-速度快:
-1 纯内存存储(核心)
-2 使用了IO多路复用的网络模型
-3 数据操作是单线程,避免了线程间切换,而且没有锁,也不会数据错乱
-支持持久化
-纯内存,可以存到硬盘上,防止数据丢失
-redis又被称之为 缓存数据库
操作之String操作:
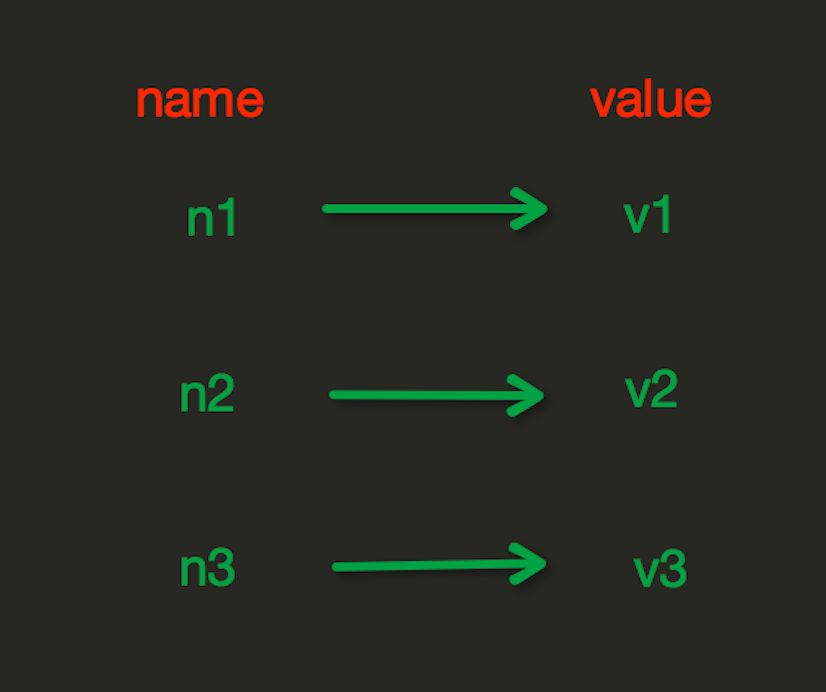
set(name, value, ex=None, px=None, nx=False, xx=False)
1 在Redis中设置值,默认,不存在则创建,存在则修改
2 参数:
3 ex,过期时间(秒)
4 px,过期时间(毫秒)
5 nx,如果设置为True,则只有name不存在时,当前set操作才执行,值存在,就修改不了,执行没效果
6 xx,如果设置为True,则只有name存在时,当前set操作才执行,值存在才能修改,值不存在,不会设置新值
setnx(name, value)
设置值,只有name不存在时,执行设置操作(添加),如果存在,不会修改
等同于coon.set('name','ydh',nx=True)
setex(name, time,value)
# 设置值
# 参数:
# time,过期时间(数字秒 或 timedelta对象)
psetex(name, time_ms, value)
# 设置值
# 参数:
# time_ms,过期时间(数字毫秒 或 timedelta对象
mset(*args, **kwargs)
coon.mset({'name':'lqz','age':'38'})
#一次设置多个值,优点是少了网络交互的时间
get(name)
#获取值,取出的是二进制,需要解码
#可以在redis.Redis()中设置参数:decode_responses=True,可以自动转为utf-8编码
mget(keys, *args)
批量获取
如:
mget('k1', 'k2')
或
mget(['k3', 'k4'])
getset(name, value)
设置新值并获取旧值
#res=coon.getset('name','篮球宝贝')
getrange(key, start, end)
# 获取子序列(根据字节获取,非字符)
# 参数:
# name,Redis 的 name
# start,起始位置(字节)
# end,结束位置(字节)
# 如:getrange('name',0,2)---------->获取key为name第0个索引到第2个索引的位置
setrange(name, offset, value)
# 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)
# 参数:
# offset,字符串的索引,字节(一个汉字三个字节)
# value,要设置的值
strlen(name)
#统计key值长度,按照字节数统计
incrby(name)
自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
#name必须为数字类型
参数:amount可以填自增数,不填默认为1,填的数必须为整数
incrby可以作为计数器来使用,不用担心并发安全问题,因为redis是单线程
incrbyfloat(self, name, amount=1.0)
自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
例:age=43
incrbyfloat('age')
输出为:44.0
decrby(self, name, amount=1)
# 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。
# 参数:
# name,Redis的name
# amount,自减数(整数)
append(key, value)
# 在redis name对应的值后面追加内容
# 参数:
key, redis的name
value, 要追加的字符串
操作之Hash操作:
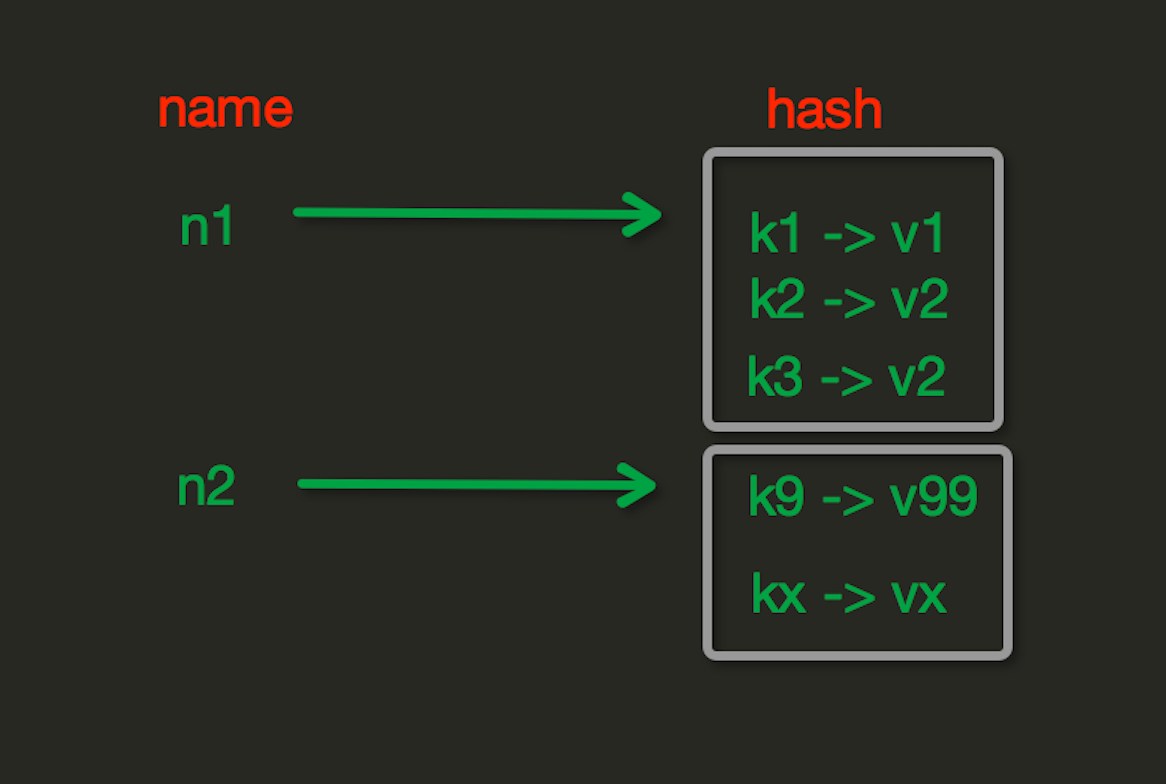
hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
# 参数:
# name,redis的name
# key,name对应的hash中的key
# value,name对应的hash中的value
hmset(name, mapping)
# 在name对应的hash中批量设置键值对
coon.hmset('userinfo',{'name':'李四','age':30})
新版本已经弃用了,现在更改为:coon.hset('userinfo',mapping={'name':'王五','age':31})
hget(name,key)
res=coon.hget('userinfo','name')
获取值,需要写两个key
hmget(name, keys, *args)
#在name中一次获取多个key值
res=coon.hmget('userinfo',['name','hobby'])
hgetall(name)
#获取name下所有的key和value
例:res=coon.hgetall('userinfo')
输出:{'name': '王五', 'hobby': '大保健', 'age': '31'}
hlen(name)
# 获取name对应的hash中键值对的个数
hkeys(name)
# 获取name对应的hash中所有的key的值
hvals(name)
# 获取name对应的hash中所有的value的值
hexists(name, key)
#判断name下的key是否存在,返回结果为布尔值
hdel(name,*keys)
#删除name下指定的键值对,可以删除多个
coon.hdel('userinfo','age')
hincrby(name, key, amount=1)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount,自增的key必须是数字类型
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(整数)
hincrbyfloat(name, key, amount=1.0)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(浮点数)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
hscan(name, cursor=0, match=None, count=None)
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆
# 参数:
# name,redis的name
# cursor,游标(基于游标分批取获取数据)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None)
# 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None)
# ...
# 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
hscan_iter(name, match=None, count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据
# 参数:
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# for item in r.hscan_iter('xx'):
# print item