******作业一 **
要求:用REQUESTS和BEAUTIFULSOUP库方法定向爬取给定网址(HTTP://WWW.SHANGHAIRANKING.CN/RANKINGS/BCUR/2020)的数据,屏幕打印爬取的大学排名信息。
输出信息:
排名 学校名称 省市 学校类型 总分
1 清华大学 北京 综合 852.5****
import urllib.request
from bs4 import BeautifulSoup
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.76'
}
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read().decode()
soup = BeautifulSoup(data, "lxml")
fp = open("./程序设计.txt", "w", encoding='utf-8')
fp.write("排名 学校名称 省市 学校类型 总分\n")
body = soup.find("tbody")
for i, row in enumerate(body.find_all('tr')):
if i >= 24: # 输出前24条
break
row_data=[]
for td in row.find_all('td'):
row_data.append(td.get_text(strip=True))
print(row_data)
fp.write(row_data[0]+" "+row_data[1][0:4]+" "+
row_data[2]+" "+row_data[3]+" "+row_data[4]+ "\n")
fp.close()
print("任务完成")
运行结果:

心得体会:
深深体会到了python爬虫的魅力,对bs4有了进一步的了解,变得更加熟练了
作业二
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
import requests
import re
if __name__=="__main__":
url="http://search.dangdang.com/?key=%CA%E9%B0%FC&act=input"
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.36'
}
response=requests.get(url=url,headers=headers).text
ex='<p class="name" name="title" ><a title="(.*?)"'
ey='<span class="price_n">¥(.*?)</span>'
ls1=re.findall(ex,response,re.S)
ls2=re.findall(ey,response,re.S)
print("序号 价格 商品名")
for i in range(0,len(ls1)):
print(str(i+1)+" "+str(ls2[i])+" "+ls1[i])
运行结果:
心得体会:
自己对re正则表达式的应用更加熟练,掌握了如何爬取静态页面
作业三
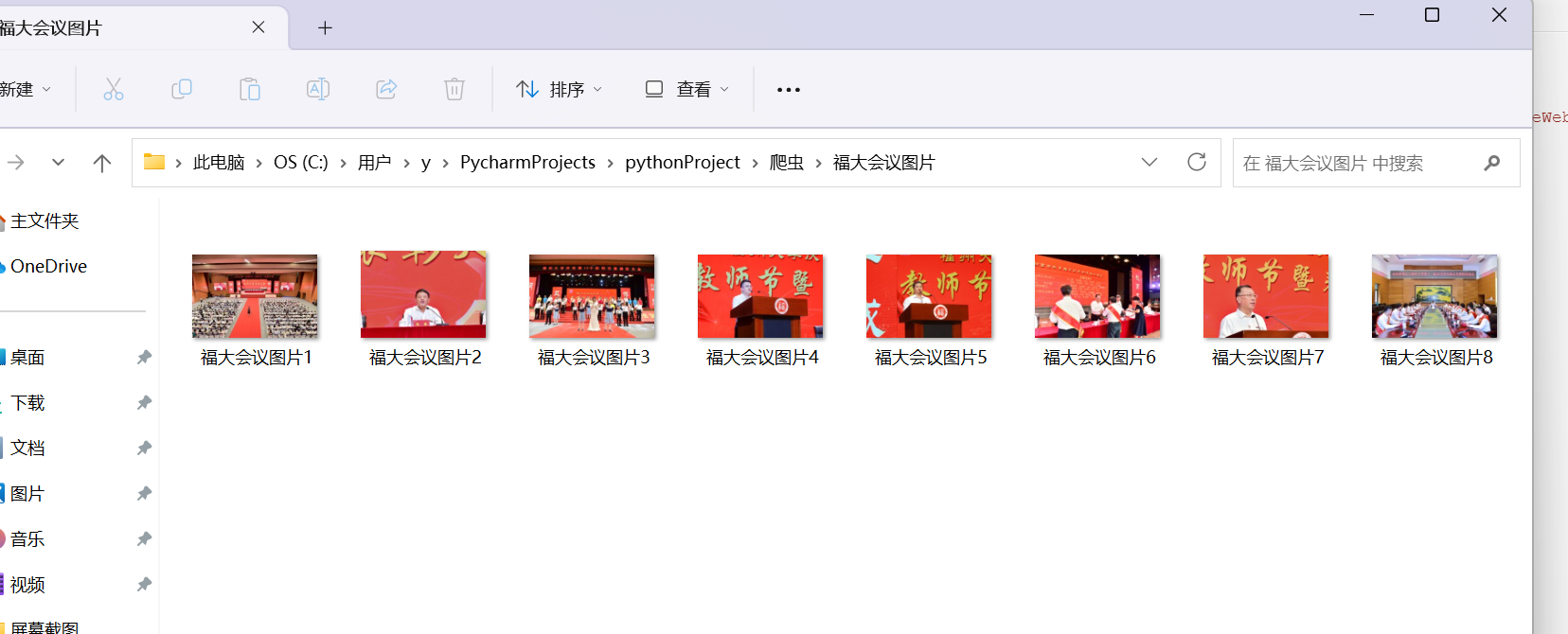
要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm )或者自选网页的所有JPEG和JPG格式文件
输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
import requests
import re
import os
if __name__=="__main__":
if not os.path.exists('福大会议图片'):
os.mkdir('福大会议图片')
url="https://xcb.fzu.edu.cn/info/1071/4481.htm"
headers={
'user-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.36'
}
response=requests.get(url=url,headers=headers)
response.encoding='utf-8'
response=response.text
ex='<img src=".*?".*?>'
ls=re.findall(ex,response,re.S)
number=1
for i in ls:
x='src="(.*?)"'
m=re.findall(x,i)[0]
newurl="https://xcb.fzu.edu.cn"+m
tupian=requests.get(url=newurl,headers=headers).content
imgpath='./福大会议图片/'+str(number)+'.jpg'
with open(imgpath, 'wb') as fp:
fp.write(tupian)
print("下载成功!")
number=number+1
fp.close()
print("任务完成")
运行结果如下:
心得体会:
加强了自己对requests的熟练度,掌握了如何运用爬虫爬取图片