| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 个人项目 |
| 这个作业的目标 | 设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率 |
1. PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 1370 | 1770 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 300 | 460 |
| · Design Spec | · 生成设计文档 | 100 | 80 |
| · Design Review | · 设计复审 | 40 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 50 | 40 |
| · Design | · 具体设计 | 200 | 280 |
| · Coding | · 具体编码 | 400 | 490 |
| · Code Review | · 代码复审 | 60 | 70 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 100 | 180 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 40 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 50 | 60 |
| · 合计 | 1370 | 1770 |
2. 计算模块接口与实现过程
(1)程序实现类
- 主类:
Application ,包含main方法,可以接收指定参数,传递给Document类进行文件的输入输出,并调用其他工具类中的方法实现程序的运行。 - 工具类:
CuttingWordsUtil,中文工具类,具有中文分词的方法。
DocumentUtil,文件工具类,控制文件的输入输出。
SimpleCommonWords,简单共有词计算类,通过简单共有词算法对两个文档的相似度进行计算。 - 测试类:
TestCoverage,测试各模块的功能是否正常。 - 项目结构:
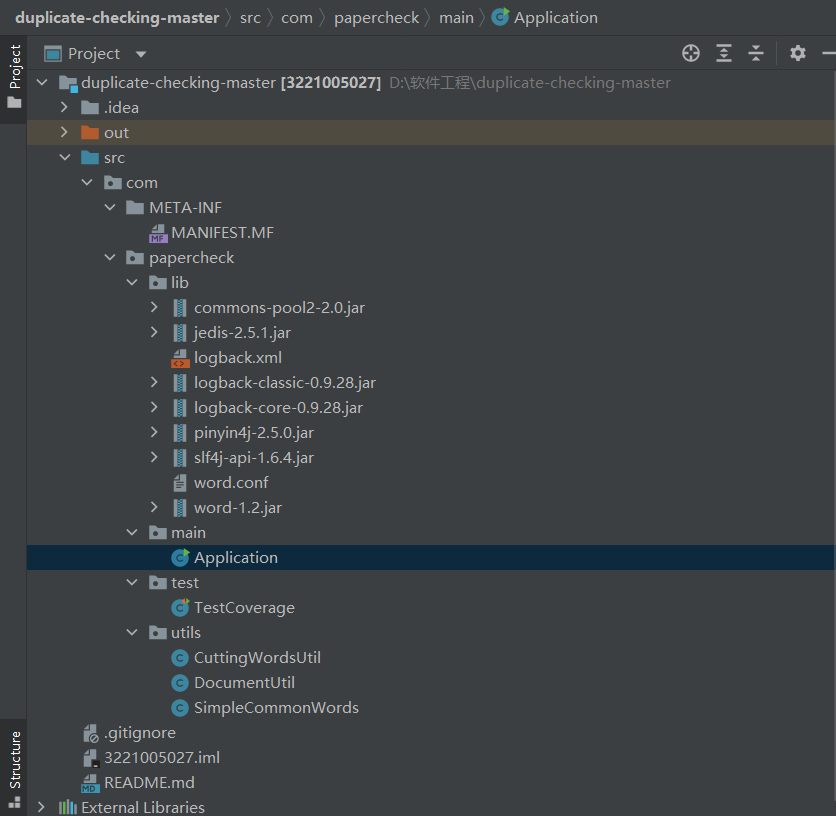
- 项目流程:
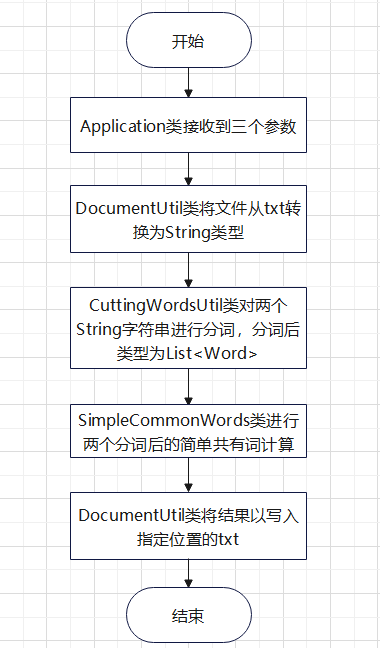
(2) 关键函数的分析与实现
实现查重的关键点在于分词函数和相似度算法
选择word分词器和简单共有词算法来完成本次设计。
简单共有词算法简单流程如下:
String1: 我读过那么多故事。
String2: 我听过那么多故事。 - 分词
String1: [我, 读过, 那么多, 故事]
String2: [我, 听过, 那么多, 故事] - 分别计算总字符数
words1 = 4
words2 = 4 - 计算共有词的总字符
commonwords = 3 - 计算相似度
选取长度最长的字符数为分母,共有词的总字符为分子
result = 3 / 4 = 0.75
这个算法的思路比较直观,易于理解其基本原理,直观的讲就是首先统计需要比较相似度的两篇文档的总字数,其次分别统计文档中共有词语的总字符数,第三用共有词语除以最长文档的字数得到相似度衡量的数值。
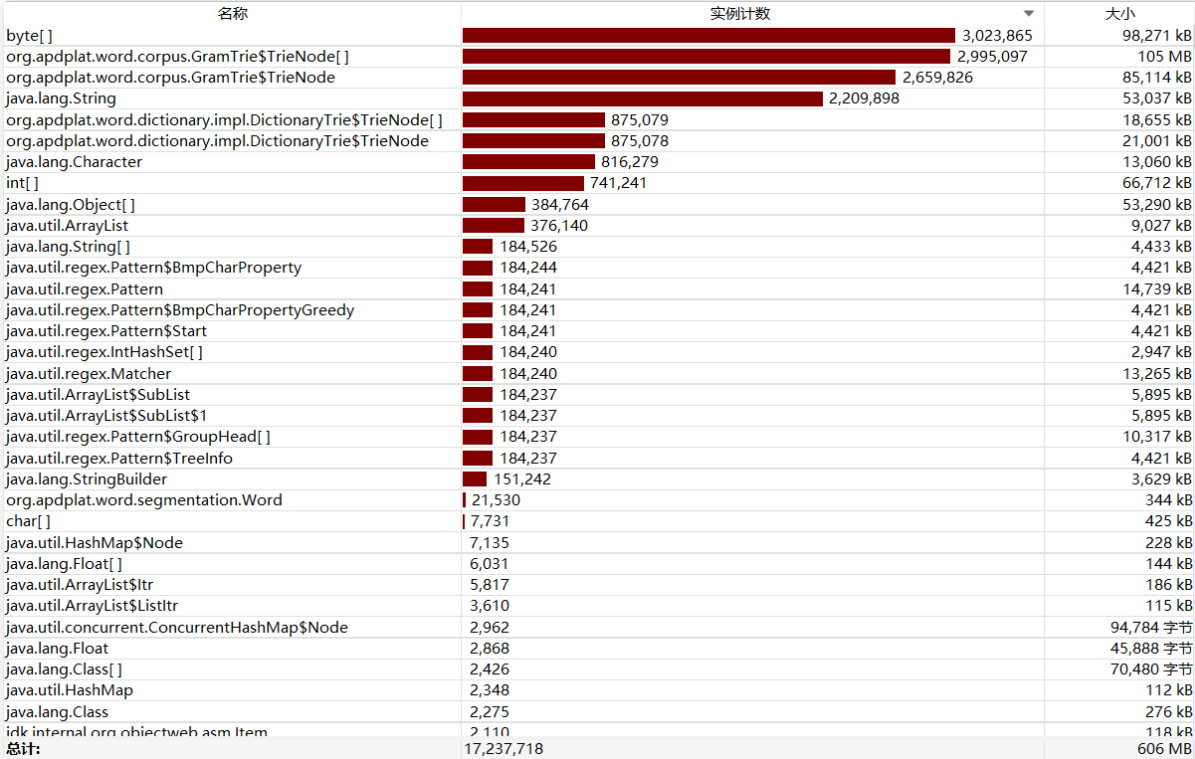
(3)计算模块接口部分的性能改进 - 第一版程序耗时相当多,需要将近40秒的运行时间

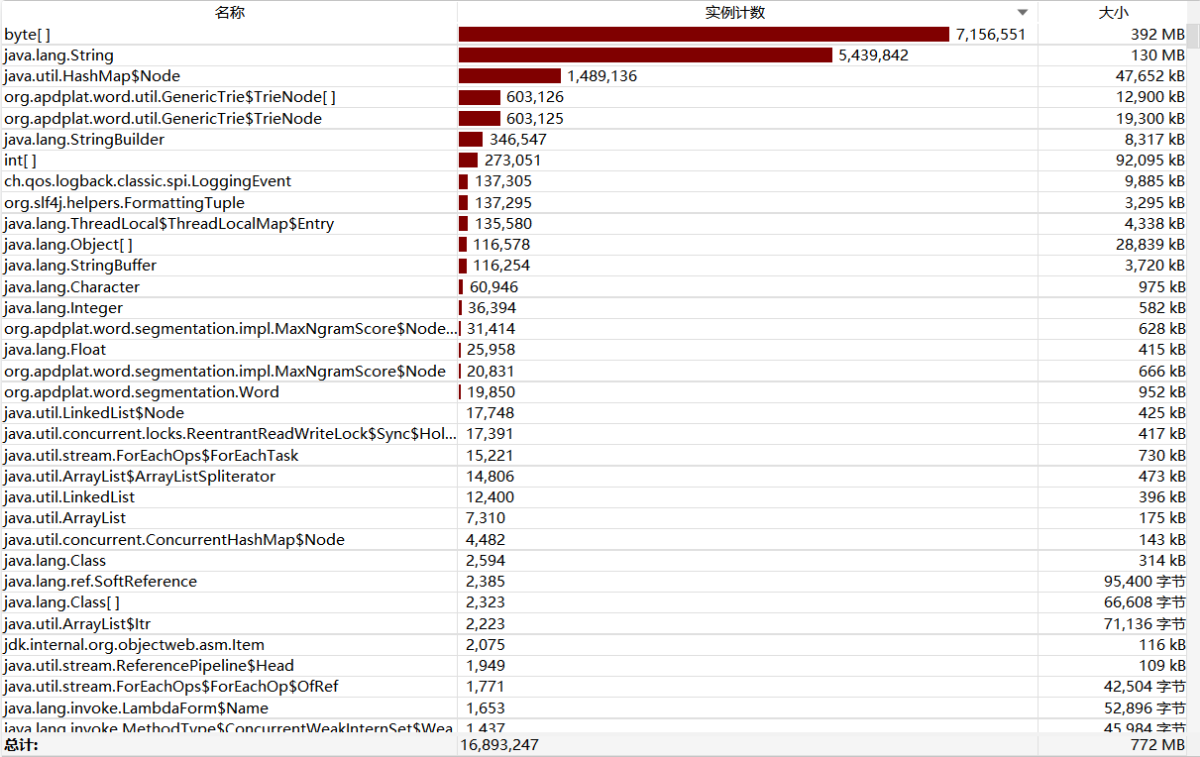
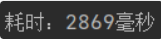
- 第二版程序将依赖中的分词器版本下调到1.2,运行速度明显提升很多


- 第三版禁用了日志输出,输出时间再次减少
4. 计算模块部分单元测试展示
(1)CuttingWordsUtil类测试
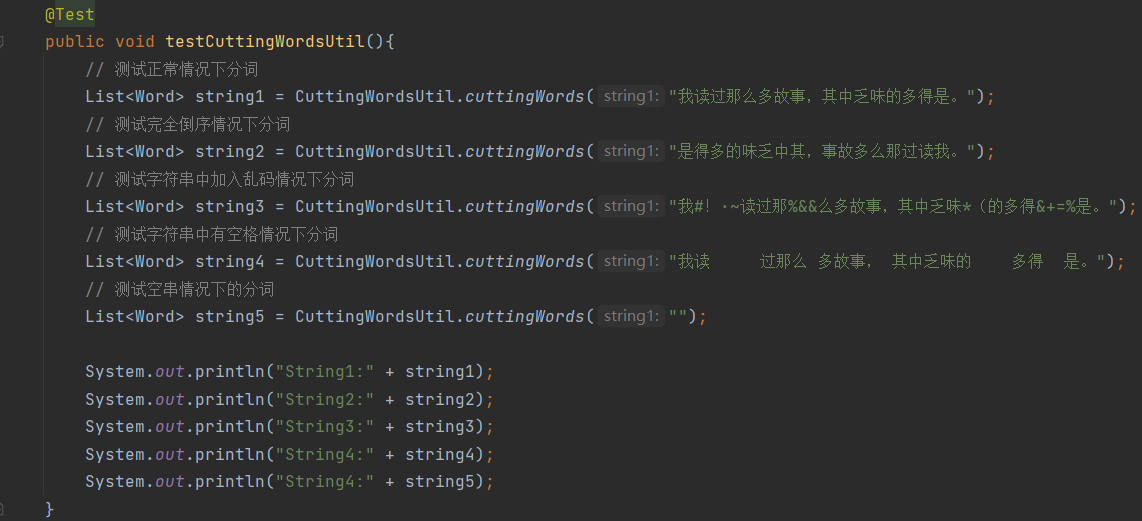
测试结果:

可以看出,word分词器可以识别一些特殊符号并同样划分出来
(2)SimpleCommonWords类测试
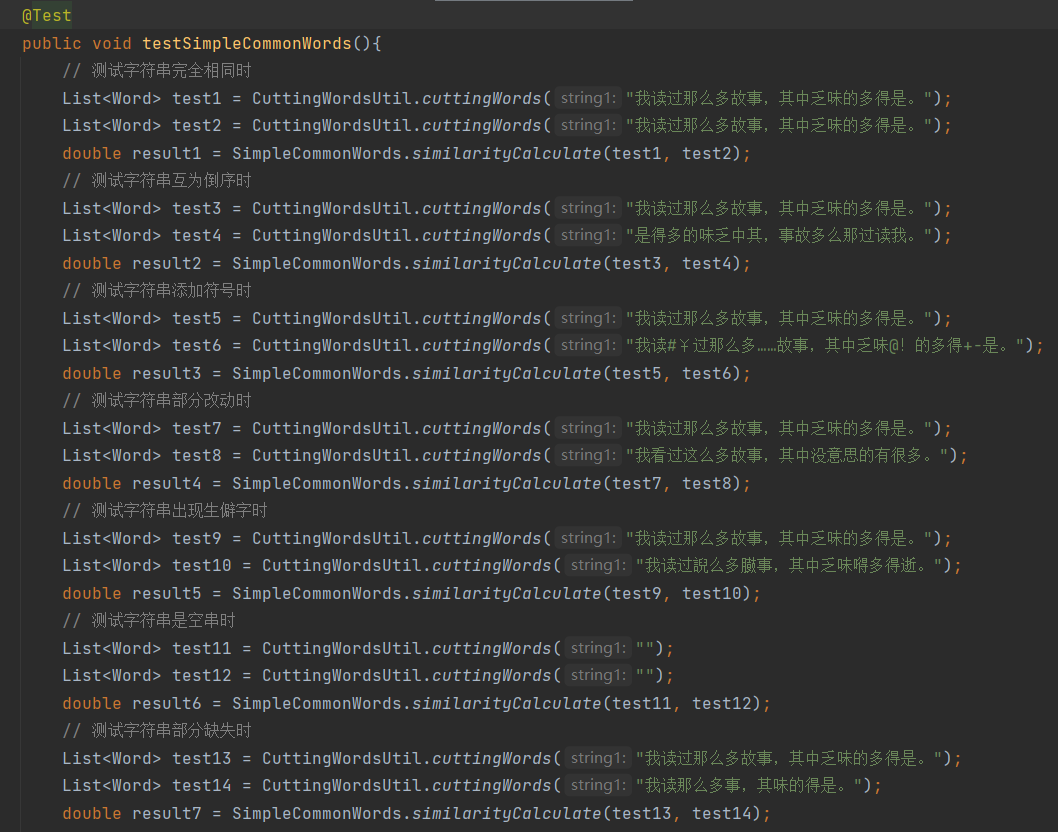
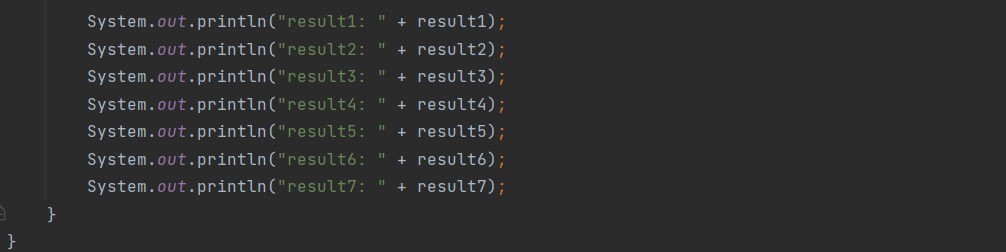
测试结果:
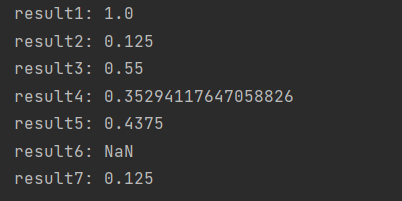
当两个句子为空串时,输出为NaN,需要做异常处理
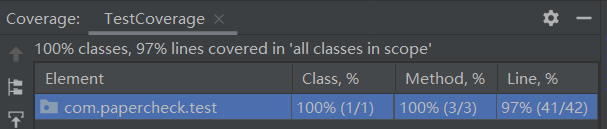
(3)代码覆盖率
5. 模块部分异常处理说明
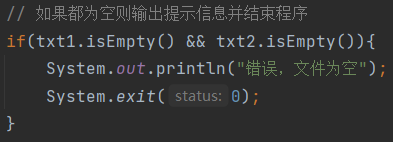
在单元测试模块中可以知道,当两个字符串为空串时输出NaN,需要进行异常处理
在Application类中添加判断,如果都为空则输出提示信息并结束程序
github仓库