| 软件工程 | https://edu.cnblogs.com/campus/gdgy/CSGrade21-34 |
|---|---|
| 作业要求 | 设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率 |
| GitHub链接 | https://github.com/jinzhanjun625/jinzhanjun625/tree/main/第一次软工作业 |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 10 |
| · Estimate | 估计这个任务需要多少时间 | 10 | 15 |
| Development | 开发 | 120 | 150 |
| · Analysis | 需求分析 (包括学习新技术) | 7 | 20 |
| · Design Spec | 生成设计文档 | 13 | 8 |
| · Design Review | 设计复审 | 9 | 10 |
| · Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 3 | 3 |
| · Design | 具体设计 | 10 | 8 |
| · Coding | 具体编码 | 50 | 60 |
| · Code Review | 代码复审 | 5 | 3 |
| · Test | 测试(自我测试,修改代码,提交修改) | 30 | 30 |
| Reporting | 报告 | 20 | 36 |
| · Test Report | 测试报告 | 20 | 35 |
| · Size Measurement | 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 10 |
| 合计 | 187 | 233 |
实现流程图
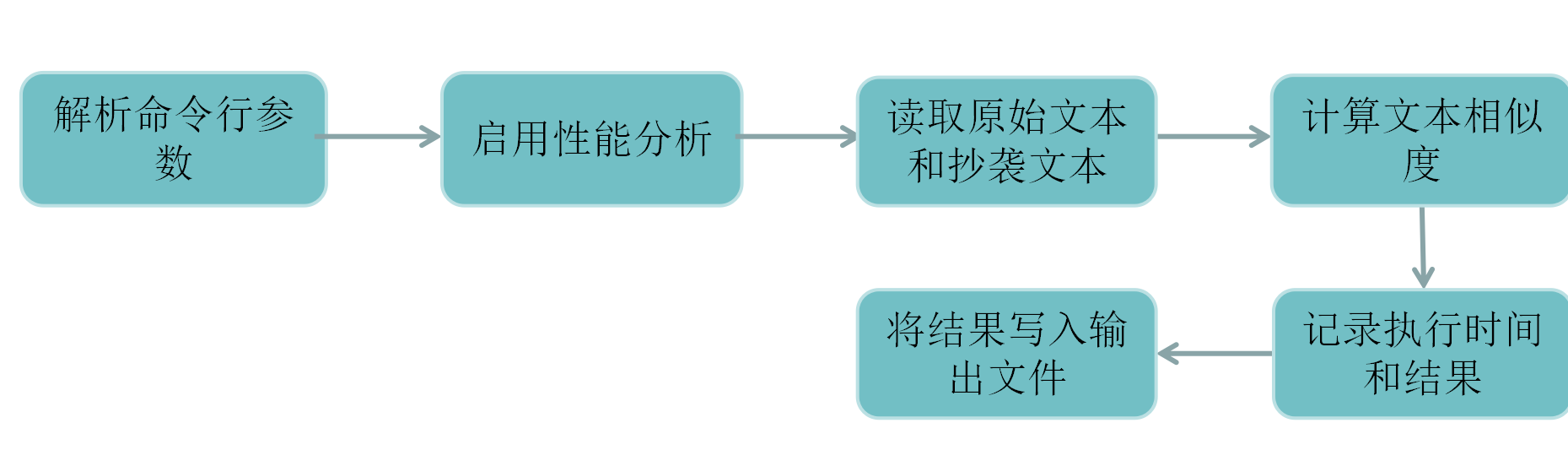
代码实现
导入difflib库用于计算文本相似度
import sys
import difflib
import re
import string
import argparse
import logging
从文件读取文本内容
def read_file(file_path):
try:
with open(file_path, 'r', encoding='utf-8') as file:
text = file.read()
return text
except FileNotFoundError:
logging.error(f"File not found: {file_path}")
sys.exit(1)
except Exception as e:
logging.error(f"Error reading file: {str(e)}")
sys.exit(1)
清理文本,去除标点符号和将文本转换为小写
def clean_text(text):
text = re.sub(f"[{string.punctuation}]", '', text)
text = text.lower()
return text
使用difflib库的SequenceMatcher来计算相似性
original_text = clean_text(original_text)
plagiarized_text = clean_text(plagiarized_text)
similarity = difflib.SequenceMatcher(None, original_text, plagiarized_text).ratio()
return round(similarity, 4)
主函数
def main():
# 创建命令行参数解析器
parser = argparse.ArgumentParser(description="Check plagiarism between two text files")
parser.add_argument("original_file_path", type=str, help="Path to the original text file")
parser.add_argument("plagiarized_file_path", type=str, help="Path to the plagiarized text file")
parser.add_argument("output_file_path", type=str, help="Path to the output file")
args = parser.parse_args()
# 从文件读取原始文本和抄袭文本
original_text = read_file(args.original_file_path)
plagiarized_text = read_file(args.plagiarized_file_path)
# 计算文本相似度
similarity = calculate_similarity(original_text, plagiarized_text)
# 将相似度写入输出文件
with open(args.output_file_path, 'w', encoding='utf-8') as output_file:
output_file.write(f"{similarity:.2f}\n")
设置日志级别为INFO
if __name__ == "__main__":
logging.basicConfig(level=logging.INFO)
main()
命令行参数
python main.py C:\Users\jzj\Desktop\SE\org.txt C:\Users\jzj\Desktop\SE\org_add.txt C:\Users\jzj\Desktop\SE\ans.txt
运行结果

从上图中可以看出运行时间为0.16s且查重率达到91%,性能较为突出,
性能分析图
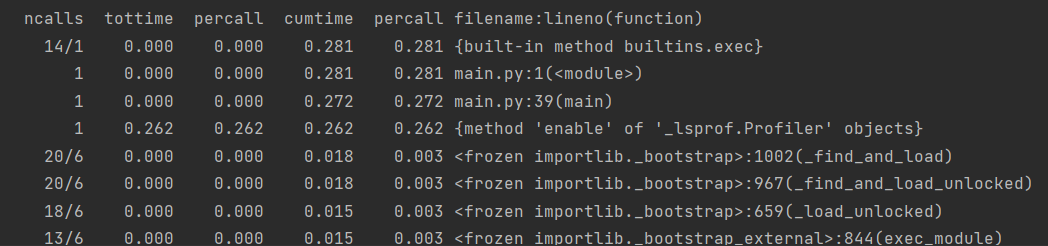
从cumtime(函数的总运行时间,包括所有子函数调用的时间)来看,性能占比最大的是Python 内置函数 ‘exec’。针对该问题,一个好的优化方法是引入一个缓存机制,将函数的输入参数与计算结果进行关联并存储在内存中。下次函数被调用时,首先检查输入参数是否在缓存中,如果是,则直接返回缓存中的结果,而不进行重复计算。这可以大大减少函数的运行时间,特别是在重复调用的情况下。因此增添了以下代码段:
import functools
# 使用functools.lru_cache装饰器创建缓存
@functools.lru_cache(maxsize=None) # 设置为None表示缓存无限大
def expensive_function(input_data):
# 在这里进行耗时计算
result = perform_expensive_calculation(input_data)
return result
# 调用函数时,自动使用缓存
result1 = expensive_function(input1)
result2 = expensive_function(input2)
代码覆盖率
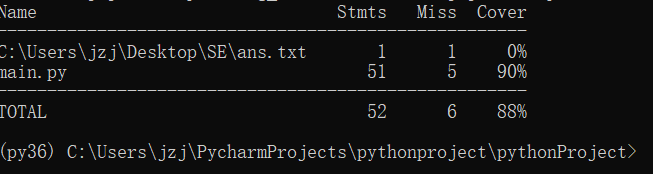
经过测试,代码覆盖率达到90%,总体覆盖率可达88%
异常处理
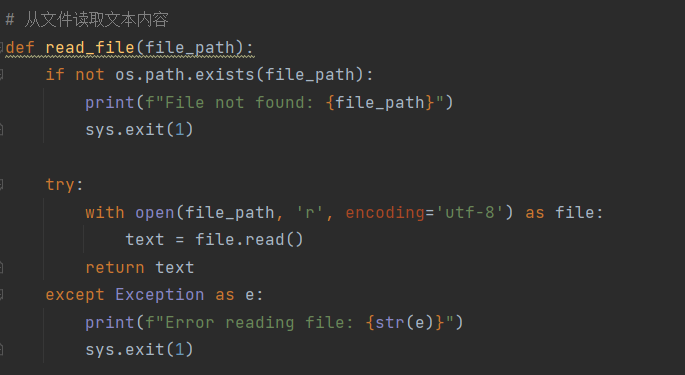
读取指定文件路径时,需要对文件路径是否正确进行判断并做出响应,所以读取指定文件内容之前要先判断文件是否存在,假如所需文件不存在则需要告知用户并指出相应报错原因。在此处使用os.path.exists判断目标文件是否存在
后续优化点
1.错误处理和异常处理:增加更全面的错误处理,处理各种可能出现的异常情况,确保程序的健壮性。提供有用的错误消息,以帮助用户诊断问题。
2.日志记录:添加日志记录以便更容易追踪程序的运行和调试。使用日志级别来控制日志的详细程度,以方便排除问题。
3.命令行参数解析:使用命令行参数解析库argparse来更清晰地解析命令行参数,提供更多的灵活性和错误处理功能。
4.性能分析:使用性能分析工具(如cProfile)来识别代码中的性能瓶颈。