首先说一下文件用到的库:
-
time :提供了与时间相关的功能,如延时等。
-
random :提供了生成随机数的功能,如生成随机整数、随机选择等。
-
requests :用于发送 HTTP 请求,可以用来获取网页内容。
-
pandas :是一个数据处理和分析库,提供了高效的数据结构和数据分析工具,可以方便地对数据进行处理和分析。
-
BeautifulSoup :是一个用于解析 HTML 和 XML 文件的库,可以方便地提取其中的数据。
-
faker :用于生成虚假数据,例如生成虚假的姓名、地址、电子邮件等。 这些库在爬虫开发中非常常用。
time 和 random 可以用来控制爬虫的访问速度,避免对目标网站造成过大的负载。 requests 可以用来发送 HTTP 请求,获取网页内容。 pandas 可以用来处理和分析爬取到的数据。 BeautifulSoup 可以用来解析网页内容,提取其中的数据。 faker 可以用来生成虚假的数据,用于测试或模拟爬虫程序。
分析 “贝壳网站” 页面
第 1 页
https://cq.zu.ke.com/zufang/pg1/#contentList
第 2 页
https://cq.zu.ke.com/zufang/pg2/#contentList
第 3 页
https://cq.zu.ke.com/zufang/pg3/#contentList
… …
… …
第 n 页
https://cq.zu.ke.com/zufang/pgn/#contentList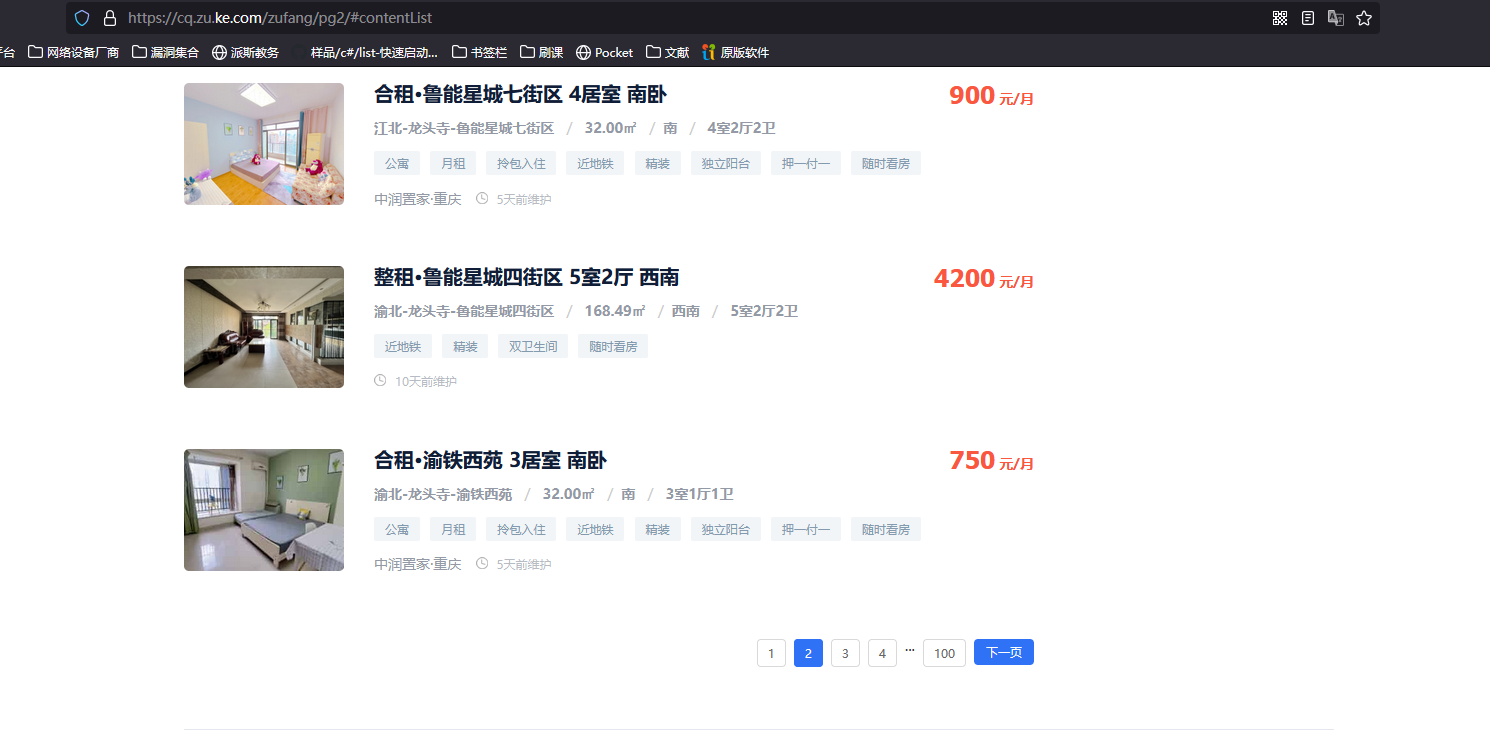
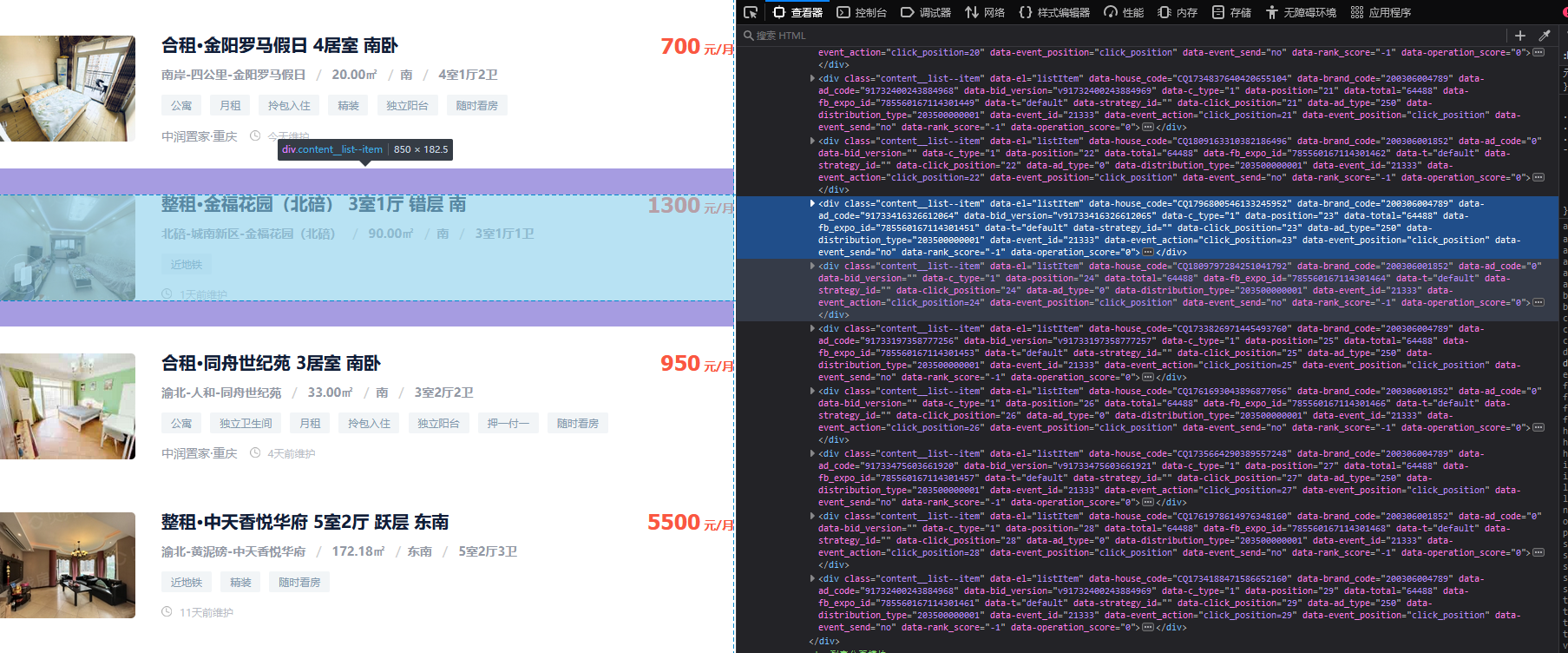
分析前端元素:
可发现目标在每个class为content__list--item的div中
首先获取此div:
zufangxinxis=soup.findAll('div', class_='content__list--item')这串代码就是找到页面上所有class为content_list--item的div
继续分析在此div下面还有个class为content__list--item--main的div,下一步就是找到此div
for xinxi in zufangxinxis:
# CSS 选择器
weizhi = soup.select("p[class='content__list--item--title'] a[class='twoline']")
jiage = soup.select("span[class='content__list--item-price']")

还没写完,稍等……
完整代码:
import time
import random
import requests
import pandas as pd
from bs4 import BeautifulSoup
from faker import Factory
def get_user_agent(num):
"""
生成不同的 user-agent
:param num: 生成个数
:return: list
"""
factory = Factory.create()
user_agent = []
for i in range(num):
user_agent.append({'User-Agent': factory.user_agent()})
return user_agent
def get_proxy(pages, ua_num):
#爬取数据,清洗整合
headers = get_user_agent(ua_num) # 请求头
proxy_list = [] # 最后需入库保存的房源数据
try:
for num in range(0, pages):
print('Start:第 %d 页请求' % (num + 1))
# 请求路径
url = 'https://cq.zu.ke.com/zufang/pg' + str(num + 1) + '/' + '#contentList'
# url = 'https://cq.zu.ke.com/zufang/pg1' +'/' + '#contentList'
# 随机延时(randint生成的随机数n: a <= n <= b ;random产生 0 到 1 之间的随机浮点数)
time.sleep(random.randint(1, 2) + random.random())
header_i = random.randint(0, len(headers) - 1) # 随机获取1个请求头
# BeautifulSoup 解析
html = requests.get(url, headers=headers[header_i])
soup = BeautifulSoup(html.text, 'lxml')
# 获取所有 div 标签中 class 为 content__list--item--title 的元素
zufangxinxis = soup.findAll('div', class_='content__list--item')
for xinxi in zufangxinxis:
# CSS 选择器
weizhi = soup.select("p[class='content__list--item--title'] a[class='twoline']")
jiage = soup.select("span[class='content__list--item-price']")
for i, p in zip(weizhi, jiage):
i_jiagou = str(i.get_text())
i_jiege = str(p.get_text())
flag = (i_jiagou,headers[header_i])
if flag:
p_xinxi=str(i_jiagou)
p_jiege=str(i_jiege)
proxy_list.append([p_xinxi,p_jiege])
print('End:第 %d 页结束!==========================' % (num + 1))
except Exception as e:
print('程序 get_proxy 发生错误,Error:', e)
finally:
# 调用保存的方法
write_proxy(proxy_list)
return proxy_list
def write_proxy(proxy_list):
"""
将清洗好的列表数据,保存到xlsx文件
:param proxy_list: 房源信息数据列表
:return: bool
"""
date_now ='租房信息表' # 名字
flag = True # 保存成功标志
print('--- 开始保存 ---')
try:
df = pd.DataFrame(proxy_list,
columns=['房源信息','价格'])
df.to_excel(date_now + '_proxy.xlsx', index=False)
print('--- 保存成功!---')
except Exception as e:
print('--- 保存失败!---:', e)
flag = False
return flag
def main():
"""
主方法
"""
pa = input('请输入你想爬取的页数:')# 定义爬取页数
pages =int(pa)
ua = input('请输入你想生成user-agent个数:')# 定义需生成user-agent个数
ua_num = int(ua)
proxy_list = get_proxy(pages, ua_num)
print(proxy_list)
if __name__ == '__main__':
# 1.主方法
main()