一、python项目高并发异步部署
参考博客:https://zhuanlan.zhihu.com/p/358163330
django和flask都是同步框架,部署的时候,使用uwsgi部署,uwsgi是进程线程架构,并发量不高
但是我们可以通过uwsgi+gevent,部署成异步程序
然后我们简单分析一下他是怎么提高并发的,详细的去看老刘博客
我们设进程数最多为N,每个进程内的线程数最多为M,因此在使用uwsgi启动项目的时候,我们能处理的最高并发数就是N*M,当然这时候我们还可以通过添加服务器来获得更高的并发数
如果我们不添加服务器,就需要用uwsgi+gevent,部署成异步程序,通过这样的方式获得更高的并发量
而gevent就是我们学习的协程,协程就是单线程实现并发,用这样的方式提高并发量
gevent的好处就是无需等待I/O,当发生I/O调用是,gevent会主动切换到另一gevent进行运行,这样可以充分利用CPU资源
同时gevent通过monkey patch(猴子补丁)替换掉了标准库中阻塞的模块
二、uwsgi启动Python的Web项目中不要使用全局变量
参考博客:https://zhuanlan.zhihu.com/p/428228031
当我们运行项目的时候,因为进程是资源分配的最小变量,导致进程间数据不共享,这就会导致全局变量不是全局变量了(每个进程下都有一个该变量,互相独立)
三、信号
Flask中的信号(signal)是一种事件通知机制,用于在应用程序中的不同部分之间发送消息。信号通常用于在某些特定事件发生时执行特定的操作,例如在请求处理过程中执行某些额外的操作,或在应用程序启动或关闭时执行特定的操作。(Flask框架中的信号基于blinker,其主要就是让开发者可是在flask请求过程中定制一些用户行为)
ps1:我们会发现他的作用跟请求扩展很像
ps2:flask 和django都有信号
信号:signial 翻译过来的,在并发编程中学过 信号量:Semaphore,两者不是一个东西
应用场景举例:
我需要在用户表新增一条记录,就记录一下日志
- 方案一:在每个增加后,都写一行代码 ---》后期要删除,比较麻烦
- 方案二:使用信号,写一个函数,绑定内置信号,只要程序执行到这,就会执行这个函数
方案一确实可以使用,但是耦合性比较强(或者叫侵入性比较强,即没有去修改该功能的代码),当我们需要修改功能的时候,我们需要在每个添加日志的代码处进行修改,而方案二就像我们抽取代码封装成函数一样,只需要修改一处地方
拓展:
代码的健壮性(跟鲁棒性是一样的意思):鲁棒性亦称健壮性、稳健性、强健性,是系统的健壮性,它是在异常和危险情况下系统生存的关键,是指系统在一定(结构、大小)的参数摄动下,维持某些性能的特性。
3.1 flask信号
安装blinker模块
pip3.8 install blinker
常见的内置信号
request_started = _signals.signal('request-started') # 请求到来前执行
request_finished = _signals.signal('request-finished') # 请求结束后执行
before_render_template = _signals.signal('before-render-template') # 模板渲染前执行(可以用于实现统计模版被访问次数)
template_rendered = _signals.signal('template-rendered') # 模板渲染后执行
got_request_exception = _signals.signal('got-request-exception') # 请求执行出现异常时执行
request_tearing_down = _signals.signal('request-tearing-down') # 请求执行完毕后自动执行(无论成功与否)
appcontext_tearing_down = _signals.signal('appcontext-tearing-down')# 应用上下文执行完毕后自动执行(无论成功与否)
appcontext_pushed = _signals.signal('appcontext-pushed') # 应用上下文push时执行
appcontext_popped = _signals.signal('appcontext-popped') # 应用上下文pop时执行
message_flashed = _signals.signal('message-flashed') # 调用flask在其中添加数据时,自动触发
使用内置信号的步骤
1、写一个函数
2、绑定内置信号
3、等待被触发
演示代码
from flask import Flask, render_template, signals,session
app = Flask(__name__)
app.secret_key='asdfasdfdas'
#### 内置信号使用
# 1 写一个函数
'虽然我们的这个函数不需要参数,但是我们也得写上可变长参数用于接收信号传进来的数据'
def test(*args,**kwargs):
print(args)
print(kwargs)
print('我执行了')
# 2 绑定信号
# 内置信号很多,随意绑定一个:模板渲染前
signals.before_render_template.connect(test)
# 3 等待信号被触发
@app.route('/index')
def index():
return render_template('index.html', name='lqz')
if __name__ == '__main__':
app.run()
触发结果如下:

我们可以看到传进来的参数很多,有template、context、request、session等信息
使用自定义信号的步骤
1、定义出信号(需要我们自己做了)
这里我们也可以在他的源码中找到内置信号的定义
template_rendered = _signals.signal("template-rendered")
before_render_template = _signals.signal("before-render-template")
request_started = _signals.signal("request-started")
request_finished = _signals.signal("request-finished")
request_tearing_down = _signals.signal("request-tearing-down")
got_request_exception = _signals.signal("got-request-exception")
appcontext_tearing_down = _signals.signal("appcontext-tearing-down")
appcontext_pushed = _signals.signal("appcontext-pushed")
appcontext_popped = _signals.signal("appcontext-popped")
message_flashed = _signals.signal("message-flashed")
2、写一个函数
3、绑定自定义的信号
4、触发信号的执行(也需要我们自己做了)
演示代码
from flask import Flask, render_template, signals,session
from flask.signals import _signals
app = Flask(__name__)
app.secret_key='asdfasdfdas'
###自定义信号
# 1 定义出信号
session_set = _signals.signal('session_set')
# 2 写一个函数
def test1(*args, **kwargs):
print(args)
print(kwargs)
print('session设置值了')
# 3 绑定自定义的信号
session_set.connect(test1)
# 4 触发信号的执行(咱们做)
# session_set.send('lqz') # 触发信号执行
@app.route('/')
def hello_world():
session['lqz']='lqz'
session_set.send('lqz') # 触发信号执行
return 'Hello World!'
@app.route('/index')
def index():
return render_template('index.html', name='lqz')
if __name__ == '__main__':
app.run()
这里我们定义了一个信号,通过信号名称.send()的方式来触发信号的执行
如果我们像上面一样传了参数,就可以在函数的args参数中被接受到
在源码中查找内置信号在哪触发的
在Flask的full_dispatch_request方法中,我们可以找到send的执行,部分源码如下:
try:
request_started.send(self)
'这里就是触发信号'
rv = self.preprocess_request()
'这里就是执行请求扩展中的方法'
if rv is None:
rv = self.dispatch_request()
except Exception as e:
rv = self.handle_user_exception(e)
return self.finalize_request(rv)
preprocess_request源码如下:
def preprocess_request(self) -> t.Optional[ft.ResponseReturnValue]:
names = (None, *reversed(request.blueprints))
for name in names:
if name in self.url_value_preprocessors:
for url_func in self.url_value_preprocessors[name]:
url_func(request.endpoint, request.view_args)
for name in names:
if name in self.before_request_funcs:
for before_func in self.before_request_funcs[name]:
rv = self.ensure_sync(before_func)()
if rv is not None:
return rv
return None
在这里我们看到了before_request_funcs,从if里面的判断内容,我们可以猜到,他就是判断用来请求扩展的视图名称是否在里面
接着我们看请求扩展装饰器的源码,我们发现他就是把方法名称添加到before_request_funcs中去
@setupmethod
def before_request(self, f: T_before_request) -> T_before_request:
self.before_request_funcs.setdefault(None, []).append(f)
return f
总结前后的源码,我们得出结论,用了请求扩展装饰器的视图方法的名称,会被添加到before_request_funcs中去,然后再触发的时候,去before_request_funcs查找名称是否在里面,在的话就执行对应的代码
#观察者模式,又叫发布-订阅(Publish/Subscribe) 23 种设计模式之一
# django中使用信号
3.2 django信号
参考博客:https://www.cnblogs.com/liuqingzheng/articles/9803403.html
在他的文章中提到了Django提供一种信号机制。其实就是观察者模式,又叫发布-订阅(Publish/Subscribe) 。
观察者模式,又叫发布-订阅(Publish/Subscribe) 23 种设计模式之一
简单来说,他就像抖音上的一个账号,如果我关注(订阅)了这个账号,当他更新的时候,我就会收到他的新视频的消息推送。如果我没有关注(订阅)他,我就不会收到他的消息推送。
当发生一些动作的时候,发出信号,然后监听了这个信号的函数就会执行。
通俗来讲,就是一些动作发生的时候,信号允许特定的发送者去提醒一些接受者。用于在框架执行操作时解耦。
ps:这个信号可以处理双写一致性问题
django的内置信号
Model signals
pre_init # django的modal执行其构造方法前,自动触发
post_init # django的modal执行其构造方法后,自动触发
pre_save # django的modal对象保存前,自动触发
post_save # django的modal对象保存后,自动触发
pre_delete # django的modal对象删除前,自动触发
post_delete # django的modal对象删除后,自动触发
m2m_changed # django的modal中使用m2m字段操作第三张表(add,remove,clear)前后,自动触发
class_prepared # 程序启动时,检测已注册的app中modal类,对于每一个类,自动触发
Management signals
pre_migrate # 执行migrate命令前,自动触发
post_migrate # 执行migrate命令后,自动触发
Request/response signals
request_started # 请求到来前,自动触发
request_finished # 请求结束后,自动触发
got_request_exception # 请求异常后,自动触发
Test signals
setting_changed # 使用test测试修改配置文件时,自动触发
template_rendered # 使用test测试渲染模板时,自动触发
Database Wrappers
connection_created # 创建数据库连接时,自动触发
django中使用内置信号
# django中使用内置信号
1 写一个函数
def callBack(*args, **kwargs):
print(args)
print(kwargs)
2 绑定信号
#方式一
post_save.connect(callBack)
# 方式二
from django.db.models.signals import pre_save
from django.dispatch import receiver
@receiver(pre_save)
def my_callback(sender, **kwargs):
print("对象创建成功")
print(sender)
print(kwargs)
3 等待触发
四、微服务的概念
参考博客:https://www.cnblogs.com/liuqingzheng/p/16271897.html
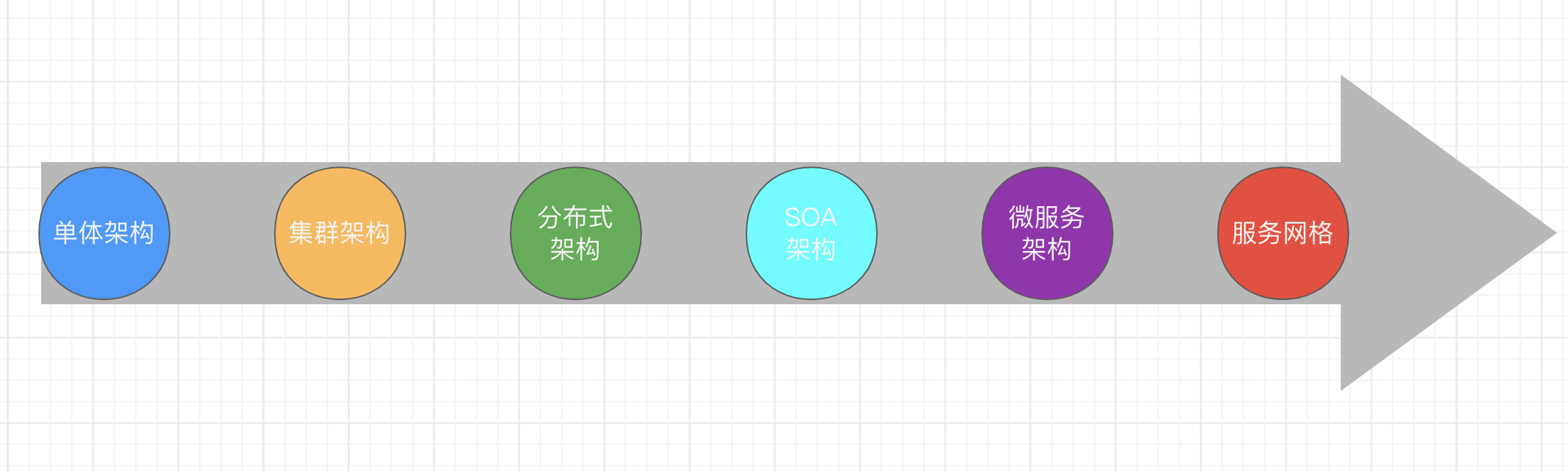
我们平时用django写的项目就是单体架构,所有的功能都放在一个项目中,当一个项目上了新功能的时候,肯定要测试,这时候我们所有的功能都是要测试的,这就导致工作量很大
到了很大的项目中,就需要拆分功能,这就是集群架构
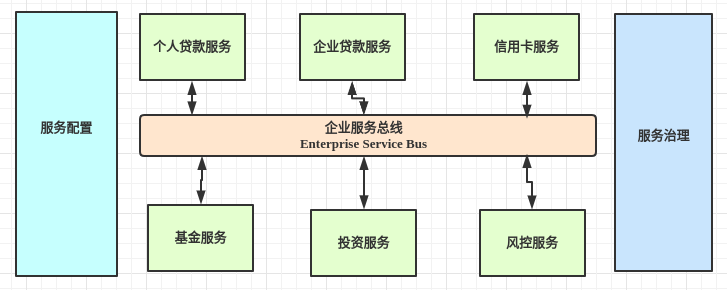
接着就是分布式架构,分布式架构最早期用的就是soa架构,京东就是用的这种架构,把一个个app分出来,根据功能不同,分别上线,这样相互之间就不会影响,但是数据互相独立也会出现很多问题
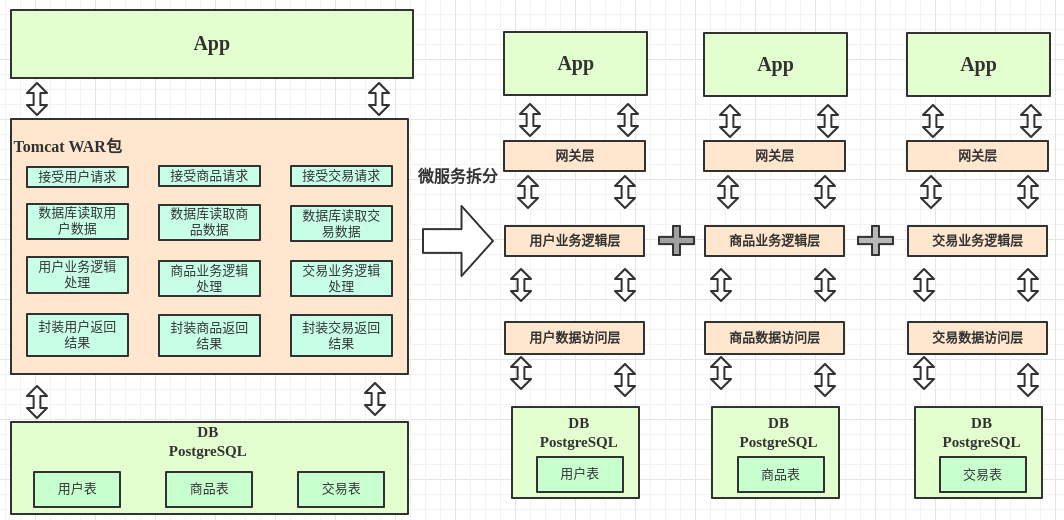
接着就是微服务架构,他相当于在soa架构的基础上接着拆分,然后他拆分出来的一个个服务之间可以互相联系组织
五、flask-script
在django中,我们运行项目执行命令
python manage.py runserver
...
而在flask项目中,目前我们是直接右键运行的
我们如果想像django项目中一样运行项目,需要借助flask-script
安装flask-script模块
pip3 install flask-script
这里我们需要注意,不同版本的flask和flask-script不一定兼容,下方是一组兼容的版本
Flask==2.2.2
Flask_Script==2.0.3
使用步骤:
manage.py
from flask import Flask
'步骤一导入模块中的Manager'
from flask_script import Manager
app = Flask(__name__)
'然后把app对象传入Manager'
manager=Manager(app)
app.secret_key='asdfasdfdas'
@app.route('/')
def hello_world():
return 'Hello World!'
if __name__ == '__main__':
# app.run()
'最后修改项目的启动方式'
manager.run()
修改完代码后,我们会发现右键运行代码,已经不能让项目跑起来了,我们需要在执行文件所在目录,运行命令启动项目
python manage.py runserver
这里的manage.py,可以换成别的文件名称,同时启动时也是可以执行ip和端口号的,像python一样添加即可
自定制命令
这个我们可以去搜相关的博客,也可以去学长的项目查看他是怎么用的
from flask import Flask
'步骤一导入模块中的Manager'
from flask_script import Manager
app = Flask(__name__)
'然后把app对象传入Manager'
manager=Manager(app)
app.secret_key='asdfasdfdas'
#1 简单自定制命令
@manager.command
def custom(arg):
# 命令的代码,比如:初始化数据库, 有个excel表格,使用命令导入到mysql中
print(arg)
#2 复杂一些的自定制命令
@manager.option('-n', '--name', dest='name')
@manager.option('-u', '--url', dest='url')
def cmd(name, url):
# python run.py cmd -n lqz -u xxx
# python run.py cmd --name lqz --url uuu
print(name, url)
@app.route('/')
def hello_world():
return 'Hello World!'
if __name__ == '__main__':
# app.run()
'最后修改项目的启动方式'
manager.run()
简单自定制命令:
python run.py custom zzh
这里的zzh就是传进去的参数
复杂一些的自定制命令:
python run.py cmd -n lqz -u xxx
python run.py cmd --name lqz --url uuu
六、sqlalchemy 快速使用
参考博客:https://www.cnblogs.com/liuqingzheng/p/16005909.html
flask 中没有orm框架,对象关系映射,方便我们快速操作数据库
flask,fastapi中用sqlalchemy居多
SQLAlchemy是一个基于Python实现的ORM框架。该框架建立在 DB API之上,使用关系对象映射进行数据库操作,简言之便是:将类和对象转换成SQL,然后使用数据API执行SQL并获取执行结果
安装sqlalchemy模块
pip3.8 install sqlalchemy
SQLAlchemy本身无法操作数据库,其必须以来pymsql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>
pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname>
cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
更多:http://docs.sqlalchemy.org/en/latest/dialects/index.html
七、sqlalchemy快速使用
4.1 原生操作的快速使用
# 先不是orm,而是原生sql
# 第一步:导入
from sqlalchemy import create_engine
# 第二步:生成引擎对象
engine = create_engine(
"mysql+pymysql://root@127.0.0.1:3306/cnblogs",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置),-1就是不回收
)
# 第三步:使用引擎获取连接,操作数据库
conn = engine.raw_connection()
cursor=conn.cursor()
cursor.execute('select * from aritcle')
print(cursor.fetchall())
八、创建操作数据表
# 第一步:导入
from sqlalchemy import create_engine
import datetime
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index
# 第二步:执行declarative_base,得到一个类
Base = declarative_base()
# 第三步:继承生成的Base类
class User(Base):
# 第四步:写字段
id = Column(Integer, primary_key=True) # 生成一列,类型是Integer,主键
name = Column(String(32), index=True, nullable=False) # name列varchar32,索引,不可为空
email = Column(String(32), unique=True)
# datetime.datetime.now不能加括号,加了括号,以后永远是当前时间
ctime = Column(DateTime, default=datetime.datetime.now)
# extra = Column(Text, nullable=True)
# 第五步:写表名 如果不写以类名为表名
__tablename__ = 'users' # 数据库表名称
# 第六步:建立联合索引,联合唯一
__table_args__ = (
UniqueConstraint('id', 'name', name='uix_id_name'), # 联合唯一
Index('ix_id_name', 'name', 'email'), # 索引
)
class Book(Base):
__tablename__ = 'books'
id = Column(Integer, primary_key=True)
name = Column(String(32))
# 第七步:把表同步到数据库中
# 不会创建库,只会创建表
engine = create_engine(
"mysql+pymysql://root@127.0.0.1:3306/aaa",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
# 把表同步到数据库 (把被Base管理的所有表,都创建到数据库)
Base.metadata.create_all(engine)
# 把所有表删除
# Base.metadata.drop_all(engine)
九、作业
1、什么是猴子补丁,有什么用途
什么是猴子补丁?
猴子补丁(Monkey Patching)是一种在运行时动态修改代码的技术,通常用于临时修复或修改代码中的问题。猴子补丁可以在不修改原始代码的情况下,通过在运行时动态修改代码来实现临时修复或修改。
猴子补丁的优点是可以快速修复或修改问题,而无需等待官方版本的更新或重新部署应用程序。但是,猴子补丁的使用也存在一些风险和缺点,例如可能会导致代码的不稳定性、可维护性和可读性降低,以及可能会与其他模块或库产生冲突等问题。
猴子补丁的用途
猴子补丁的用途包括:
- 临时修复代码中的问题:在软件开发过程中,经常会出现一些bug或问题。使用猴子补丁可以在不修改原始代码的情况下,临时修复这些问题,从而避免影响软件的正常使用。
- 动态修改代码的行为:使用猴子补丁可以在运行时动态修改代码的行为,例如增加日志输出、修改函数的返回值等。这种方式可以在不修改原始代码的情况下,快速地实现一些调试和测试目的。
- 扩展和定制第三方库:使用猴子补丁可以在不修改第三方库的情况下,扩展和定制它的行为。例如,可以使用猴子补丁来修改第三方库的默认设置、增加一些新的功能等。
2、什么是反射,python中如何使用反射
反射功能介绍
什么是反射:
反射就是通过字符串的形式去对象(模块)中操作(查找/获取/删除/添加)成员
反射的本质(核心):基于字符串的事件驱动,利用字符串的形式去操作对象/模块中成员(方法、属性)
在Python中,反射指的是通过字符串来操作对象的属性,涉及到四个内置函数的使用:
1.hasattr() 重点
- 判断对象是否含有某个字符串对应的属性名或方法名
2.getattr() 重点
- 根据字符串获取对象对应的属性的值或方法名(函数体代码)的结果
3.setattr()
- 根据字符串给对象设置或者修改数据
4.delattr()
- 根据字符串删除对象里面的名字
class Teacher:
def __init__(self,full_name):
self.full_name =full_name
t=Teacher('jason Lin')
# hasattr(object,'name')
hasattr(t,'full_name') # 按字符串'full_name'判断有无属性t.full_name
# getattr(object, 'name', default=None)
getattr(t,'full_name',None) # 等同于t.full_name,不存在该属性则返回默认值None
# setattr(x, 'y', v)
setattr(t,'age',18) # 等同于t.age=18
# delattr(x, 'y')
delattr(t,'age') # 等同于del t.age
3、http和https的区别
参考博客:https://juejin.cn/post/6844903471565504526
HTTP和HTTPS的基本概念
HTTP:是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少。
HTTPS:是以安全为目标的HTTP通道,简单讲是HTTP的安全版,即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。
HTTPS协议的主要作用可以分为两种:一种是建立一个信息安全通道,来保证数据传输的安全;另一种就是确认网站的真实性。
HTTPS和HTTP的主要区别
- 安全性:HTTPS比HTTP更安全。HTTP是明文传输的,网络上的任何人都可以截取和查看HTTP传输的内容,包括账户密码等敏感信息。而HTTPS使用SSL/TLS加密协议,可以保证数据传输的安全性。
- 数据传输方式:HTTP使用TCP端口80,而HTTPS使用TCP端口443。HTTP传输的数据是明文的,而HTTPS传输的数据是加密的。
- 认证方式:HTTP没有认证机制,任何人都可以发送HTTP请求,而HTTPS使用数字证书认证机制,可以保证通信双方的身份和数据的完整性。
- 性能:由于HTTPS使用加密协议,会增加数据传输的开销,因此相比HTTP,HTTPS的性能会有所下降。
总的来说,HTTPS比HTTP更安全,适用于传输敏感信息的场景,例如网上银行、电子商务等。而HTTP适用于一些不需要传输敏感信息的场景,例如普通的网页浏览、新闻阅读等。