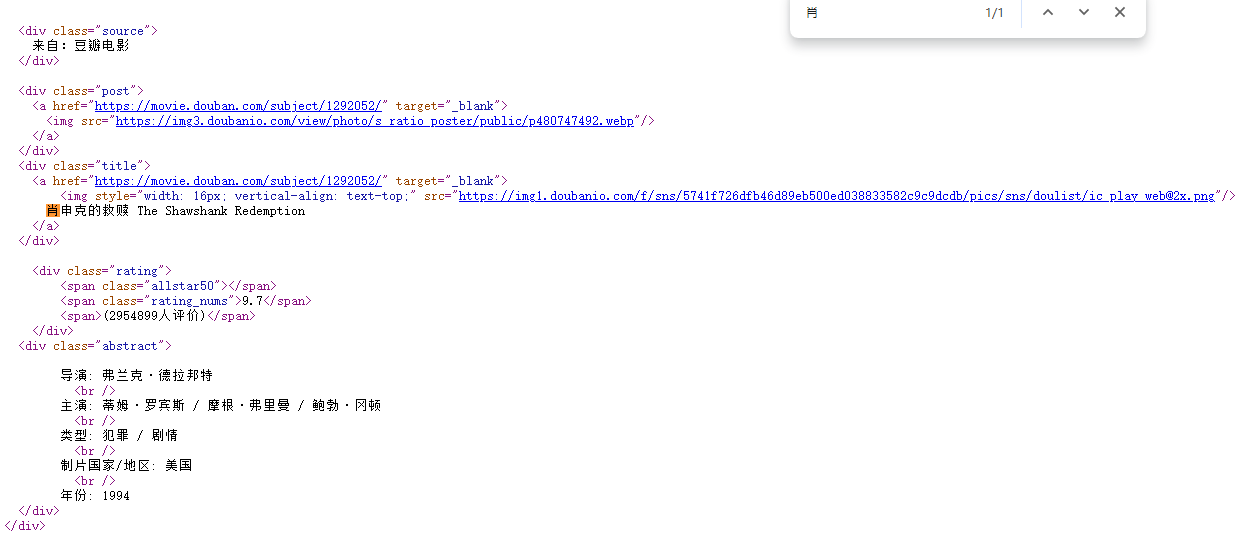
内部div:
<div class="source">
来自:豆瓣电影
</div>
<div class="post">
<a href="https://movie.douban.com/subject/1292052/" target="_blank">
<img src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.webp"/>
</a>
</div>
<div class="title">
<a href="https://movie.douban.com/subject/1292052/" target="_blank">
<img style="width: 16px; vertical-align: text-top;" src="https://img1.doubanio.com/f/sns/5741f726dfb46d89eb500ed038833582c9c9dcdb/pics/sns/doulist/ic_play_web@2x.png"/>
肖申克的救赎 The Shawshank Redemption
</a>
</div>
<div class="rating">
<span class="allstar50"></span>
<span class="rating_nums">9.7</span>
<span>(2954899人评价)</span>
</div>
<div class="abstract">
导演: 弗兰克·德拉邦特
<br />
主演: 蒂姆·罗宾斯 / 摩根·弗里曼 / 鲍勃·冈顿
<br />
类型: 犯罪 / 剧情
<br />
制片国家/地区: 美国
<br />
年份: 1994
</div>
</div>
2.通过命令创建spiders文件db.py
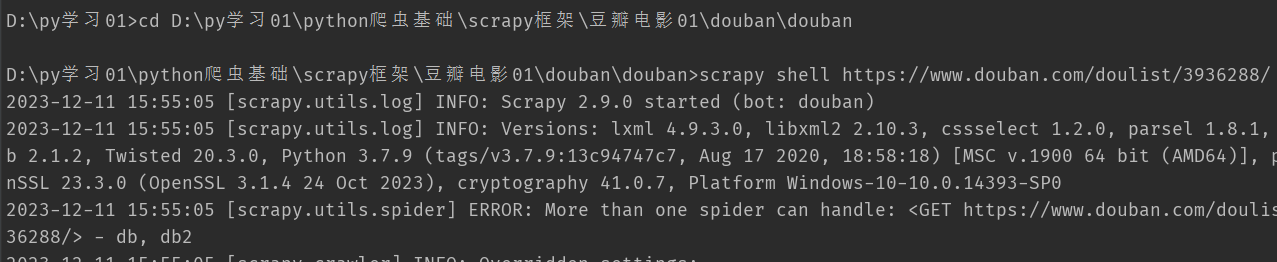
3.Scrapy shell 的运用(交互式平台)
用来调试Scrapy 项目代码的 命令行工具。 启动的时候预定义了Scrapy的一些对象 启动后如下图所示 作用: 调试 调试 调试
启动Scrapy shell的命令语法格式如下: scrapy shell [option] [url|file] url 就是你想要爬取的网址 注意:分析本地文件是一定要带上路径,scrapy shell默认当作url

获取page页面25条电影名字信息(以列表形式展示):response.xpath('//div[@class="title"]/a/text()')

获取Selector对象数值:response.xpath('//div[@class="title"]/a/text()').extract()

获取第一条电影名字信息(strip()为去除空格):response.xpath('//div[@class="title"]/a/text()').extract()[1].strip()
